 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Determines Optimal Architecture in Materials Segmentation
Feb 04, 2026Segmentation architectures are typically benchmarked on single imaging modalities, obscuring deployment-relevant performance variations: an architecture optimal for one modality may underperform on another. We present a cross-modal evaluation framework for materials image segmentation spanning SEM, AFM, XCT, and optical microscopy. Our evaluation of six encoder-decoder combinations across seven datasets reveals that optimal architectures vary systematically by context: UNet excels for high-contrast 2D imaging while DeepLabv3+ is preferred for the hardest cases. The framework also provides deployment feedback via out-of-distribution detection and counterfactual explanations that reveal which microstructural features drive predictions. Together, the architecture guidance, reliability signals, and interpretability tools address a practical gap in materials characterization, where researchers lack tools to select architectures for their specific imaging setup or assess when models can be trusted on new samples.
Assessing LLMs for Serendipity Discovery in Knowledge Graphs: A Case for Drug Repurposing
Nov 16, 2025Large Language Models (LLMs) have greatly advanced knowledge graph question answering (KGQA), yet existing systems are typically optimized for returning highly relevant but predictable answers. A missing yet desired capacity is to exploit LLMs to suggest surprise and novel ("serendipitious") answers. In this paper, we formally define the serendipity-aware KGQA task and propose the SerenQA framework to evaluate LLMs' ability to uncover unexpected insights in scientific KGQA tasks. SerenQA includes a rigorous serendipity metric based on relevance, novelty, and surprise, along with an expert-annotated benchmark derived from the Clinical Knowledge Graph, focused on drug repurposing. Additionally, it features a structured evaluation pipeline encompassing three subtasks: knowledge retrieval, subgraph reasoning, and serendipity exploration. Our experiments reveal that while state-of-the-art LLMs perform well on retrieval, they still struggle to identify genuinely surprising and valuable discoveries, underscoring a significant room for future improvements. Our curated resources and extended version are released at: https://cwru-db-group.github.io/serenQA.
GeoOutageKG: A Multimodal Geospatiotemporal Knowledge Graph for Multiresolution Power Outage Analysis
Jul 30, 2025



Detecting, analyzing, and predicting power outages is crucial for grid risk assessment and disaster mitigation. Numerous outages occur each year, exacerbated by extreme weather events such as hurricanes. Existing outage data are typically reported at the county level, limiting their spatial resolution and making it difficult to capture localized patterns. However, it offers excellent temporal granularity. In contrast, nighttime light satellite image data provides significantly higher spatial resolution and enables a more comprehensive spatial depiction of outages, enhancing the accuracy of assessing the geographic extent and severity of power loss after disaster events. However, these satellite data are only available on a daily basis. Integrating spatiotemporal visual and time-series data sources into a unified knowledge representation can substantially improve power outage detection, analysis, and predictive reasoning. In this paper, we propose GeoOutageKG, a multimodal knowledge graph that integrates diverse data sources, including nighttime light satellite image data, high-resolution spatiotemporal power outage maps, and county-level timeseries outage reports in the U.S. We describe our method for constructing GeoOutageKG by aligning source data with a developed ontology, GeoOutageOnto. Currently, GeoOutageKG includes over 10.6 million individual outage records spanning from 2014 to 2024, 300,000 NTL images spanning from 2012 to 2024, and 15,000 outage maps. GeoOutageKG is a novel, modular and reusable semantic resource that enables robust multimodal data integration. We demonstrate its use through multiresolution analysis of geospatiotemporal power outages.
Generating Skyline Explanations for Graph Neural Networks
May 12, 2025This paper proposes a novel approach to generate subgraph explanations for graph neural networks GNNs that simultaneously optimize multiple measures for explainability. Existing GNN explanation methods often compute subgraphs (called ``explanatory subgraphs'') that optimize a pre-defined, single explainability measure, such as fidelity or conciseness. This can lead to biased explanations that cannot provide a comprehensive explanation to clarify the output of GNN models. We introduce skyline explanation, a GNN explanation paradigm that aims to identify k explanatory subgraphs by simultaneously optimizing multiple explainability measures. (1) We formulate skyline explanation generation as a multi-objective optimization problem, and pursue explanations that approximate a skyline set of explanatory subgraphs. We show the hardness for skyline explanation generation. (2) We design efficient algorithms with an onion-peeling approach that strategically removes edges from neighbors of nodes of interests, and incrementally improves explanations as it explores an interpretation domain, with provable quality guarantees. (3) We further develop an algorithm to diversify explanations to provide more comprehensive perspectives. Using real-world graphs, we empirically verify the effectiveness, efficiency, and scalability of our algorithms.
Inference-friendly Graph Compression for Graph Neural Networks
Apr 17, 2025



