 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-sensitive Spelling Correction Using Google Web 1T 5-Gram Information
Apr 26, 2012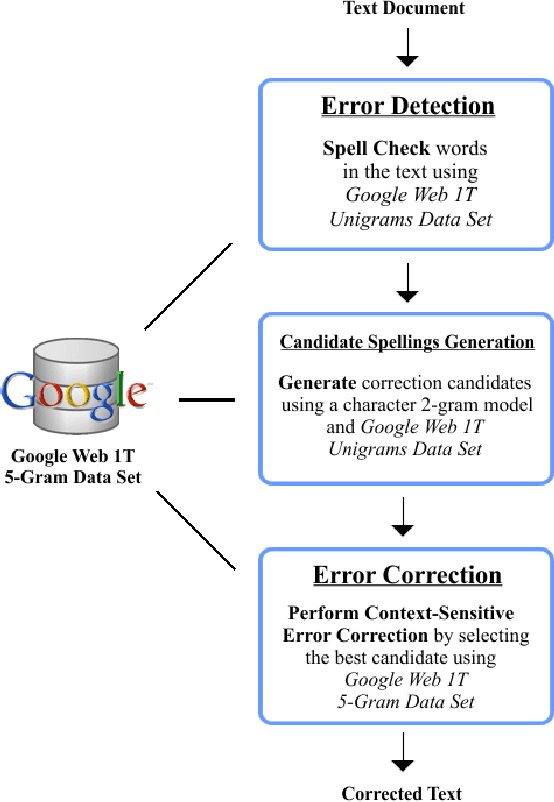
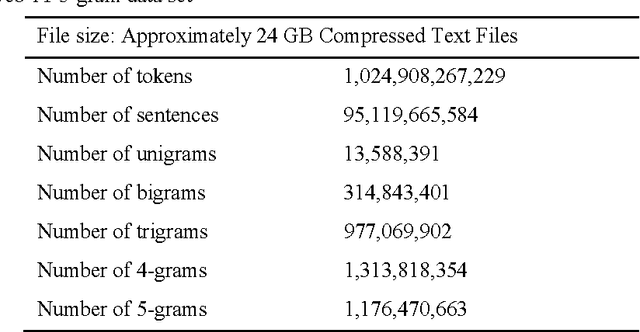

In computing, spell checking is the process of detecting and sometimes providing spelling suggestions for incorrectly spelled words in a text. Basically, a spell checker is a computer program that uses a dictionary of words to perform spell checking. The bigger the dictionary is, the higher is the error detection rate. The fact that spell checkers are based on regular dictionaries, they suffer from data sparseness problem as they cannot capture large vocabulary of words including proper names, domain-specific terms, technical jargons, special acronyms, and terminologies. As a result, they exhibit low error detection rate and often fail to catch major errors in the text. This paper proposes a new context-sensitive spelling correction method for detecting and correcting non-word and real-word errors in digital text documents. The approach hinges around data statistics from Google Web 1T 5-gram data set which consists of a big volume of n-gram word sequences, extracted from the World Wide Web. Fundamentally, the proposed method comprises an error detector that detects misspellings, a candidate spellings generator based on a character 2-gram model that generates correction suggestions, and an error corrector that performs contextual error correction. Experiments conducted on a set of text documents from different domains and containing misspellings, showed an outstanding spelling error correction rate and a drastic reduction of both non-word and real-word errors. In a further study, the proposed algorithm is to be parallelized so as to lower the computational cost of the error detection and correction processes.
* LACSC - Lebanese Association for Computational Sciences - http://www.lacsc.org
OCR Post-Processing Error Correction Algorithm using Google Online Spelling Suggestion
Apr 01, 2012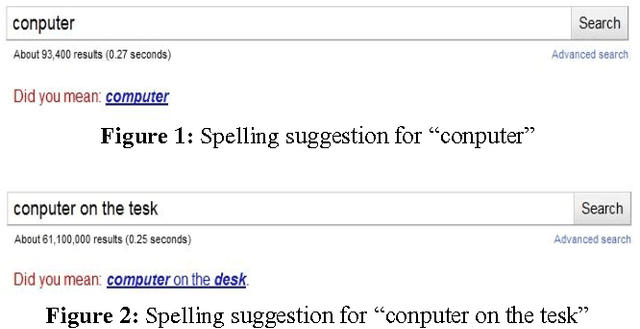

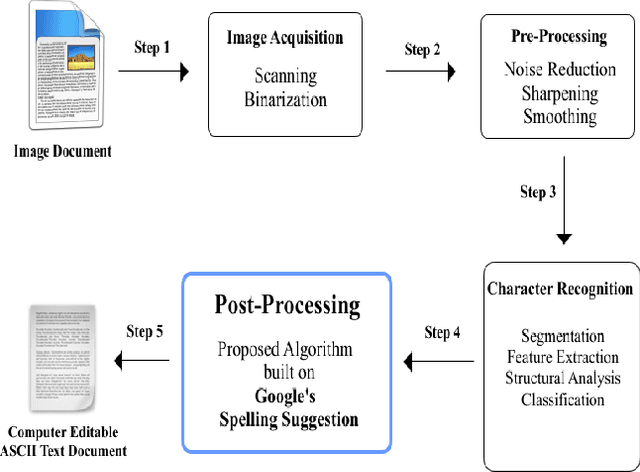
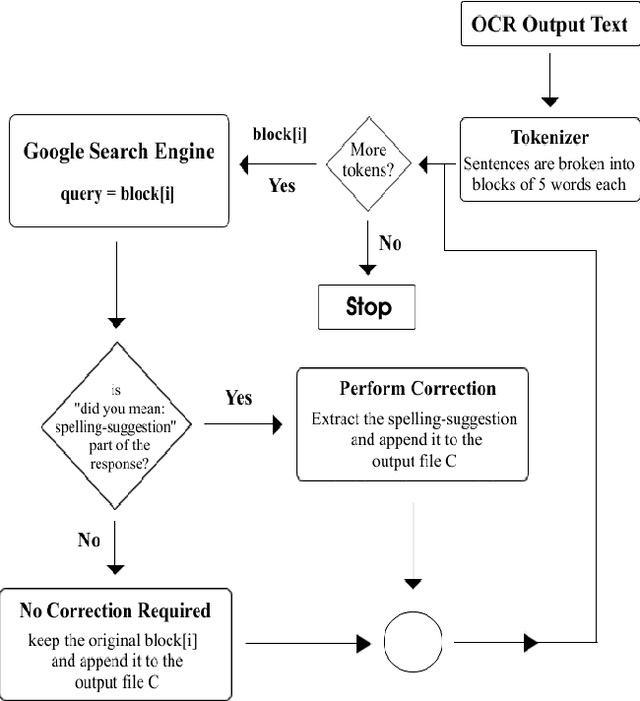
With the advent of digital optical scanners, a lot of paper-based books, textbooks, magazines, articles, and documents are being transformed into an electronic version that can be manipulated by a computer. For this purpose, OCR, short for Optical Character Recognition was developed to translate scanned graphical text into editable computer text. Unfortunately, OCR is still imperfect