 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Semantic-Geometric Approach for Clutter-Resistant Floorplan Generation from Building Point Clouds
May 15, 2023



Building Information Modeling (BIM) technology is a key component of modern construction engineering and project management workflows. As-is BIM models that represent the spatial reality of a project site can offer crucial information to stakeholders for construction progress monitoring, error checking, and building maintenance purposes. Geometric methods for automatically converting raw scan data into BIM models (Scan-to-BIM) often fail to make use of higher-level semantic information in the data. Whereas, semantic segmentation methods only output labels at the point level without creating object level models that is necessary for BIM. To address these issues, this research proposes a hybrid semantic-geometric approach for clutter-resistant floorplan generation from laser-scanned building point clouds. The input point clouds are first pre-processed by normalizing the coordinate system and removing outliers. Then, a semantic segmentation network based on PointNet++ is used to label each point as ceiling, floor, wall, door, stair, and clutter. The clutter points are removed whereas the wall, door, and stair points are used for 2D floorplan generation. A region-growing segmentation algorithm paired with geometric reasoning rules is applied to group the points together into individual building elements. Finally, a 2-fold Random Sample Consensus (RANSAC) algorithm is applied to parameterize the building elements into 2D lines which are used to create the output floorplan. The proposed method is evaluated using the metrics of precision, recall, Intersection-over-Union (IOU), Betti error, and warping error.
LRGNet: Learnable Region Growing for Class-Agnostic Point Cloud Segmentation
Mar 16, 2021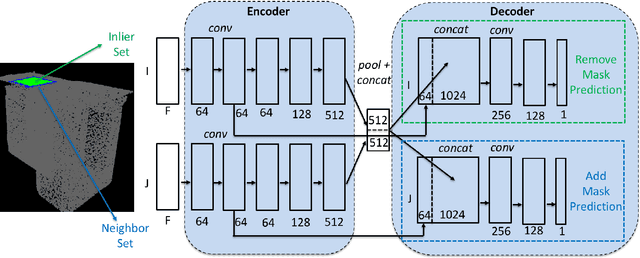
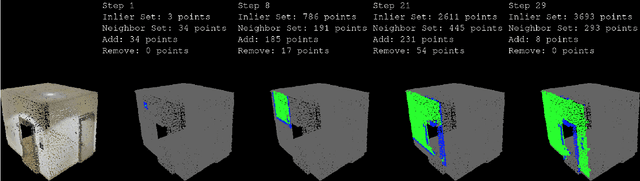

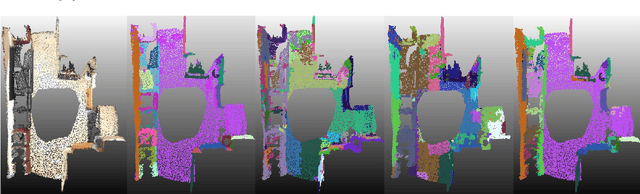
3D point cloud segmentation is an important function that helps robots understand the layout of their surrounding environment and perform tasks such as grasping objects, avoiding obstacles, and finding landmarks. Current segmentation methods are mostly class-specific, many of which are tuned to work with specific object categories and may not be generalizable to different types of scenes. This research proposes a learnable region growing method for class-agnostic point cloud segmentation, specifically for the task of instance label prediction. The proposed method is able to segment any class of objects using a single deep neural network without any assumptions about their shapes and sizes. The deep neural network is trained to predict how to add or remove points from a point cloud region to morph it into incrementally more complete regions of an object instance. Segmentation results on the S3DIS and ScanNet datasets show that the proposed method outperforms competing methods by 1%-9% on 6 different evaluation metrics.
Multi-view Incremental Segmentation of 3D Point Clouds for Mobile Robots
Feb 18, 2019
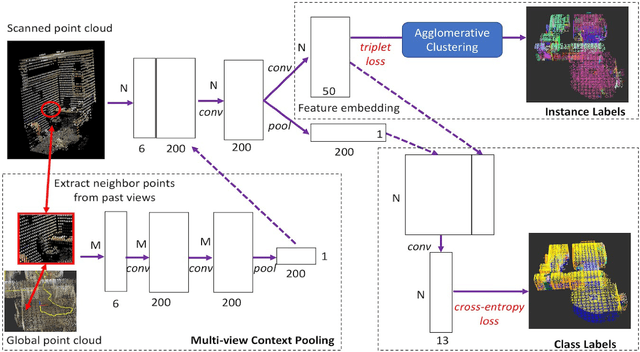
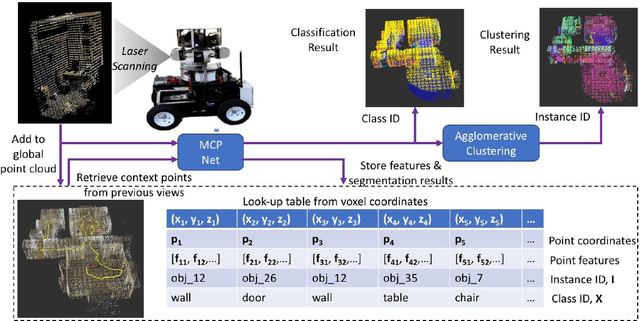

Mobile robots need to create high-definition 3D maps of the environment for applications such as remote surveillance and infrastructure mapping. Accurate semantic processing of the acquired 3D point cloud is critical for allowing the robot to obtain a high-level understanding of the surrounding objects and perform context-aware decision making. Existing techniques for point cloud semantic segmentation are mostly applied on a single-frame or offline basis, with no way to integrate the segmentation results over time. This paper proposes an online method for mobile robots to incrementally build a semantically-rich 3D point cloud of the environment. The proposed deep neural network, MCPNet, is trained to predict class labels and object instance labels for each point in the scanned point cloud in an incremental fashion. A multi-view context pooling (MCP) operator is used to combine point features obtained from multiple viewpoints to improve the classification accuracy. The proposed architecture was trained and evaluated on ray-traced scans derived from the Stanford 3D Indoor Spaces dataset. Results show that the proposed approach led to 15% improvement in point-wise accuracy and 7% improvement in NMI compared to the next best online method, with only a 6% drop in accuracy compared to the PointNet-based offline approach.