 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-sensitive Spelling Correction Using Google Web 1T 5-Gram Information
Apr 26, 2012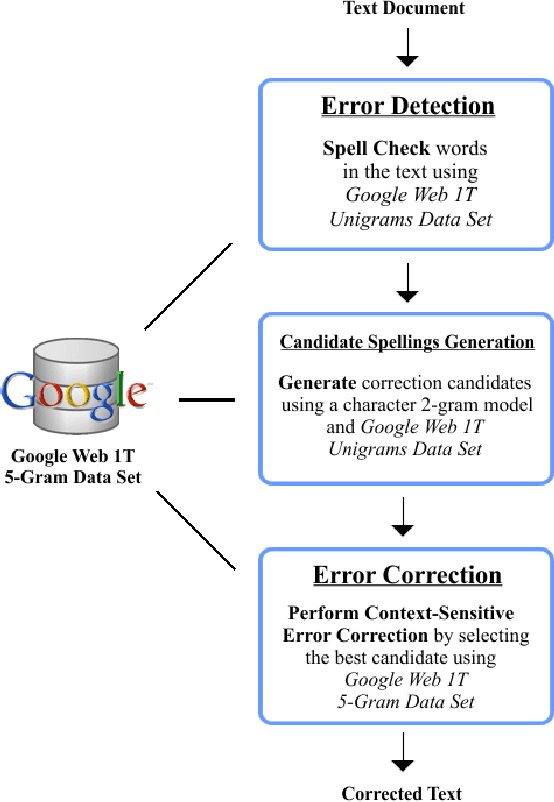

In computing, spell checking is the process of detecting and sometimes providing spelling suggestions for incorrectly spelled words in a text. Basically, a spell checker is a computer program that uses a dictionary of words to perform spell checking. The bigger the dictionary is, the higher is the error detection rate. The fact that spell checkers are based on regular dictionaries, they suffer from data sparseness problem as they cannot capture large vocabulary of words including proper names, domain-specific terms, technical jargons, special acronyms, and terminologies. As a result, they exhibit low error detection rate and often fail to catch major errors in the text. This paper proposes a new context-sensitive spelling correction method for detecting and correcting non-word and real-word errors in digital text documents. The approach hinges around data statistics from Google Web 1T 5-gram data set which consists of a big volume of n-gram word sequences, extracted from the World Wide Web. Fundamentally, the proposed method comprises an error detector that detects misspellings, a candidate spellings generator based on a character 2-gram model that generates correction suggestions, and an error corrector that performs contextual error correction. Experiments conducted on a set of text documents from different domains and containing misspellings, showed an outstanding spelling error correction rate and a drastic reduction of both non-word and real-word errors. In a further study, the proposed algorithm is to be parallelized so as to lower the computational cost of the error detection and correction processes.
* LACSC - Lebanese Association for Computational Sciences - http://www.lacsc.org
OCR Post-Processing Error Correction Algorithm using Google Online Spelling Suggestion
Apr 01, 2012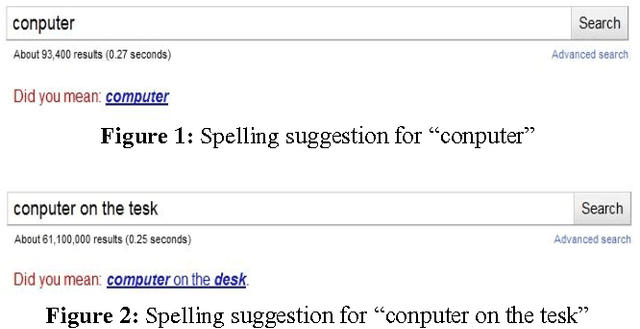

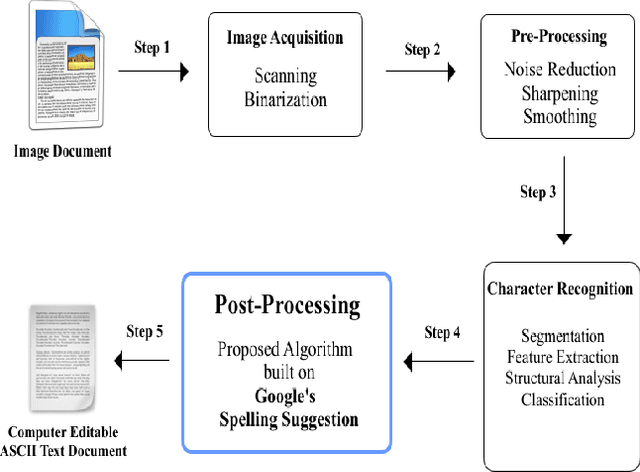
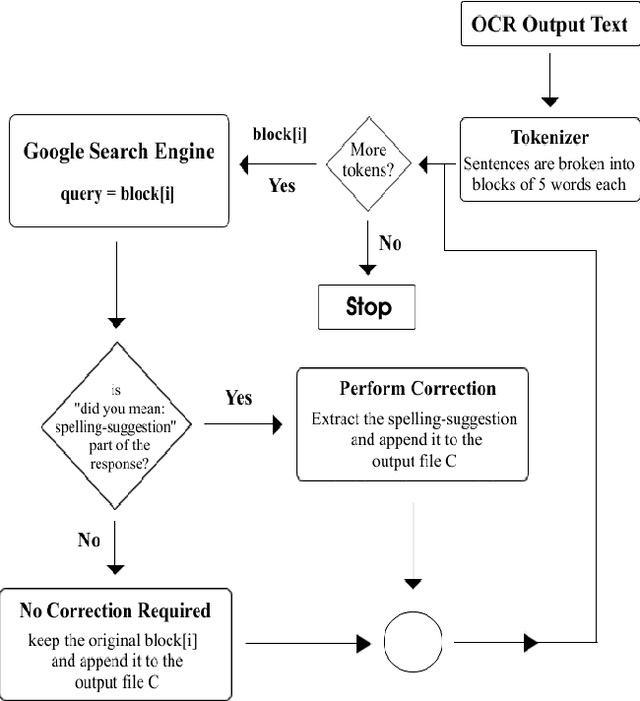
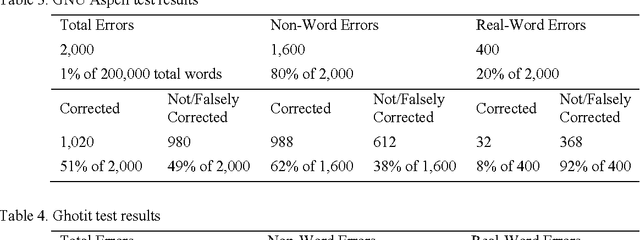
With the advent of digital optical scanners, a lot of paper-based books, textbooks, magazines, articles, and documents are being transformed into an electronic version that can be manipulated by a computer. For this purpose, OCR, short for Optical Character Recognition was developed to translate scanned graphical text into editable computer text. Unfortunately, OCR is still imperfect as it occasionally