as it occasionally mis-recognizes letters and falsely identifies scanned text, leading to misspellings and linguistics errors in the OCR output text. This paper proposes a post-processing context-based error correction algorithm for detecting and correcting OCR non-word and real-word errors. The proposed algorithm is based on Google's online spelling suggestion which harnesses an internal database containing a huge collection of terms and word sequences gathered from all over the web, convenient to suggest possible replacements for words that have been misspelled during the OCR process. Experiments carried out revealed a significant improvement in OCR error correction rate. Future research can improve upon the proposed algorithm so much so that it can be parallelized and executed over multiprocessing platforms.
OCR Context-Sensitive Error Correction Based on Google Web 1T 5-Gram Data Set
Apr 01, 2012

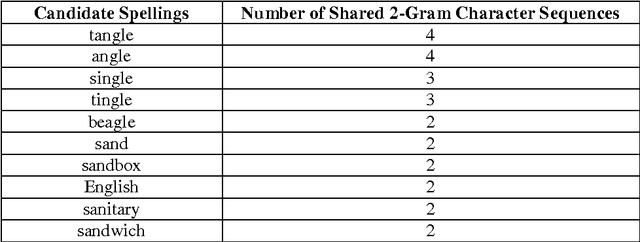
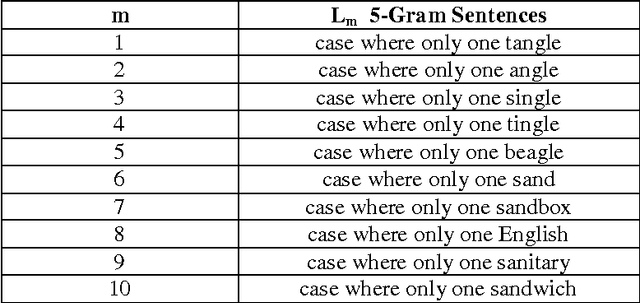
Since the dawn of the computing era, information has been represented digitally so that it can be processed by electronic computers. Paper books and documents were abundant and widely being published at that time; and hence, there was a need to convert them into digital format. OCR, short for Optical Character Recognition was conceived to translate paper-based books into digital e-books. Regrettably, OCR systems are still erroneous and inaccurate as they produce misspellings in the recognized text, especially when the source document is of low printing quality. This paper proposes a post-processing OCR context-sensitive error correction method for detecting and correcting non-word and real-word OCR errors. The cornerstone of this proposed approach is the use of Google Web 1T 5-gram data set as a dictionary of words to spell-check OCR text. The Google data set incorporates a very large vocabulary and word statistics entirely reaped from the Internet, making it a reliable source to perform dictionary-based error correction. The core of the proposed solution is a combination of three algorithms: The error detection, candidate spellings generator, and error correction algorithms, which all exploit information extracted from Google Web 1T 5-gram data set. Experiments conducted on scanned images written in different languages showed a substantial improvement in the OCR error correction rate. As future developments, the proposed algorithm is to be parallelised so as to support parallel and distributed computing architectures.
