 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-assisted High-speed Combinatorial Optimization with Ising Machines for Dynamically Changing Problems
Mar 31, 2025Quantum or quantum-inspired Ising machines have recently shown promise in solving combinatorial optimization problems in a short time. Real-world applications, such as time division multiple access (TDMA) scheduling for wireless multi-hop networks and financial trading, require solving those problems sequentially where the size and characteristics change dynamically. However, using Ising machines involves challenges to shorten system-wide latency due to the transfer of large Ising model or the cloud access and to determine the parameters for each problem. Here we show a combinatorial optimization method using embedded Ising machines, which enables solving diverse problems at high speed without runtime parameter tuning. We customize the algorithm and circuit architecture of the simulated bifurcation-based Ising machine to compress the Ising model and accelerate computation and then built a machine learning model to estimate appropriate parameters using extensive training data. In TDMA scheduling for wireless multi-hop networks, our demonstration has shown that the sophisticated system can adapt to changes in the problem and showed that it has a speed advantage over conventional methods.
Enhancing In-vehicle Multiple Object Tracking Systems with Embeddable Ising Machines
Oct 18, 2024A cognitive function of tracking multiple objects, needed in autonomous mobile vehicles, comprises object detection and their temporal association. While great progress owing to machine learning has been recently seen for elaborating the similarity matrix between the objects that have been recognized and the objects detected in a current video frame, less for the assignment problem that finally determines the temporal association, which is a combinatorial optimization problem. Here we show an in-vehicle multiple object tracking system with a flexible assignment function for tracking through multiple long-term occlusion events. To solve the flexible assignment problem formulated as a nondeterministic polynomial time-hard problem, the system relies on an embeddable Ising machine based on a quantum-inspired algorithm called simulated bifurcation. Using a vehicle-mountable computing platform, we demonstrate a realtime system-wide throughput (23 frames per second on average) with the enhanced functionality.
Collaborative filtering based on nonnegative/binary matrix factorization
Oct 14, 2024Collaborative filtering generates recommendations based on user-item similarities through rating data, which may involve numerous unrated items. To predict scores for unrated items, matrix factorization techniques, such as nonnegative matrix factorization (NMF), are often employed to predict scores for unrated items. Nonnegative/binary matrix factorization (NBMF), which is an extension of NMF, approximates a nonnegative matrix as the product of nonnegative and binary matrices. Previous studies have employed NBMF for image analysis where the data were dense. In this paper, we propose a modified NBMF algorithm that can be applied to collaborative filtering where data are sparse. In the modified method, unrated elements in a rating matrix are masked, which improves the collaborative filtering performance. Utilizing a low-latency Ising machine in NBMF is advantageous in terms of the computation time, making the proposed method beneficial.
Gradient Noise Convolution (GNC): Smoothing Loss Function for Distributed Large-Batch SGD
Jun 26, 2019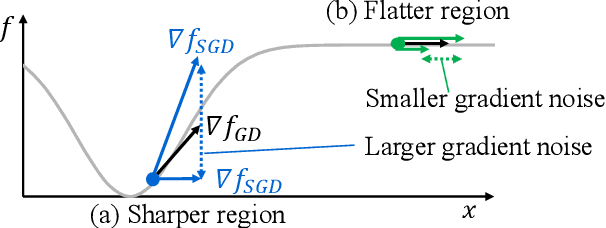

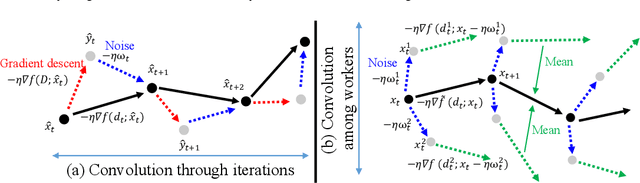
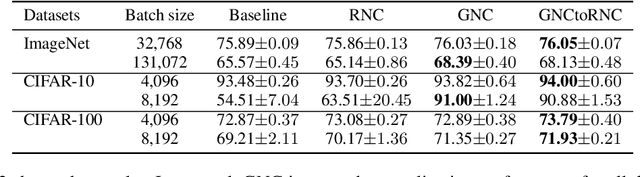
Large-batch stochastic gradient descent (SGD) is widely used for training in distributed deep learning because of its training-time efficiency, however, extremely large-batch SGD leads to poor generalization and easily converges to sharp minima, which prevents naive large-scale data-parallel SGD (DP-SGD) from converging to good minima. To overcome this difficulty, we propose gradient noise convolution (GNC), which effectively smooths sharper minima of the loss function. For DP-SGD, GNC utilizes so-called gradient noise, which is induced by stochastic gradient variation and convolved to the loss function as a smoothing effect. GNC computation can be performed by simply computing the stochastic gradient on each parallel worker and merging them, and is therefore extremely easy to implement. Due to convolving with the gradient noise, which tends to spread along a sharper direction of the loss function, GNC can effectively smooth sharp minima and achieve better generalization, whereas isotropic random noise cannot. We empirically show this effect by comparing GNC with isotropic random noise, and show that it achieves state-of-the-art generalization performance for large-scale deep neural network optimization.