mis-recognizes letters and falsely identifies scanned text, leading to misspellings and linguistics errors in the OCR output text. This paper proposes a post-processing context-based error correction algorithm for detecting and correcting OCR non-word and real-word errors. The proposed algorithm is based on Google's online spelling suggestion which harnesses an internal database containing a huge collection of terms and word sequences gathered from all over the web, convenient to suggest possible replacements for words that have been misspelled during the OCR process. Experiments carried out revealed a significant improvement in OCR error correction rate. Future research can improve upon the proposed algorithm so much so that it can be parallelized and executed over multiprocessing platforms.
OCR Context-Sensitive Error Correction Based on Google Web 1T 5-Gram Data Set
Apr 01, 2012

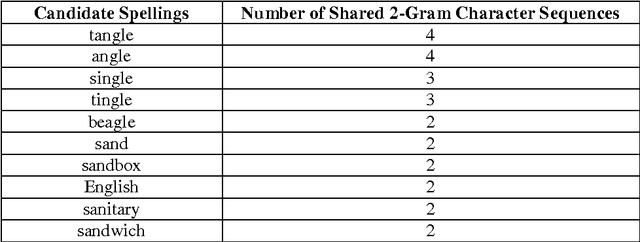
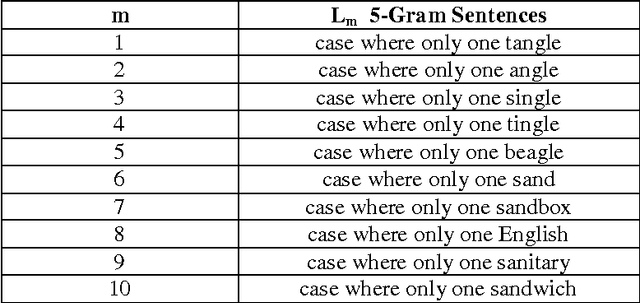
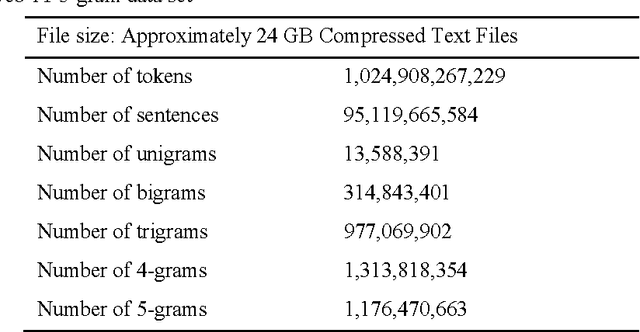
Since the dawn of the computing era, information has been represented digitally so that it can be processed by electronic computers. Paper books and documents were abundant and widely being published at that time; and hence, there was a need to convert them into digital format. OCR, short for Optical Character Recognition was conceived to translate paper-based books into digital e-books. Regrettably, OCR systems are still erroneous and inaccurate as they produce misspellings in the recognized text, especially when the source document is of low printing quality. This paper proposes a post-processing OCR context-sensitive error correction method for detecting and correcting non-word and real-word OCR errors. The cornerstone of this proposed approach is the use of Google Web 1T 5-gram data set as a dictionary of words to spell-check OCR text. The Google data set incorporates a very large vocabulary and word statistics entirely reaped from the Internet, making it a reliable source to perform dictionary-based error correction. The core of the proposed solution is a combination of three algorithms: The error detection, candidate spellings generator, and error correction algorithms, which all exploit information extracted from Google Web 1T 5-gram data set. Experiments conducted on scanned images written in different languages showed a substantial improvement in the OCR error correction rate. As future developments, the proposed algorithm is to be parallelised so as to support parallel and distributed computing architectures.