Post-Editing Error Correction Algorithm for Speech Recognition using Bing Spelling Suggestion
Mar 23, 2012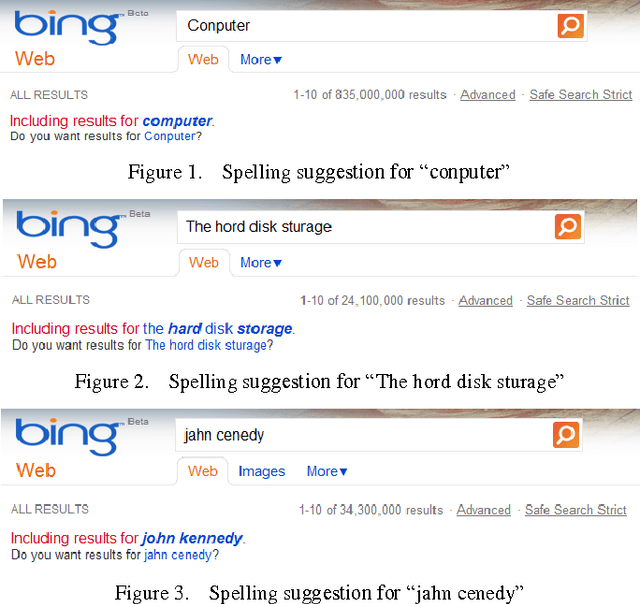
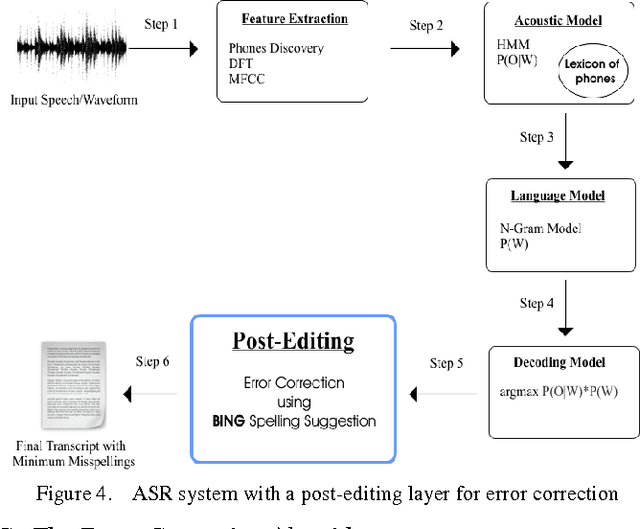
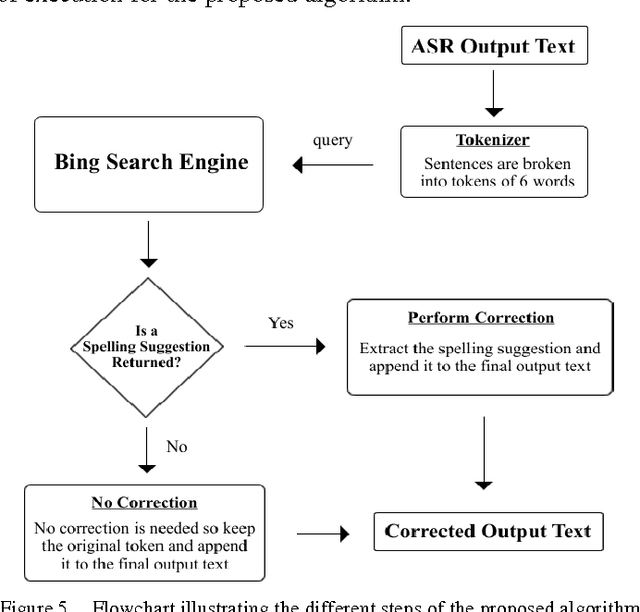
ASR short for Automatic Speech Recognition is the process of converting a spoken speech into text that can be manipulated by a computer. Although ASR has several applications, it is still erroneous and imprecise especially if used in a harsh surrounding wherein the input speech is of low quality. This paper proposes a post-editing ASR error correction method and algorithm based on Bing's online spelling suggestion. In this approach, the ASR recognized output text is spell-checked using Bing's spelling suggestion technology to detect and correct misrecognized words. More specifically, the proposed algorithm breaks down the ASR output text into several word-tokens that are submitted as search queries to Bing search engine. A returned spelling suggestion implies that a query is misspelled; and thus it is replaced by the suggested correction; otherwise, no correction is performed and the algorithm continues with the next token until all tokens get validated. Experiments carried out on various speeches in different languages indicated a successful decrease in the number of ASR errors and an improvement in the overall error correction rate. Future research can improve upon the proposed algorithm so much so that it can be parallelized to take advantage of multiprocessor computers.
* LACSC - Lebanese Association for Computational Sciences - http://www.lacsc.org