 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating Search Intent Bias in Learning to Rank
Feb 11, 2020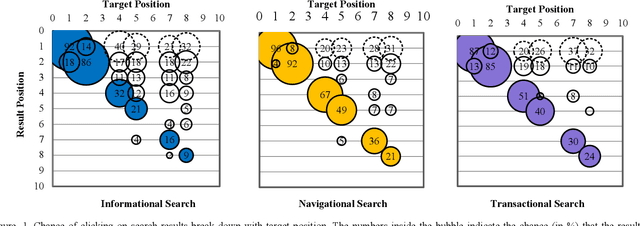
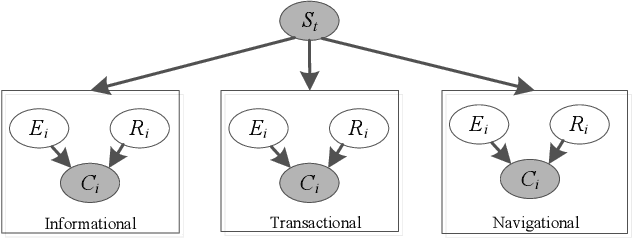
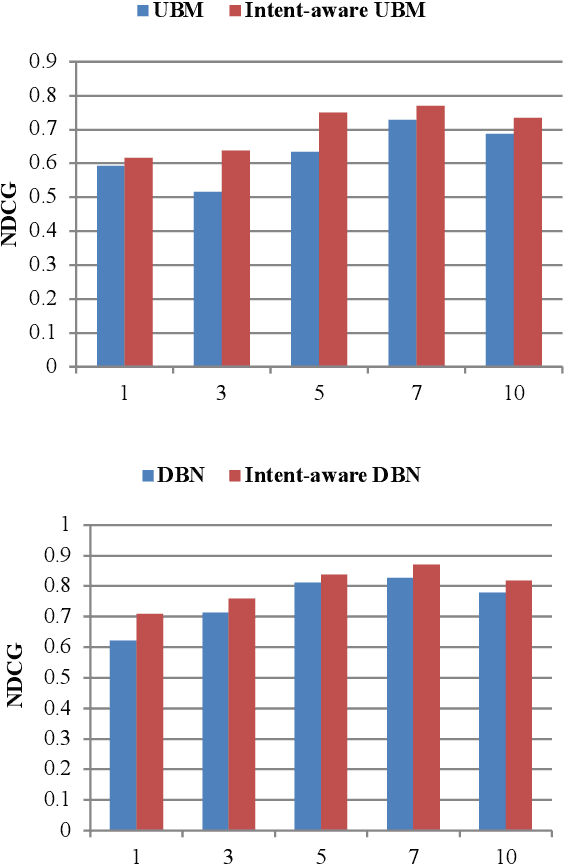
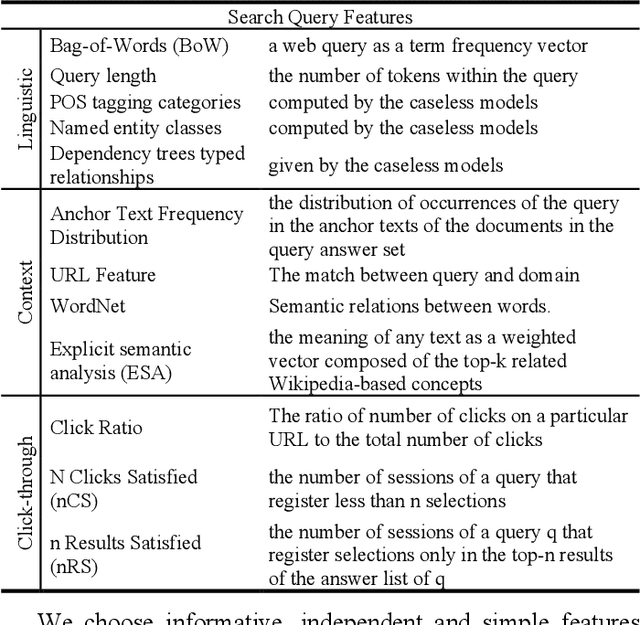
Click-through data has proven to be a valuable resource for improving search-ranking quality. Search engines can easily collect click data, but biases introduced in the data can make it difficult to use the data effectively. In order to measure the effects of biases, many click models have been proposed in the literature. However, none of the models can explain the observation that users with different search intent (e.g., informational, navigational, etc.) have different click behaviors. In this paper, we study how differences in user search intent can influence click activities and determined that there exists a bias between user search intent and the relevance of the document relevance. Based on this observation, we propose a search intent bias hypothesis that can be applied to most existing click models to improve their ability to learn unbiased relevance. Experimental results demonstrate that after adopting the search intent hypothesis, click models can better interpret user clicks and substantially improve retrieval performance.