Service-Oriented Architecture for Space Exploration Robotic Rover Systems
Apr 01, 2012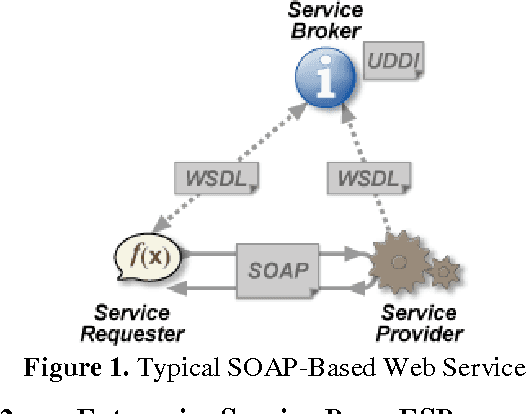
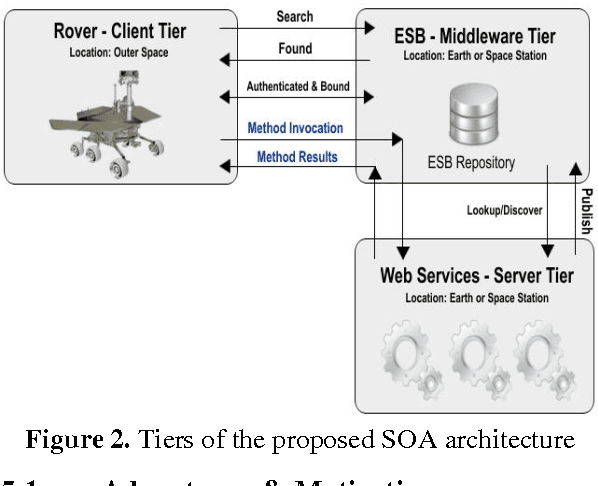
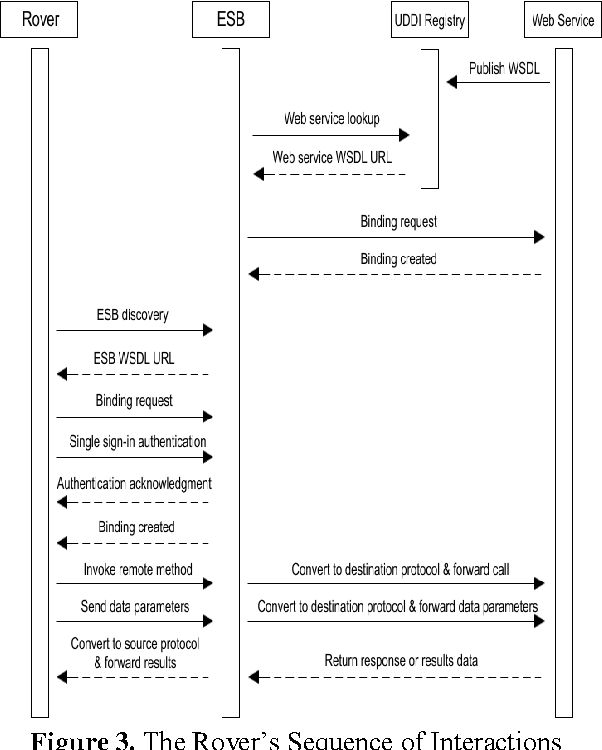
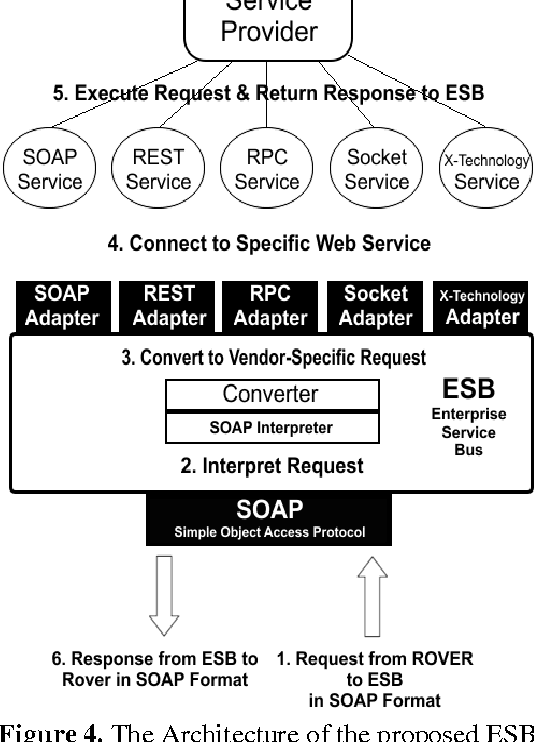
Currently, industrial sectors are transforming their business processes into e-services and component-based architectures to build flexible, robust, and scalable systems, and reduce integration-related maintenance and development costs. Robotics is yet another promising and fast-growing industry that deals with the creation of machines that operate in an autonomous fashion and serve for various applications including space exploration, weaponry, laboratory research, and manufacturing. It is in space exploration that the most common type of robots is the planetary rover which moves across the surface of a planet and conducts a thorough geological study of the celestial surface. This type of rover system is still ad-hoc in that it incorporates its software into its core hardware making the whole system cohesive, tightly-coupled, more susceptible to shortcomings, less flexible, hard to be scaled and maintained, and impossible to be adapted to other purposes. This paper proposes a service-oriented architecture for space exploration robotic rover systems made out of loosely-coupled and distributed web services. The proposed architecture consists of three elementary tiers: the client tier that corresponds to the actual rover; the server tier that corresponds to the web services; and the middleware tier that corresponds to an Enterprise Service Bus which promotes interoperability between the interconnected entities. The niche of this architecture is that rover's software components are decoupled and isolated from the rover's body and possibly deployed at a distant location. A service-oriented architecture promotes integrate-ability, scalability, reusability, maintainability, and interoperability for client-to-server communication.
