 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Min--Max Continuous Optimization Using CMA-ES with Worst-case Ranking Approximation
Apr 06, 2022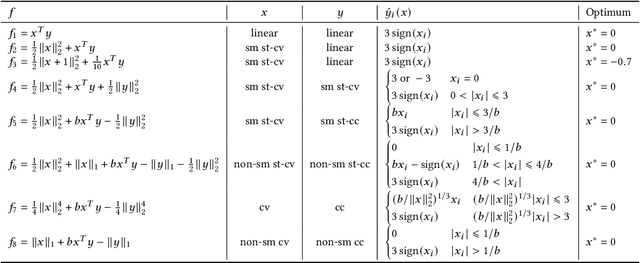
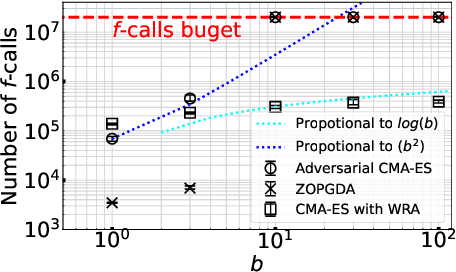
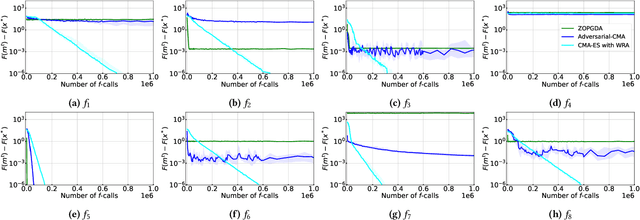
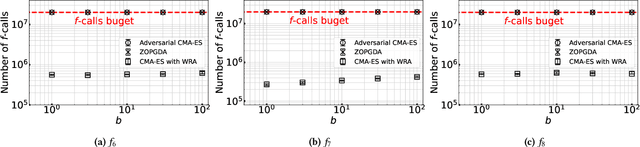
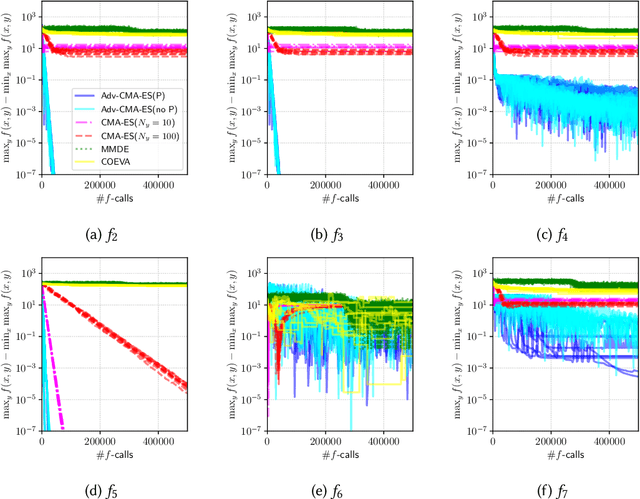
In this study, we investigate the problem of min-max continuous optimization in a black-box setting $\min_{x} \max_{y}f(x,y)$. A popular approach updates $x$ and $y$ simultaneously or alternatingly. However, two major limitations have been reported in existing approaches. (I) As the influence of the interaction term between $x$ and $y$ (e.g., $x^\mathrm{T} B y$) on the Lipschitz smooth and strongly convex-concave function $f$ increases, the approaches converge to an optimal solution at a slower rate. (II) The approaches fail to converge if $f$ is not Lipschitz smooth and strongly convex-concave around the optimal solution. To address these difficulties, we propose minimizing the worst-case objective function $F(x)=\max_{y}f(x,y)$ directly using the covariance matrix adaptation evolution strategy, in which the rankings of solution candidates are approximated by our proposed worst-case ranking approximation (WRA) mechanism. Compared with existing approaches, numerical experiments show two important findings regarding our proposed method. (1) The proposed approach is efficient in terms of $f$-calls on a Lipschitz smooth and strongly convex-concave function with a large interaction term. (2) The proposed approach can converge on functions that are not Lipschitz smooth and strongly convex-concave around the optimal solution, whereas existing approaches fail.
