 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyGALAX: An Open-Source Python Toolkit for Advanced Explainable Geospatial Machine Learning
Jan 31, 2026PyGALAX is a Python package for geospatial analysis that integrates automated machine learning (AutoML) and explainable artificial intelligence (XAI) techniques to analyze spatial heterogeneity in both regression and classification tasks. It automatically selects and optimizes machine learning models for different geographic locations and contexts while maintaining interpretability through SHAP (SHapley Additive exPlanations) analysis. PyGALAX builds upon and improves the GALAX framework (Geospatial Analysis Leveraging AutoML and eXplainable AI), which has proven to outperform traditional geographically weighted regression (GWR) methods. Critical enhancements in PyGALAX from the original GALAX framework include automatic bandwidth selection and flexible kernel function selection, providing greater flexibility and robustness for spatial modeling across diverse datasets and research questions. PyGALAX not only inherits all the functionalities of the original GALAX framework but also packages them into an accessible, reproducible, and easily deployable Python toolkit while providing additional options for spatial modeling. It effectively addresses spatial non-stationarity and generates transparent insights into complex spatial relationships at both global and local scales, making advanced geospatial machine learning methods accessible to researchers and practitioners in geography, urban planning, environmental science, and related fields.
Extracting all Aspect-polarity Pairs Jointly in a Text with Relation Extraction Approach
Sep 01, 2021
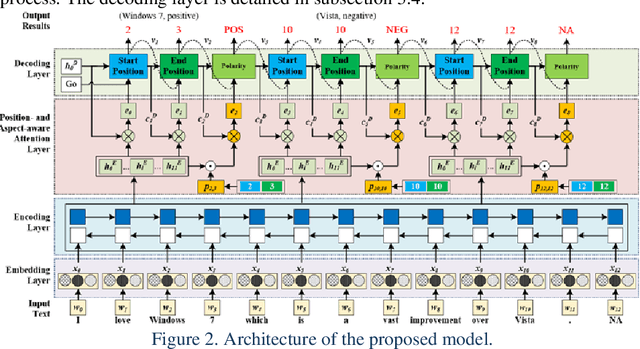
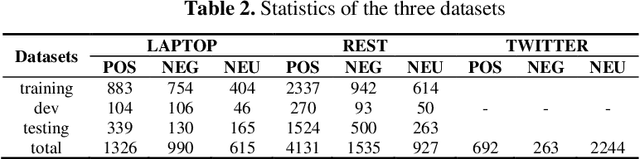
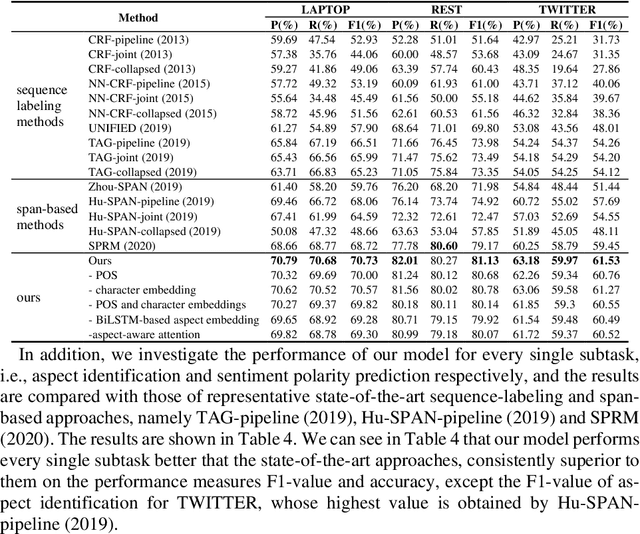
Extracting aspect-polarity pairs from texts is an important task of fine-grained sentiment analysis. While the existing approaches to this task have gained many progresses, they are limited at capturing relationships among aspect-polarity pairs in a text, thus degrading the extraction performance. Moreover, the existing state-of-the-art approaches, namely token-based se-quence tagging and span-based classification, have their own defects such as polarity inconsistency resulted from separately tagging tokens in the former and the heterogeneous categorization in the latter where aspect-related and polarity-related labels are mixed. In order to remedy the above defects, in-spiring from the recent advancements in relation extraction, we propose to generate aspect-polarity pairs directly from a text with relation extraction technology, regarding aspect-pairs as unary relations where aspects are enti-ties and the corresponding polarities are relations. Based on the perspective, we present a position- and aspect-aware sequence2sequence model for joint extraction of aspect-polarity pairs. The model is characterized with its ability to capture not only relationships among aspect-polarity pairs in a text through the sequence decoding, but also correlations between an aspect and its polarity through the position- and aspect-aware attentions. The experi-ments performed on three benchmark datasets demonstrate that our model outperforms the existing state-of-the-art approaches, making significant im-provement over them.