Parallel Spell-Checking Algorithm Based on Yahoo! N-Grams Dataset
Apr 01, 2012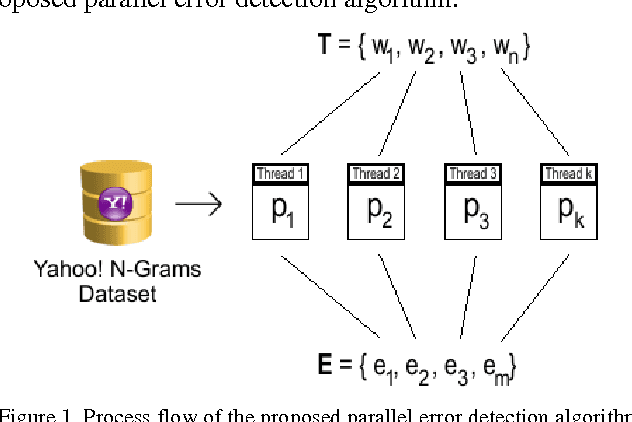

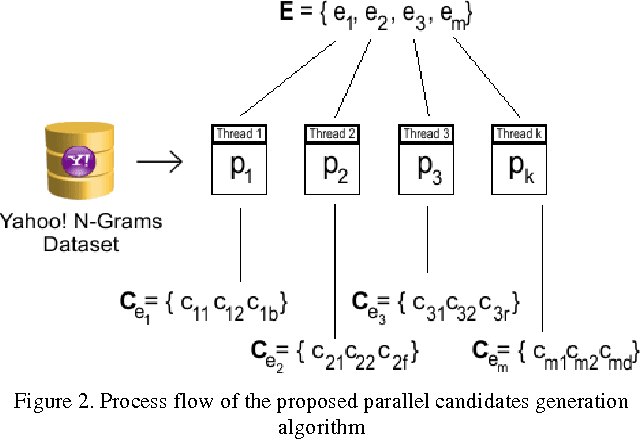
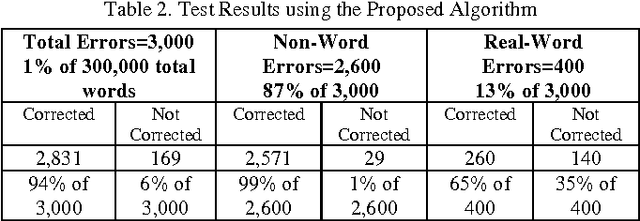
Spell-checking is the process of detecting and sometimes providing suggestions for incorrectly spelled words in a text. Basically, the larger the dictionary of a spell-checker is, the higher is the error detection rate; otherwise, misspellings would pass undetected. Unfortunately, traditional dictionaries suffer from out-of-vocabulary and data sparseness problems as they do not encompass large vocabulary of words indispensable to cover proper names, domain-specific terms, technical jargons, special acronyms, and terminologies. As a result, spell-checkers will incur low error detection and correction rate and will fail to flag all errors in the text. This paper proposes a new parallel shared-memory spell-checking algorithm that uses rich real-world word statistics from Yahoo! N-Grams Dataset to correct non-word and real-word errors in computer text. Essentially, the proposed algorithm can be divided into three sub-algorithms that run in a parallel fashion: The error detection algorithm that detects misspellings, the candidates generation algorithm that generates correction suggestions, and the error correction algorithm that performs contextual error correction. Experiments conducted on a set of text articles containing misspellings, showed a remarkable spelling error correction rate that resulted in a radical reduction of both non-word and real-word errors in electronic text. In a further study, the proposed algorithm is to be optimized for message-passing systems so as to become more flexible and less costly to scale over distributed machines.