Monotone Improvement of Information-Geometric Optimization Algorithms with a Surrogate Function
Apr 06, 2022A surrogate function is often employed to reduce the number of objective function evaluations for optimization. However, the effect of using a surrogate model in evolutionary approaches has not been theoretically investigated. This paper theoretically analyzes the information-geometric optimization framework using a surrogate function. The value of the expected objective function under the candidate sampling distribution is used as the measure of progress of the algorithm. We assume that the surrogate function is maintained so that the population version of the Kendall's rank correlation coefficient between the surrogate function and the objective function under the candidate sampling distribution is greater than or equal to a predefined threshold. We prove that information-geometric optimization using such a surrogate function leads to a monotonic decrease in the expected objective function value if the threshold is sufficiently close to one. The acceptable threshold value is analyzed for the case of the information-geometric optimization instantiated with Gaussian distributions, i.e., the rank-$\mu$ update CMA-ES, on a convex quadratic objective function. As an alternative to the Kendall's rank correlation coefficient, we investigate the use of the Pearson correlation coefficient between the weights assigned to candidate solutions based on the objective function and the surrogate function.
A Two-phase Framework with a Bézier Simplex-based Interpolation Method for Computationally Expensive Multi-objective Optimization
Mar 29, 2022
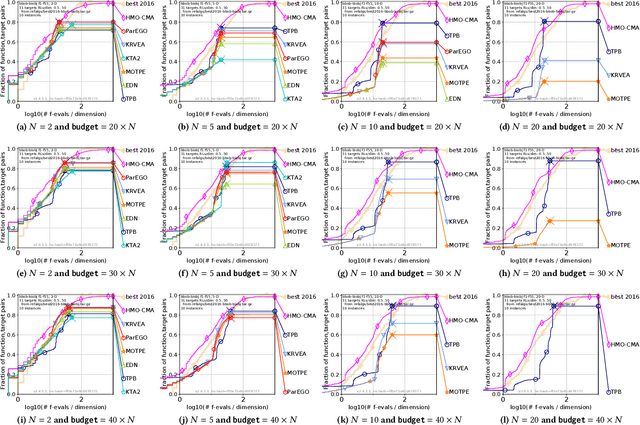
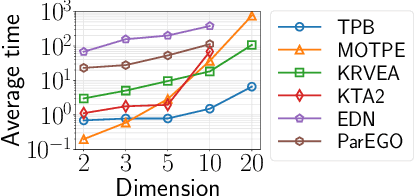
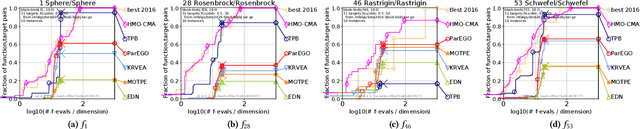
This paper proposes a two-phase framework with a B\'{e}zier simplex-based interpolation method (TPB) for computationally expensive multi-objective optimization. The first phase in TPB aims to approximate a few Pareto optimal solutions by optimizing a sequence of single-objective scalar problems. The first phase in TPB can fully exploit a state-of-the-art single-objective derivative-free optimizer. The second phase in TPB utilizes a B\'{e}zier simplex model to interpolate the solutions obtained in the first phase. The second phase in TPB fully exploits the fact that a B\'{e}zier simplex model can approximate the Pareto optimal solution set by exploiting its simplex structure when a given problem is simplicial. We investigate the performance of TPB on the 55 bi-objective BBOB problems. The results show that TPB performs significantly better than HMO-CMA-ES and some state-of-the-art meta-model-based optimizers.
Unsupervised Causal Binary Concepts Discovery with VAE for Black-box Model Explanation
Sep 09, 2021



We aim to explain a black-box classifier with the form: `data X is classified as class Y because X \textit{has} A, B and \textit{does not have} C' in which A, B, and C are high-level concepts. The challenge is that we have to discover in an unsupervised manner a set of concepts, i.e., A, B and C, that is useful for the explaining the classifier. We first introduce a structural generative model that is suitable to express and discover such concepts. We then propose a learning process that simultaneously learns the data distribution and encourages certain concepts to have a large causal influence on the classifier output. Our method also allows easy integration of user's prior knowledge to induce high interpretability of concepts. Using multiple datasets, we demonstrate that our method can discover useful binary concepts for explanation.
