 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-Long: Graph-Enhanced Memory Management for Efficient Long-Term Dialogue Agents
Jun 11, 2026While Large Language Models (LLMs) have advanced open-domain dialogue systems, maintaining long-term consistency remains a challenge due to inherent limitations in long-context reasoning and the inefficiency of processing extensive raw text. Existing approaches typically rely on either unstructured memory storage, which is prone to information loss, or computationally expensive LLMs that incur high latency. To address these limitations, we propose G-Long, a graph-enhanced framework that utilizes a fine-tuned small Language Model (sLM) for structured triplet extraction and associative retrieval, significantly reducing operational costs. Furthermore, we introduce the novel attention-aware importance scoring mechanism that leverages the intrinsic cross-attention signals of a T5 summarizer to identify salient memories. Extensive experiments across diverse benchmarks demonstrate that G-Long achieves state-of-the-art performance in both response generation and memory retrieval, yielding performance gains of up to 9.8% in response quality on MSC and 40.8% in retrieval recall on LME, while significantly minimizing computational overhead.
HyPE: Category-Aware Hypergraph Encoding with Persistent Edge Embeddings for Persona-Grounded Dialogue
Jun 11, 2026Persona-grounded dialogue systems aim to produce responses consistent with a speaker's persona, yet existing methods treat personas as a flat set of sentences and fail to model the high-order relations among persona attributes-e.g., that several persona sentences share a topical category. We propose HyPE (Hypergraph Persona Encoder), a framework that (i) analyzes each persona-bearing text as a (Core, Expression, Sentiment, Category) quadruple, and (ii) organizes persona elements into a hypergraph whose hyperedges are induced by shared category labels. An HyperGCN hypergraph neural network propagates this structure into a persona summary vector and a soft-memory bank that condition the response generator. We further propose Persistent Edge Embeddings (PEE), lightweight per-category learnable priors fused into the HyperGCN message-passing step. On PersonaChat under greedy decoding, HyPE consistently outperforms sentence-level pooling baselines across GPT-2, LLaMA-3.2-3B, and Qwen2.5-3B backbones by demonstrating that structured hyperedge-level persona encoding provides a transferable advantage across model scales.
HELEA: Hard-Negative Benchmark and LLM-based Reranking for Robust Entity Alignment
May 27, 2026Entity Alignment (EA) is essential for knowledge graph (KG) fusion, but existing benchmarks often allow models to exploit name overlap rather than relational structure. This makes it difficult to evaluate whether models can reject same-name entities that refer to different real-world objects. Our primary contribution is a same-name hard-negative augmentation strategy that simultaneously yields quality-controlled evaluation benchmarks (DW-HN29K, DY-HN27K) and augmented training corpora (DW-Train, DY-Train), by mining same-name but distinct entity pairs from KG name-collision groups. We further introduce HELEA, a two-stage framework integrating (i) entity encoder retrieval trained on hard-negative-augmented training corpora with 1-hop KG context, and (ii) LLM-based reranking without additional training. Experiments show that name-dependent baselines collapse to near-random performance on our hard-negative benchmarks, while HELEA achieves F1 0.967 on DW-HN29K while maintaining Hit@1 0.993 on standard DW-15K.
DAPI: Domain Adaptive Toxicity Probe Vector Intervention for Fine-Grained Detoxification
Mar 17, 2025



There have been attempts to utilize linear probe for detoxification, with existing studies relying on a single toxicity probe vector to reduce toxicity. However, toxicity can be fine-grained into various subcategories, making it difficult to remove certain types of toxicity by using a single toxicity probe vector. To address this limitation, we propose a category-specific toxicity probe vector approach. First, we train multiple toxicity probe vectors for different toxicity categories. During generation, we dynamically select the most relevant toxicity probe vector based on the current context. Finally, the selected vector is dynamically scaled and subtracted from model. Our method successfully mitigated toxicity from categories that the single probe vector approach failed to detoxify. Experiments demonstrate that our approach achieves up to a 78.52% reduction in toxicity on the evaluation dataset, while fluency remains nearly unchanged, with only a 0.052% drop compared to the unsteered model.
SS-MPC: A Sequence-Structured Multi-Party Conversation System
Feb 24, 2025Recent Multi-Party Conversation (MPC) models typically rely on graph-based approaches to capture dialogue structures. However, these methods have limitations, such as information loss during the projection of utterances into structural embeddings and constraints in leveraging pre-trained language models directly. In this paper, we propose \textbf{SS-MPC}, a response generation model for MPC that eliminates the need for explicit graph structures. Unlike existing models that depend on graphs to analyze conversation structures, SS-MPC internally encodes the dialogue structure as a sequential input, enabling direct utilization of pre-trained language models. Experimental results show that \textbf{SS-MPC} achieves \textbf{15.60\% BLEU-1} and \textbf{12.44\% ROUGE-L} score, outperforming the current state-of-the-art MPC response generation model by \textbf{3.91\%p} in \textbf{BLEU-1} and \textbf{0.62\%p} in \textbf{ROUGE-L}. Additionally, human evaluation confirms that SS-MPC generates more fluent and accurate responses compared to existing MPC models.