Neural Network Model for Path-Planning of Robotic Rover Systems
Apr 01, 2012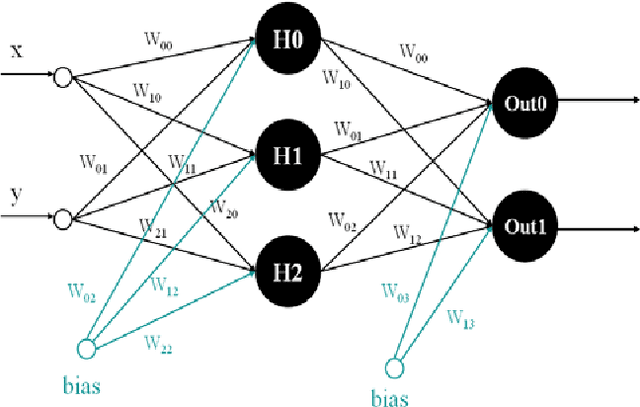
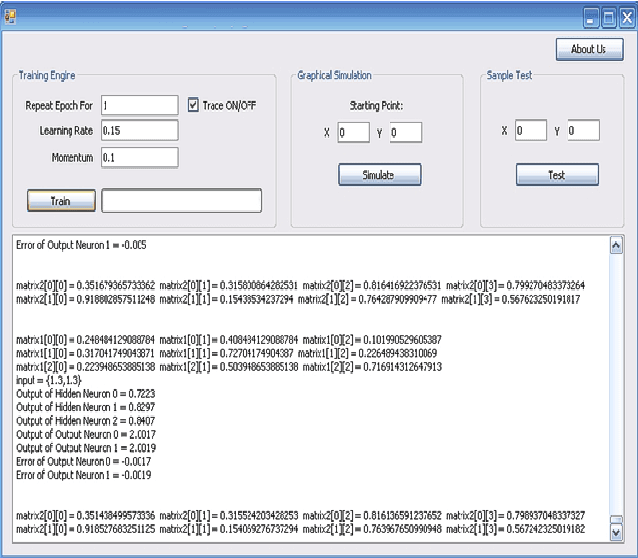
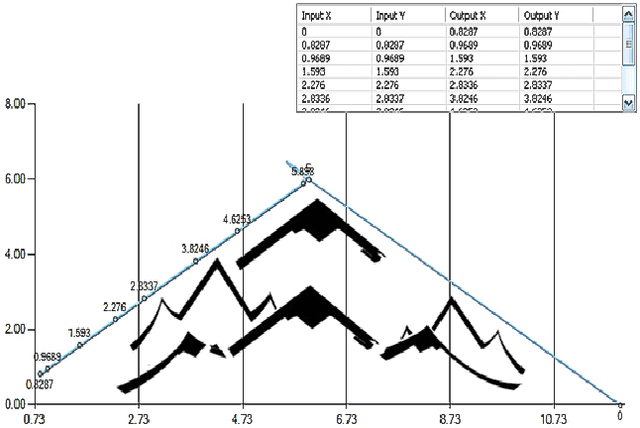
Today, robotics is an auspicious and fast-growing branch of technology that involves the manufacturing, design, and maintenance of robot machines that can operate in an autonomous fashion and can be used in a wide variety of applications including space exploration, weaponry, household, and transportation. More particularly, in space applications, a common type of robots has been of widespread use in the recent years. It is called planetary rover which is a robot vehicle that moves across the surface of a planet and conducts detailed geological studies pertaining to the properties of the landing cosmic environment. However, rovers are always impeded by obstacles along the traveling path which can destabilize the rover's body and prevent it from reaching its goal destination. This paper proposes an ANN model that allows rover systems to carry out autonomous path-planning to successfully navigate through challenging planetary terrains and follow their goal location while avoiding dangerous obstacles. The proposed ANN is a multilayer network made out of three layers: an input, a hidden, and an output layer. The network is trained in offline mode using back-propagation supervised learning algorithm. A software-simulated rover was experimented and it revealed that it was able to follow the safest trajectory despite existing obstacles. As future work, the proposed ANN is to be parallelized so as to speed-up the execution time of the training process.
Expert PC Troubleshooter With Fuzzy-Logic And Self-Learning Support
Apr 01, 2012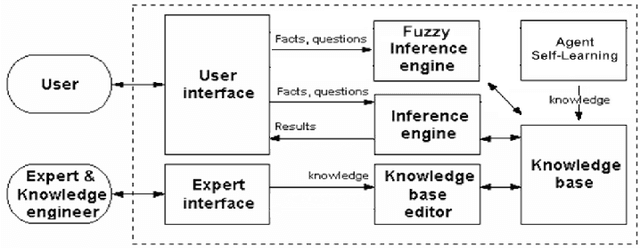
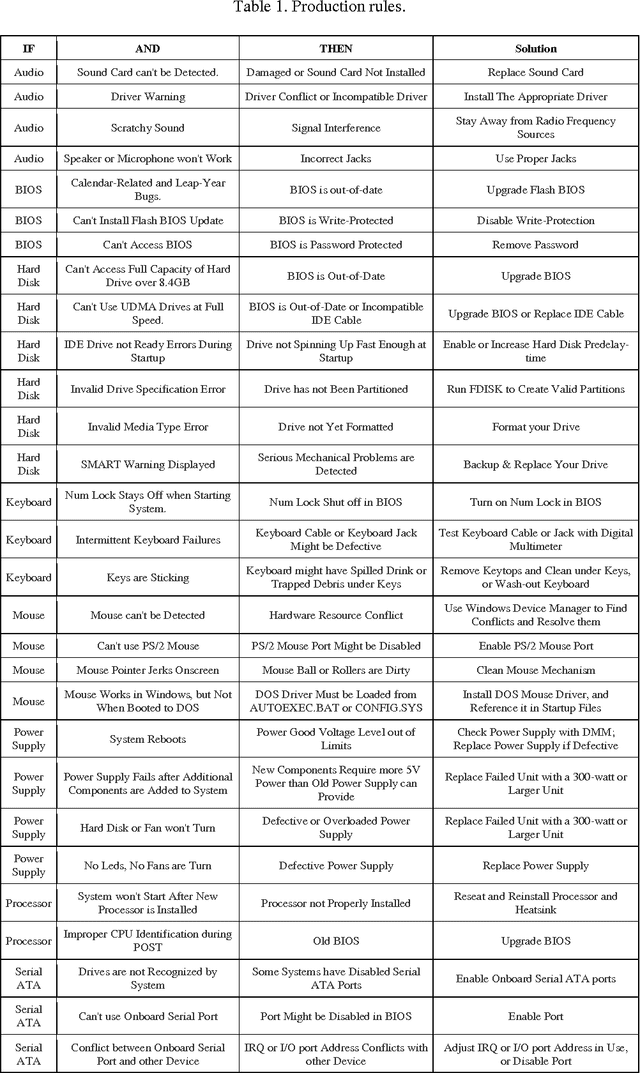
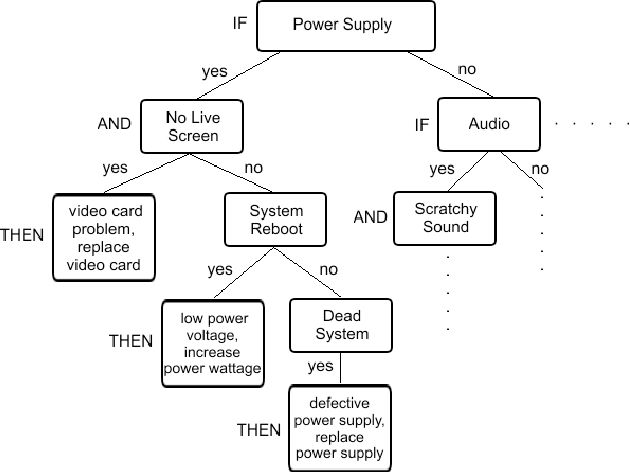
Expert systems use human knowledge often stored as rules within the computer to solve problems that generally would entail human intelligence. Today, with information systems turning out to be more pervasive and with the myriad advances in information technologies, automating computer fault diagnosis is becoming so fundamental that soon every enterprise has to endorse it. This paper proposes an expert system called Expert PC Troubleshooter for diagnosing computer problems. The system is composed of a user interface, a rule-base, an inference engine, and an expert interface. Additionally, the system