 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Semantic Profiles into Knowledge Graph for Recommender Systems Using Large Language Models
Jan 13, 2026Rich and informative profiling to capture user preferences is essential for improving recommendation quality. However, there is still no consensus on how best to construct and utilize such profiles. To address this, we revisit recent profiling-based approaches in recommender systems along four dimensions: 1) knowledge base, 2) preference indicator, 3) impact range, and 4) subject. We argue that large language models (LLMs) are effective at extracting compressed rationales from diverse knowledge sources, while knowledge graphs (KGs) are better suited for propagating these profiles to extend their reach. Building on this insight, we propose a new recommendation model, called SPiKE. SPiKE consists of three core components: i) Entity profile generation, which uses LLMs to generate semantic profiles for all KG entities; ii) Profile-aware KG aggregation, which integrates these profiles into the KG; and iii) Pairwise profile preference matching, which aligns LLM- and KG-based representations during training. In experiments, we demonstrate that SPiKE consistently outperforms state-of-the-art KG- and LLM-based recommenders in real-world settings.
Sensor Calibration Model Balancing Accuracy, Real-time, and Efficiency
Nov 10, 2025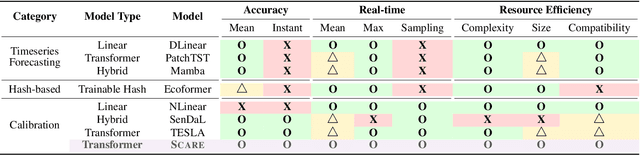
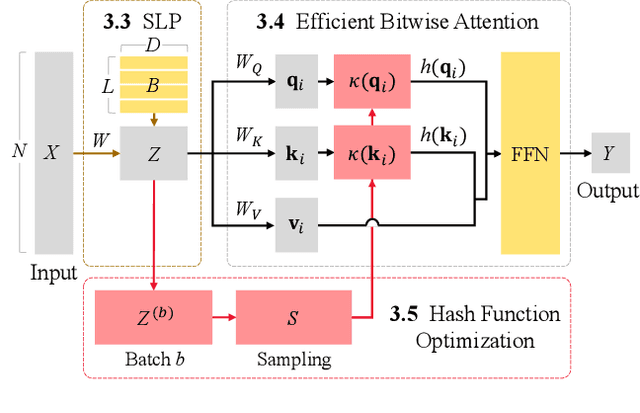
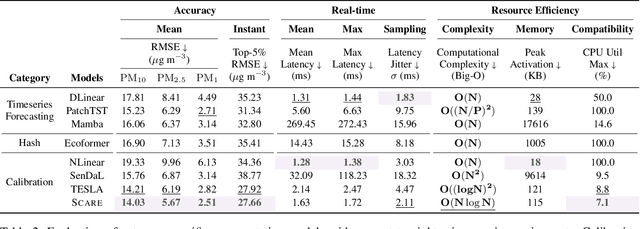
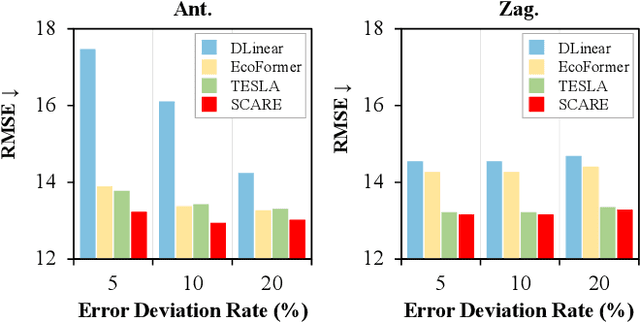
Most on-device sensor calibration studies benchmark models only against three macroscopic requirements (i.e., accuracy, real-time, and resource efficiency), thereby hiding deployment bottlenecks such as instantaneous error and worst-case latency. We therefore decompose this triad into eight microscopic requirements and introduce Scare (Sensor Calibration model balancing Accuracy, Real-time, and Efficiency), an ultra-compressed transformer that fulfills them all. SCARE comprises three core components: (1) Sequence Lens Projector (SLP) that logarithmically compresses time-series data while preserving boundary information across bins, (2) Efficient Bitwise Attention (EBA) module that replaces costly multiplications with bitwise operations via binary hash codes, and (3) Hash optimization strategy that ensures stable training without auxiliary loss terms. Together, these components minimize computational overhead while maintaining high accuracy and compatibility with microcontroller units (MCUs). Extensive experiments on large-scale air-quality datasets and real microcontroller deployments demonstrate that Scare outperforms existing linear, hybrid, and deep-learning baselines, making Scare, to the best of our knowledge, the first model to meet all eight microscopic requirements simultaneously.
RecKG: Knowledge Graph for Recommender Systems
Jan 07, 2025



Knowledge graphs have proven successful in integrating heterogeneous data across various domains. However, there remains a noticeable dearth of research on their seamless integration among heterogeneous recommender systems, despite knowledge graph-based recommender systems garnering extensive research attention. This study aims to fill this gap by proposing RecKG, a standardized knowledge graph for recommender systems. RecKG ensures the consistent representation of entities across different datasets, accommodating diverse attribute types for effective data integration. Through a meticulous examination of various recommender system datasets, we select attributes for RecKG, ensuring standardized formatting through consistent naming conventions. By these characteristics, RecKG can seamlessly integrate heterogeneous data sources, enabling the discovery of additional semantic information within the integrated knowledge graph. We apply RecKG to standardize real-world datasets, subsequently developing an application for RecKG using a graph database. Finally, we validate RecKG's achievement in interoperability through a qualitative evaluation between RecKG and other studies.
Real-time Calibration Model for Low-cost Sensor in Fine-grained Time series
Dec 28, 2024



Precise measurements from sensors are crucial, but data is usually collected from low-cost, low-tech systems, which are often inaccurate. Thus, they require further calibrations. To that end, we first identify three requirements for effective calibration under practical low-tech sensor conditions. Based on the requirements, we develop a model called TESLA, Transformer for effective sensor calibration utilizing logarithmic-binned attention. TESLA uses a high-performance deep learning model, Transformers, to calibrate and capture non-linear components. At its core, it employs logarithmic binning to minimize attention complexity. TESLA achieves consistent real-time calibration, even with longer sequences and finer-grained time series in hardware-constrained systems. Experiments show that TESLA outperforms existing novel deep learning and newly crafted linear models in accuracy, calibration speed, and energy efficiency.
Topic-Aware Knowledge Graph with Large Language Models for Interoperability in Recommender Systems
Dec 28, 2024



The use of knowledge graphs in recommender systems has become one of the common approaches to addressing data sparsity and cold start problems. Recent advances in large language models (LLMs) offer new possibilities for processing side and context information within knowledge graphs. However, consistent integration across various systems remains challenging due to the need for domain expert intervention and differences in system characteristics. To address these issues, we propose a consistent approach that extracts both general and specific topics from both side and context information using LLMs. First, general topics are iteratively extracted and updated from side information. Then, specific topics are extracted using context information. Finally, to address synonymous topics generated during the specific topic extraction process, a refining algorithm processes and resolves these issues effectively. This approach allows general topics to capture broad knowledge across diverse item characteristics, while specific topics emphasize detailed attributes, providing a more comprehensive understanding of the semantic features of items and the preferences of users. Experimental results demonstrate significant improvements in recommendation performance across diverse knowledge graphs.