Saddle Point Optimization with Approximate Minimization Oracle and its Application to Robust Berthing Control
May 26, 2021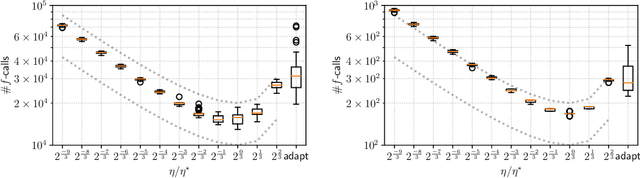

We propose an approach to saddle point optimization relying only on an oracle that solves a minimization problem approximately. We analyze its convergence property on a strongly convex--concave problem and show its linear convergence toward the global min--max saddle point. Based on the convergence analysis, we propose a heuristic approach to adapt the learning rate for the proposed saddle point optimization approach. The implementation of the proposed approach using the (1+1)-CMA-ES as the minimization oracle, namely Adversarial-CMA-ES, is evaluated on test problems. Numerical evaluation reveals the tightness of the theoretical convergence rate bound as well as the efficiency of the learning rate adaptation mechanism. As an example of real-world applications, it is applied to automatic berthing control problems under model uncertainties, showing its usefulness in obtaining solutions robust under model uncertainties.
Level Generation for Angry Birds with Sequential VAE and Latent Variable Evolution
Apr 13, 2021

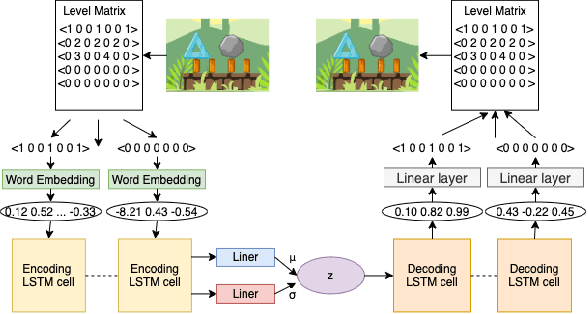

Video game level generation based on machine learning (ML), in particular, deep generative models, has attracted attention as a technique to automate level generation. However, applications of existing ML-based level generations are mostly limited to tile-based level representation. When ML techniques are applied to game domains with non-tile-based level representation, such as Angry Birds, where objects in a level are specified by real-valued parameters, ML often fails to generate playable levels. In this study, we develop a deep-generative-model-based level generation for the game domain of Angry Birds. To overcome these drawbacks, we propose a sequential encoding of a level and process it as text data, whereas existing approaches employ a tile-based encoding and process it as an image. Experiments show that the proposed level generator drastically improves the stability and diversity of generated levels compared with existing approaches. We apply latent variable evolution with the proposed generator to control the feature of a generated level computed through an AI agent's play, while keeping the level stable and natural.
Saddle Point Optimization with Approximate Minimization Oracle
Mar 31, 2021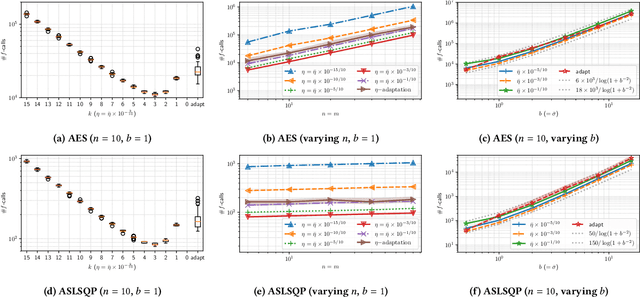
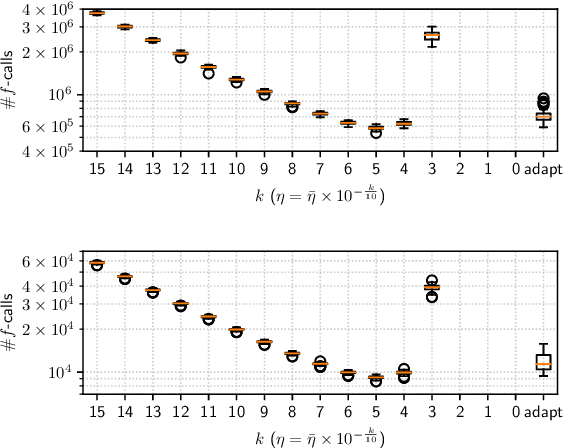