features a fuzzy-logic module to troubleshoot POST beep errors, and an intelligent agent that assists in the knowledge acquisition process. The proposed system is meant to automate the maintenance, repair, and operations (MRO) process, and free-up human technicians from manually performing routine, laborious, and timeconsuming maintenance tasks. As future work, the proposed system is to be parallelized so as to boost its performance and speed-up its various operations.
Service-Oriented Architecture for Weaponry and Battle Command and Control Systems in Warfighting
Apr 01, 2012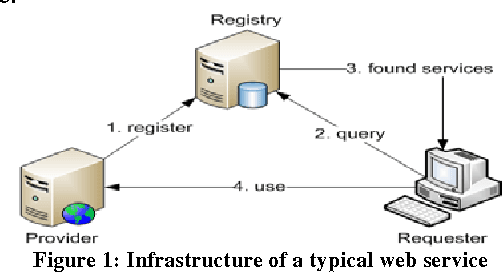
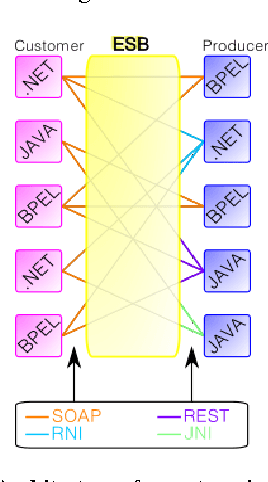
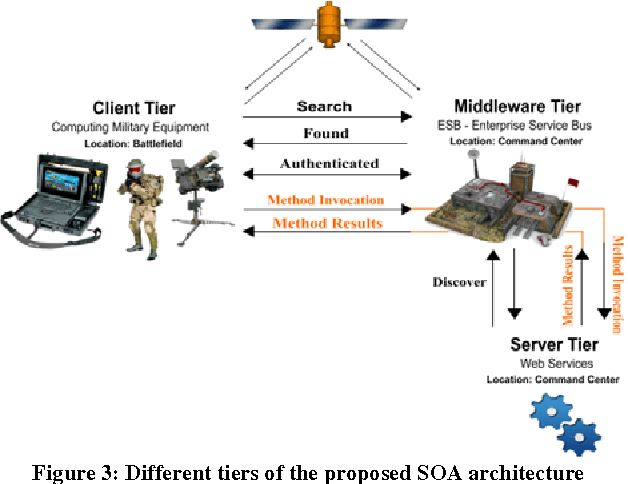
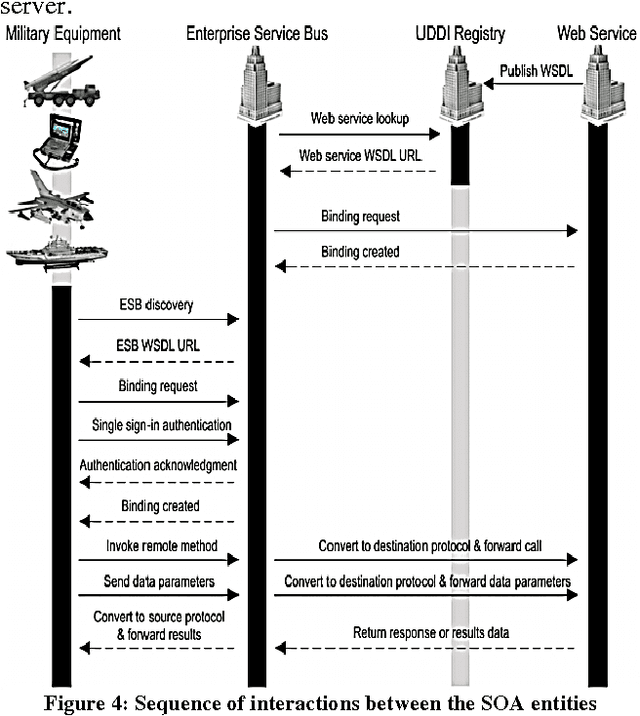
Military is one of many industries that is more computer-dependent than ever before, from soldiers with computerized weapons, and tactical wireless devices, to commanders with advanced battle management, command and control systems. Fundamentally, command and control is the process of planning, monitoring, and commanding military personnel, weaponry equipment, and combating vehicles to execute military missions. In fact, command and control systems are revolutionizing as war fighting is changing into cyber, technology, information, and unmanned warfare. As a result, a new design model that supports scalability, reusability, maintainability, survivability, and interoperability is needed to allow commanders, hundreds of miles away from the battlefield, to plan, monitor, evaluate, and control the war events in a dynamic, robust, agile, and reliable manner. This paper proposes a service-oriented architecture for weaponry and battle command and control systems, made out of loosely-coupled and distributed web services. The proposed architecture consists of three elementary tiers: the client tier that corresponds to any computing military equipment; the server tier that corresponds to the web services that deliver the basic functionalities for the client tier; and the middleware tier that corresponds to an enterprise service bus that promotes interoperability between all the interconnected entities. A command and control system was simulated and experimented and it successfully exhibited the desired features of SOA. Future research can improve upon the proposed architecture so much so that it supports encryption for securing the exchange of data between the various communicating entities of the system.