Graph Neural Networks (GNNs) have demonstrated promising performance in graph analysis. Nevertheless, the inference process of GNNs remains costly, hindering their applications for large graphs. This paper proposes inference-friendly graph compression (IFGC), a graph compression scheme to accelerate GNNs inference. Given a graph $G$ and a GNN $M$, an IFGC computes a small compressed graph $G_c$, to best preserve the inference results of $M$ over $G$, such that the result can be directly inferred by accessing $G_c$ with no or little decompression cost. (1) We characterize IFGC with a class of inference equivalence relation. The relation captures the node pairs in $G$ that are not distinguishable for GNN inference. (2) We introduce three practical specifications of IFGC for representative GNNs: structural preserving compression (SPGC), which computes $G_c$ that can be directly processed by GNN inference without decompression; ($\alpha$, $r$)-compression, that allows for a configurable trade-off between compression ratio and inference quality, and anchored compression that preserves inference results for specific nodes of interest. For each scheme, we introduce compression and inference algorithms with guarantees of efficiency and quality of the inferred results. We conduct extensive experiments on diverse sets of large-scale graphs, which verifies the effectiveness and efficiency of our graph compression approaches.
Generating Robust Counterfactual Witnesses for Graph Neural Networks
Apr 30, 2024



This paper introduces a new class of explanation structures, called robust counterfactual witnesses (RCWs), to provide robust, both counterfactual and factual explanations for graph neural networks. Given a graph neural network M, a robust counterfactual witness refers to the fraction of a graph G that are counterfactual and factual explanation of the results of M over G, but also remains so for any "disturbed" G by flipping up to k of its node pairs. We establish the hardness results, from tractable results to co-NP-hardness, for verifying and generating robust counterfactual witnesses. We study such structures for GNN-based node classification, and present efficient algorithms to verify and generate RCWs. We also provide a parallel algorithm to verify and generate RCWs for large graphs with scalability guarantees. We experimentally verify our explanation generation process for benchmark datasets, and showcase their applications.
Parallel-friendly Spatio-Temporal Graph Learning for Photovoltaic Degradation Analysis at Scale
Feb 13, 2024



We propose a novel Spatio-Temporal Graph Neural Network empowered trend analysis approach (ST-GTrend) to perform fleet-level performance degradation analysis for Photovoltaic (PV) power networks. PV power stations have become an integral component to the global sustainable energy production landscape. Accurately estimating the performance of PV systems is critical to their feasibility as a power generation technology and as a financial asset. One of the most challenging problems in assessing the Levelized Cost of Energy (LCOE) of a PV system is to understand and estimate the long-term Performance Loss Rate (PLR) for large fleets of PV inverters. ST-GTrend integrates spatio-temporal coherence and graph attention to separate PLR as a long-term "aging" trend from multiple fluctuation terms in the PV input data. To cope with diverse degradation patterns in timeseries, ST-GTrend adopts a paralleled graph autoencoder array to extract aging and fluctuation terms simultaneously. ST-GTrend imposes flatness and smoothness regularization to ensure the disentanglement between aging and fluctuation. To scale the analysis to large PV systems, we also introduce Para-GTrend, a parallel algorithm to accelerate the training and inference of ST-GTrend. We have evaluated ST-GTrend on three large-scale PV datasets, spanning a time period of 10 years. Our results show that ST-GTrend reduces Mean Absolute Percent Error (MAPE) and Euclidean Distances by 34.74% and 33.66% compared to the SOTA methods. Our results demonstrate that Para-GTrend can speed up ST-GTrend by up to 7.92 times. We further verify the generality and effectiveness of ST-GTrend for trend analysis using financial and economic datasets.
View-based Explanations for Graph Neural Networks
Jan 08, 2024



Generating explanations for graph neural networks (GNNs) has been studied to understand their behavior in analytical tasks such as graph classification. Existing approaches aim to understand the overall results of GNNs rather than providing explanations for specific class labels of interest, and may return explanation structures that are hard to access, nor directly queryable.We propose GVEX, a novel paradigm that generates Graph Views for EXplanation. (1) We design a two-tier explanation structure called explanation views. An explanation view consists of a set of graph patterns and a set of induced explanation subgraphs. Given a database G of multiple graphs and a specific class label l assigned by a GNN-based classifier M, it concisely describes the fraction of G that best explains why l is assigned by M. (2) We propose quality measures and formulate an optimization problem to compute optimal explanation views for GNN explanation. We show that the problem is $\Sigma^2_P$-hard. (3) We present two algorithms. The first one follows an explain-and-summarize strategy that first generates high-quality explanation subgraphs which best explain GNNs in terms of feature influence maximization, and then performs a summarization step to generate patterns. We show that this strategy provides an approximation ratio of 1/2. Our second algorithm performs a single-pass to an input node stream in batches to incrementally maintain explanation views, having an anytime quality guarantee of 1/4 approximation. Using real-world benchmark data, we experimentally demonstrate the effectiveness, efficiency, and scalability of GVEX. Through case studies, we showcase the practical applications of GVEX.
Spatio-Temporal Denoising Graph Autoencoders with Data Augmentation for Photovoltaic Timeseries Data Imputation
Feb 21, 2023