Dependency Parsing with the Structuralized Prompt Template
Feb 24, 2025Dependency parsing is a fundamental task in natural language processing (NLP), aiming to identify syntactic dependencies and construct a syntactic tree for a given sentence. Traditional dependency parsing models typically construct embeddings and utilize additional layers for prediction. We propose a novel dependency parsing method that relies solely on an encoder model with a text-to-text training approach. To facilitate this, we introduce a structured prompt template that effectively captures the structural information of dependency trees. Our experimental results demonstrate that the proposed method achieves outstanding performance compared to traditional models, despite relying solely on a pre-trained model. Furthermore, this method is highly adaptable to various pre-trained models across different target languages and training environments, allowing easy integration of task-specific features.
Word Sense Disambiguation using Knowledge-based Word Similarity
Nov 11, 2019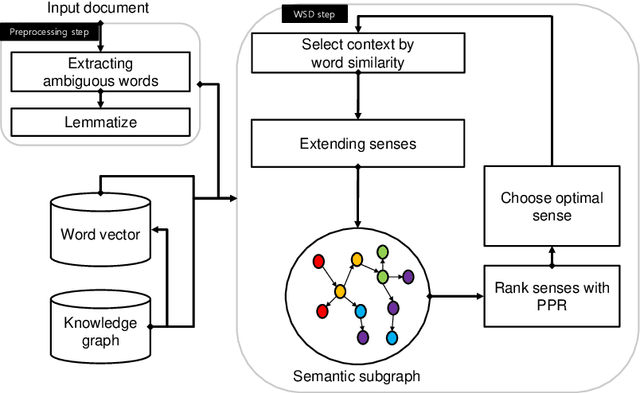
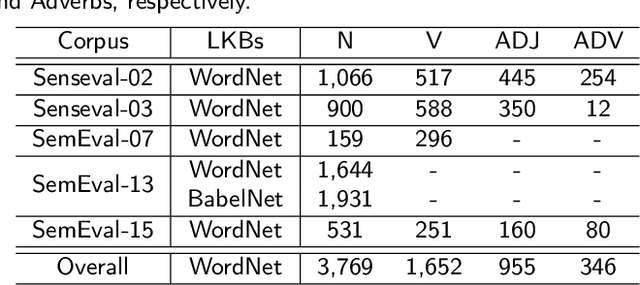
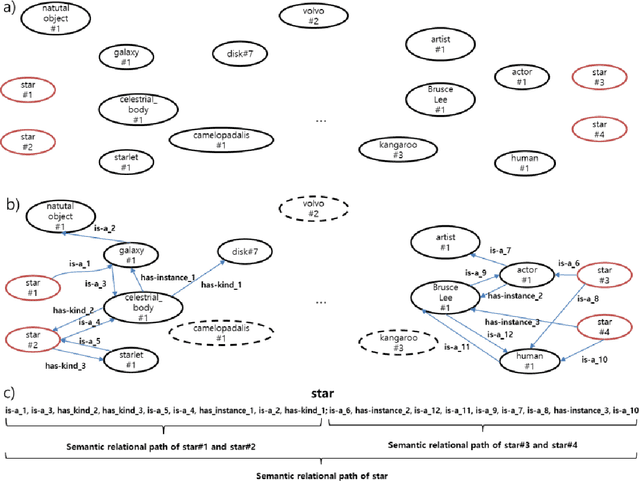

In natural language processing, word-sense disambiguation (WSD) is an open problem concerned with identifying the correct sense of words in a particular context. To address this problem, we introduce a novel knowledge-based WSD system. We suggest the adoption of two methods in our system. First, we suggest a novel method to encode the word vector representation by considering the graphical semantic relationships from the lexical knowledge-base. Second, we propose a method for extracting the contextual words from the text for analyzing an ambiguous word based on the similarity of word vector representations. To validate the effectiveness of our WSD system, we conducted experiments on the five benchmark English WSD corpora (Senseval-02, Senseval-03, SemEval-07, SemEval-13, and SemEval-15). The obtained results demonstrated that the suggested methods significantly enhanced the WSD performance. Furthermore, our system outperformed the existing knowledge-based WSD systems and showed a performance comparable to that of the state-of-the-art supervised WSD systems.