 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Role Consistency in Multi-Agent Collaboration via Quantitative Role Clarity
Apr 03, 2026In large language model (LLM)-driven multi-agent systems, disobey role specification (failure to adhere to the defined responsibilities and constraints of an assigned role, potentially leading to an agent behaving like another) is a major failure mode \cite{DBLP:journals/corr/abs-2503-13657}. To address this issue, in the present paper, we propose a quantitative role clarity to improve role consistency. Firstly, we construct a role assignment matrix $S(φ)=[s_{ij}(φ)]$, where $s_{ij}(φ)$ is the semantic similarity between the $i$-th agent's behavior trajectory and the $j$-th agent's role description. Then we define role clarity matrix $M(φ)$ as $\text{softmax}(S(φ))-I$, where $\text{softmax}(S(φ))$ is a row-wise softmax of $S(φ)$ and $I$ is the identity matrix. The Frobenius norm of $M(φ)$ quantifies the alignment between agents' role descriptions and their behaviors trajectory. Moreover, we employ the role clarity matrix as a regularizer during lightweight fine-tuning to improve role consistency, thereby improving end-to-end task performance. Experiments on the ChatDev multi-agent system show that our method substantially improves role consistency and task performance: with Qwen and Llama, the role overstepping rate decreases from $46.4\%$ to $8.4\%$ and from $43.4\%$ to $0.2\%$, respectively, and the role clarity score increases from $0.5328$ to $0.9097$ and from $0.5007$ to $0.8530$, respectively, the task success rate increases from $0.6769$ to $0.6909$ and from $0.6174$ to $0.6763$, respectively.
The Implicit Regularization of Momentum Gradient Descent with Early Stopping
Jan 14, 2022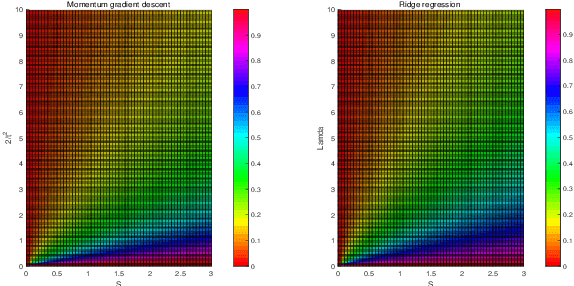
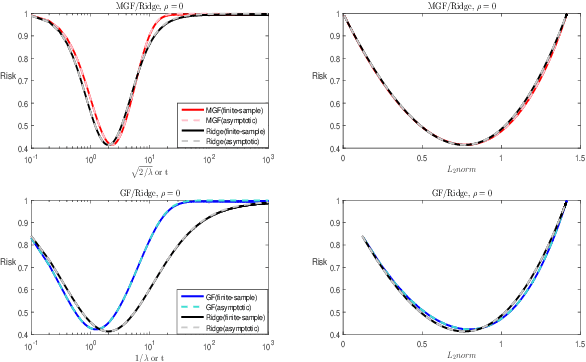
The study on the implicit regularization induced by gradient-based optimization is a longstanding pursuit. In the present paper, we characterize the implicit regularization of momentum gradient descent (MGD) with early stopping by comparing with the explicit $\ell_2$-regularization (ridge). In details, we study MGD in the continuous-time view, so-called momentum gradient flow (MGF), and show that its tendency is closer to ridge than the gradient descent (GD) [Ali et al., 2019] for least squares regression. Moreover, we prove that, under the calibration $t=\sqrt{2/\lambda}$, where $t$ is the time parameter in MGF and $\lambda$ is the tuning parameter in ridge regression, the risk of MGF is no more than 1.54 times that of ridge. In particular, the relative Bayes risk of MGF to ridge is between 1 and 1.035 under the optimal tuning. The numerical experiments support our theoretical results strongly.