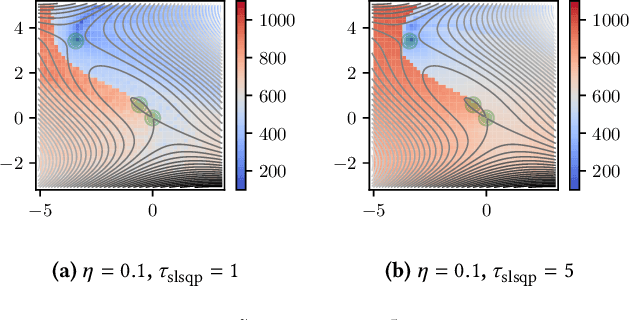
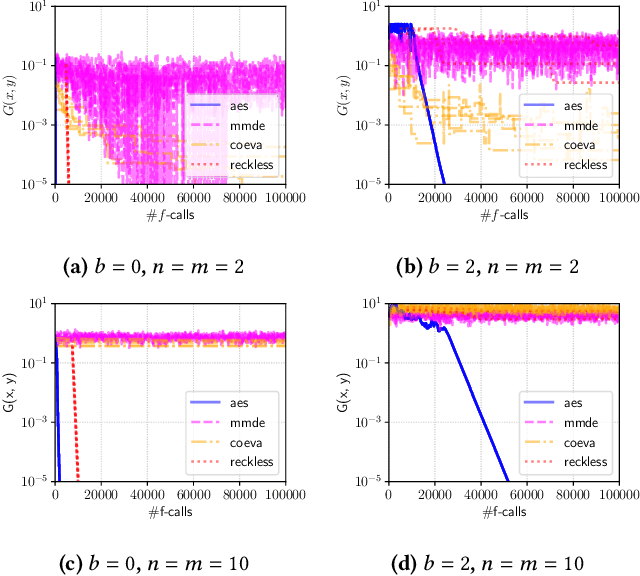
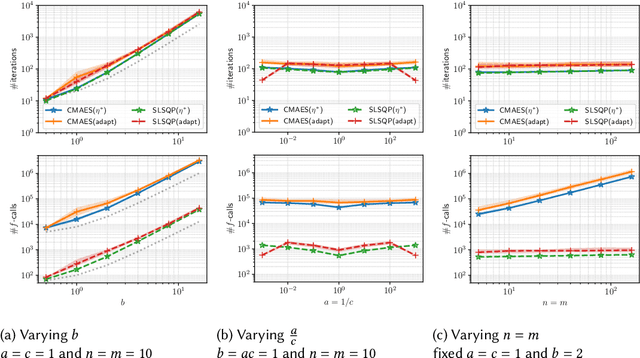
A major approach to saddle point optimization $\min_x\max_y f(x, y)$ is a gradient based approach as is popularized by generative adversarial networks (GANs). In contrast, we analyze an alternative approach relying only on an oracle that solves a minimization problem approximately. Our approach locates approximate solutions $x'$ and $y'$ to $\min_{x'}f(x', y)$ and $\max_{y'}f(x, y')$ at a given point $(x, y)$ and updates $(x, y)$ toward these approximate solutions $(x', y')$ with a learning rate $\eta$. On locally strong convex--concave smooth functions, we derive conditions on $\eta$ to exhibit linear convergence to a local saddle point, which reveals a possible shortcoming of recently developed robust adversarial reinforcement learning algorithms. We develop a heuristic approach to adapt $\eta$ derivative-free and implement zero-order and first-order minimization algorithms. Numerical experiments are conducted to show the tightness of the theoretical results as well as the usefulness of the $\eta$ adaptation mechanism.
Convergence Rate of the -Evolution Strategy with Success-Based Step-Size Adaptation on Convex Quadratic Functions
Mar 02, 2021The (1+1)-evolution strategy (ES) with success-based step-size adaptation is analyzed on a general convex quadratic function and its monotone transformation, that is, $f(x) = g((x - x^*)^\mathrm{T} H (x - x^*))$, where $g:\mathbb{R}\to\mathbb{R}$ is a strictly increasing function, $H$ is a positive-definite symmetric matrix, and $x^* \in \mathbb{R}^d$ is the optimal solution of $f$. The convergence rate, that is, the decrease rate of the distance from a search point $m_t$ to the optimal solution $x^*$, is proven to be in $O(\exp( - L / \mathrm{Tr}(H) ))$, where $L$ is the smallest eigenvalue of $H$ and $\mathrm{Tr}(H)$ is the trace of $H$. This result generalizes the known rate of $O(\exp(- 1/d ))$ for the case of $H = I_{d}$ ($I_d$ is the identity matrix of dimension $d$) and $O(\exp(- 1/ (d\cdot\xi) ))$ for the case of $H = \mathrm{diag}(\xi \cdot I_{d/2}, I_{d/2})$. To the best of our knowledge, this is the first study in which the convergence rate of the (1+1)-ES is derived explicitly and rigorously on a general convex quadratic function, which depicts the impact of the distribution of the eigenvalues in the Hessian $H$ on the optimization and not only the impact of the condition number of $H$.