The integration of the global Photovoltaic (PV) market with real time data-loggers has enabled large scale PV data analytical pipelines for power forecasting and long-term reliability assessment of PV fleets. Nevertheless, the performance of PV data analysis heavily depends on the quality of PV timeseries data. This paper proposes a novel Spatio-Temporal Denoising Graph Autoencoder (STD-GAE) framework to impute missing PV Power Data. STD-GAE exploits temporal correlation, spatial coherence, and value dependencies from domain knowledge to recover missing data. Experimental results show that STD-GAE can achieve a gain of 43.14% in imputation accuracy and remains less sensitive to missing rate, different seasons, and missing scenarios, compared with state-of-the-art data imputation methods such as MIDA and LRTC-TNN.
Vamsa: Tracking Provenance in Data Science Scripts
Jan 07, 2020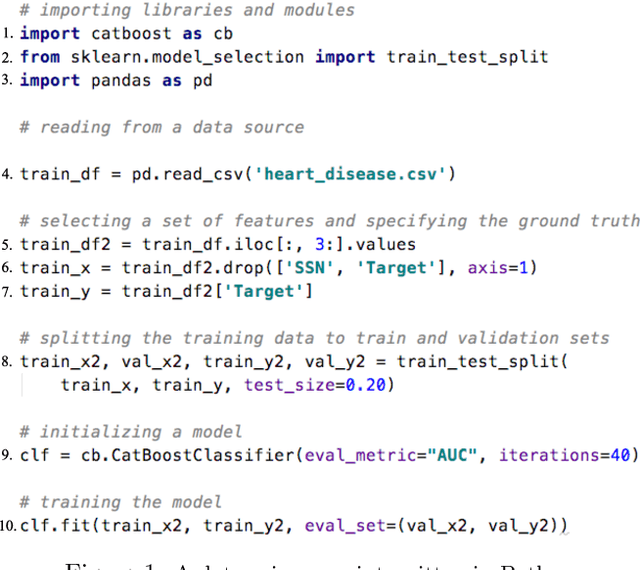

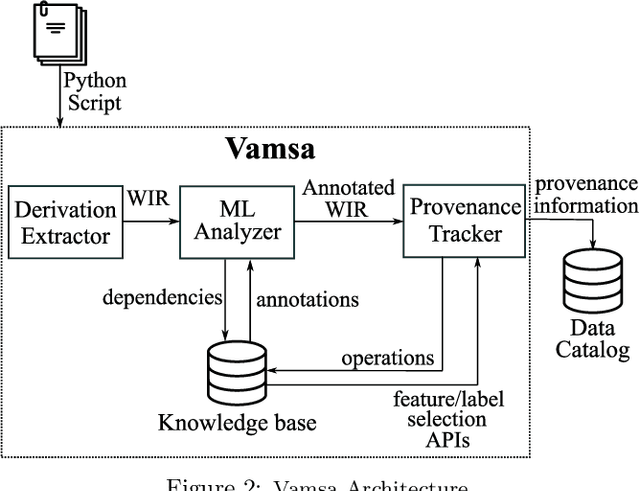

Machine learning (ML) which was initially adopted for search ranking and recommendation systems has firmly moved into the realm of core enterprise operations like sales optimization and preventative healthcare. For such ML applications, often deployed in regulated environments, the standards for user privacy, security, and data governance are substantially higher. This imposes the need for tracking provenance end-to-end, from the data sources used for training ML models to the predictions of the deployed models. In this work, we take a first step towards this direction by introducing the ML provenance tracking problem in the context of data science scripts. The fundamental idea is to automatically identify the relationships between data and ML models and in particular, to track which columns in a dataset have been used to derive the features of a ML model. We discuss the challenges in capturing such provenance information in the context of Python, the most common language used by data scientists. We then, present Vamsa, a modular system that extracts provenance from Python scripts without requiring any changes to the user's code. Using up to 450K real-world data science scripts from Kaggle and publicly available Python notebooks, we verify the effectiveness of Vamsa in terms of coverage, and performance. We also evaluate Vamsa's accuracy on a smaller subset of manually labeled data. Our analysis shows that Vamsa's precision and recall range from 87.5% to 98.3% and its latency is typically in the order of milliseconds for scripts of average size.