ASR Context-Sensitive Error Correction Based on Microsoft N-Gram Dataset
Mar 23, 2012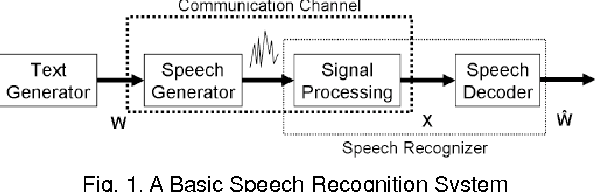

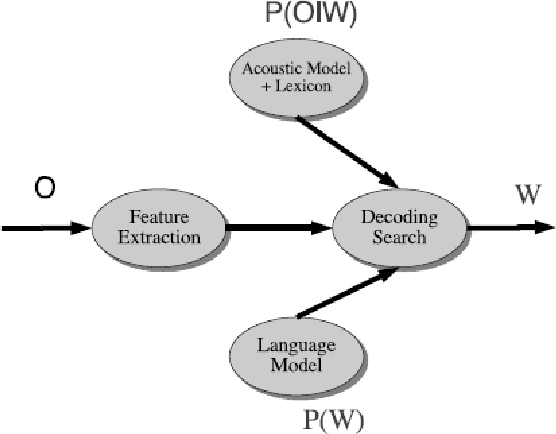
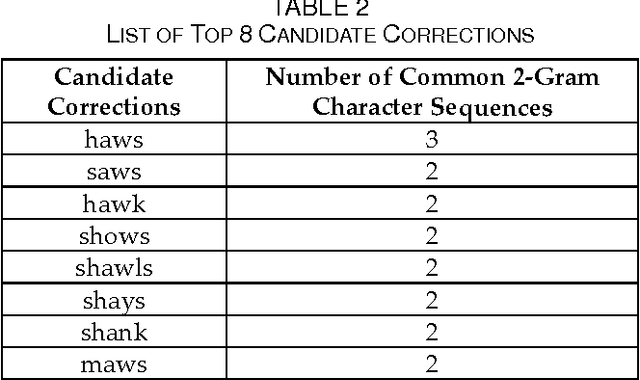
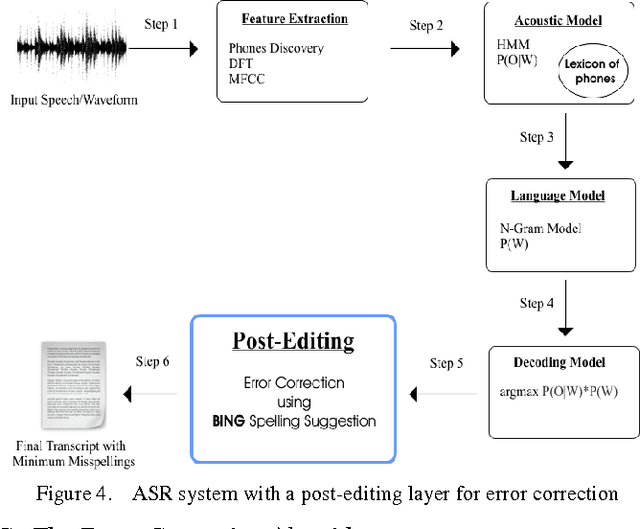
At the present time, computers are employed to solve complex tasks and problems ranging from simple calculations to intensive digital image processing and intricate algorithmic optimization problems to computationally-demanding weather forecasting problems. ASR short for Automatic Speech Recognition is yet another type of computational problem whose purpose is to recognize human spoken speech and convert it into text that can be processed by a computer. Despite that ASR has many versatile and pervasive real-world applications,it is still relatively erroneous and not perfectly solved as it is prone to produce spelling errors in the recognized text, especially if the ASR system is operating in a noisy environment, its vocabulary size is limited, and its input speech is of bad or low quality. This paper proposes a post-editing ASR error correction method based on MicrosoftN-Gram dataset for detecting and correcting spelling errors generated by ASR systems. The proposed method comprises an error detection algorithm for detecting word errors; a candidate corrections generation algorithm for generating correction suggestions for the detected word errors; and a context-sensitive error correction algorithm for selecting the best candidate for correction. The virtue of using the Microsoft N-Gram dataset is that it contains real-world data and word sequences extracted from the web which canmimica comprehensive dictionary of words having a large and all-inclusive vocabulary. Experiments conducted on numerous speeches, performed by different speakers, showed a remarkable reduction in ASR errors. Future research can improve upon the proposed algorithm so much so that it can be parallelized to take advantage of multiprocessor and distributed systems.