Warm Starting CMA-ES for Hyperparameter Optimization
Dec 13, 2020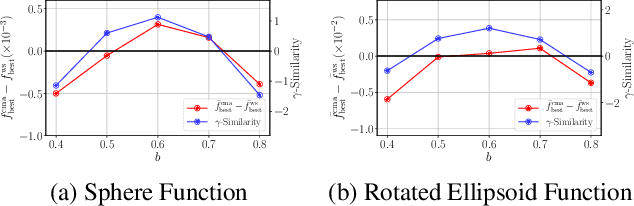

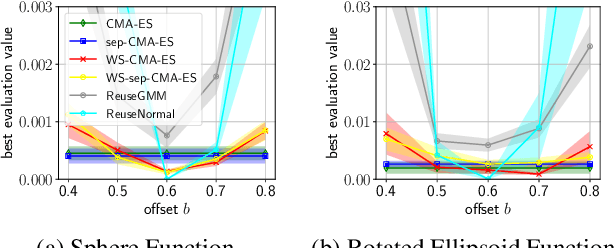
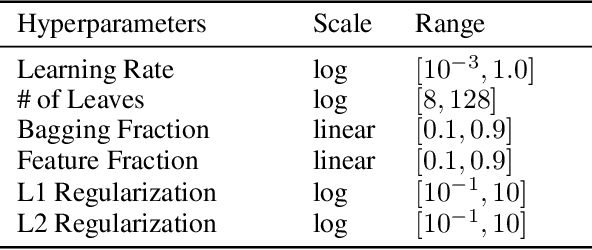
Hyperparameter optimization (HPO), formulated as black-box optimization (BBO), is recognized as essential for automation and high performance of machine learning approaches. The CMA-ES is a promising BBO approach with a high degree of parallelism, and has been applied to HPO tasks, often under parallel implementation, and shown superior performance to other approaches including Bayesian optimization (BO). However, if the budget of hyperparameter evaluations is severely limited, which is often the case for end users who do not deserve parallel computing, the CMA-ES exhausts the budget without improving the performance due to its long adaptation phase, resulting in being outperformed by BO approaches. To address this issue, we propose to transfer prior knowledge on similar HPO tasks through the initialization of the CMA-ES, leading to significantly shortening the adaptation time. The knowledge transfer is designed based on the novel definition of task similarity, with which the correlation of the performance of the proposed approach is confirmed on synthetic problems. The proposed warm starting CMA-ES, called WS-CMA-ES, is applied to different HPO tasks where some prior knowledge is available, showing its superior performance over the original CMA-ES as well as BO approaches with or without using the prior knowledge.
AdvantageNAS: Efficient Neural Architecture Search with Credit Assignment
Dec 11, 2020



Neural architecture search (NAS) is an approach for automatically designing a neural network architecture without human effort or expert knowledge. However, the high computational cost of NAS limits its use in commercial applications. Two recent NAS paradigms, namely one-shot and sparse propagation, which reduce the time and space complexities, respectively, provide clues for solving this problem. In this paper, we propose a novel search strategy for one-shot and sparse propagation NAS, namely AdvantageNAS, which further reduces the time complexity of NAS by reducing the number of search iterations. AdvantageNAS is a gradient-based approach that improves the search efficiency by introducing credit assignment in gradient estimation for architecture updates. Experiments on the NAS-Bench-201 and PTB dataset show that AdvantageNAS discovers an architecture with higher performance under a limited time budget compared to existing sparse propagation NAS. To further reveal the reliabilities of AdvantageNAS, we investigate it theoretically and find that it monotonically improves the expected loss and thus converges.