* LACSC - Lebanese Association for Computational Sciences - http://www.lacsc.org
Post-Editing Error Correction Algorithm for Speech Recognition using Bing Spelling Suggestion
Mar 23, 2012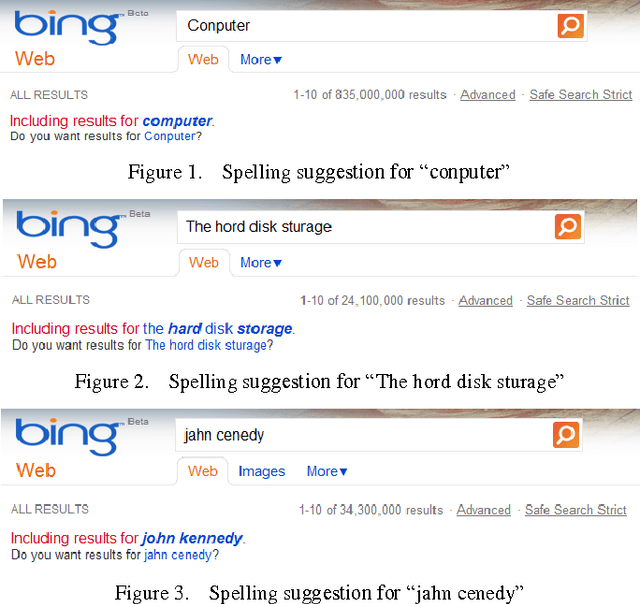
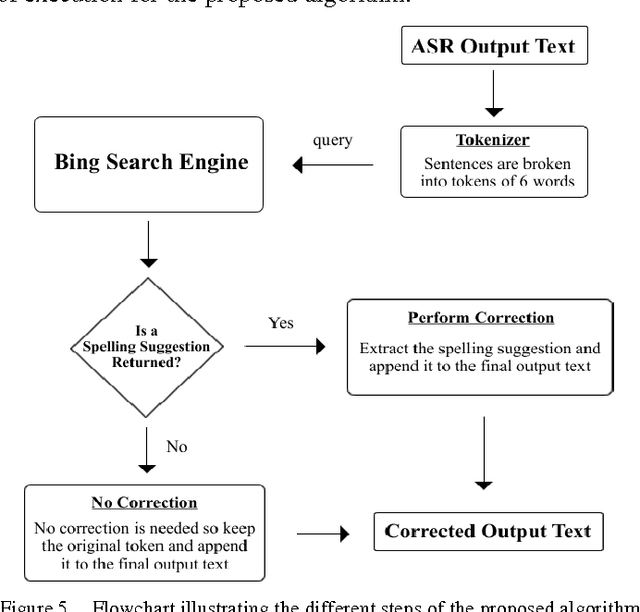
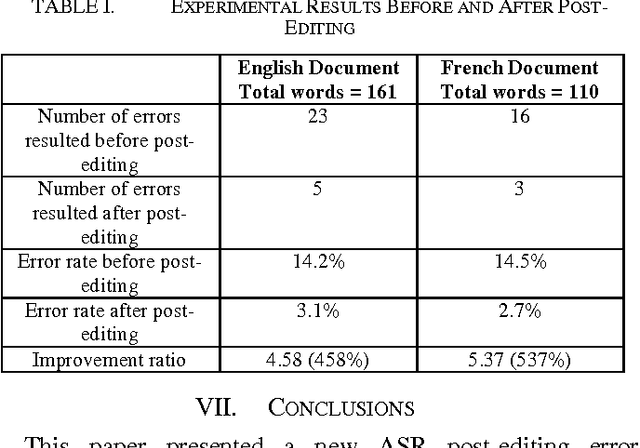
ASR short for Automatic Speech Recognition is the process of converting a spoken speech into text that can be manipulated by a computer. Although ASR has several applications, it is still erroneous and imprecise especially if used in a harsh surrounding wherein the input speech is of low quality. This paper proposes a post-editing ASR error correction method and algorithm based on Bing's online spelling suggestion. In this approach, the ASR recognized output text is spell-checked using Bing's spelling suggestion technology to detect and correct misrecognized words. More specifically, the proposed algorithm breaks down the ASR output text into several word-tokens that are submitted as search queries to Bing search engine. A returned spelling suggestion implies that a query is misspelled; and thus it is replaced by the suggested correction; otherwise, no correction is performed and the algorithm continues with the next token until all tokens get validated. Experiments carried out on various speeches in different languages indicated a successful decrease in the number of ASR errors and an improvement in the overall error correction rate. Future research can improve upon the proposed algorithm so much so that it can be parallelized to take advantage of multiprocessor computers.
* LACSC - Lebanese Association for Computational Sciences - http://www.lacsc.org