Conversational Structure Aware and Context Sensitive Topic Model for Online Discussions
Feb 06, 2020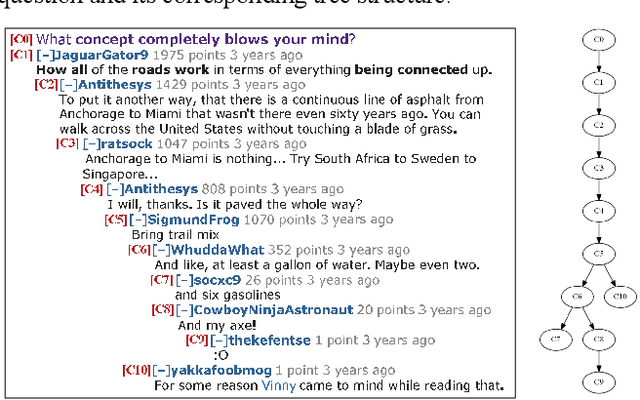
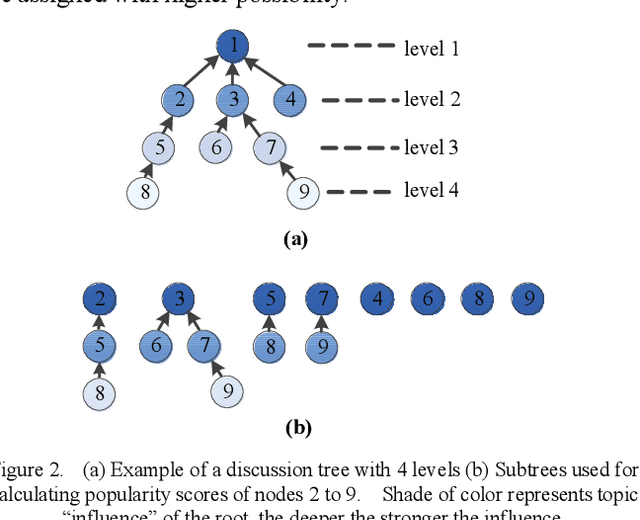
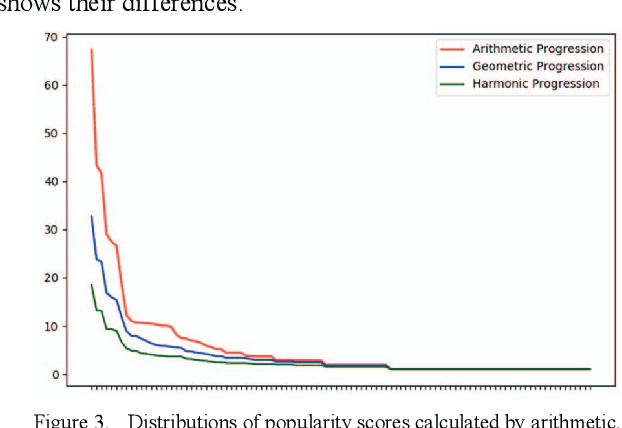
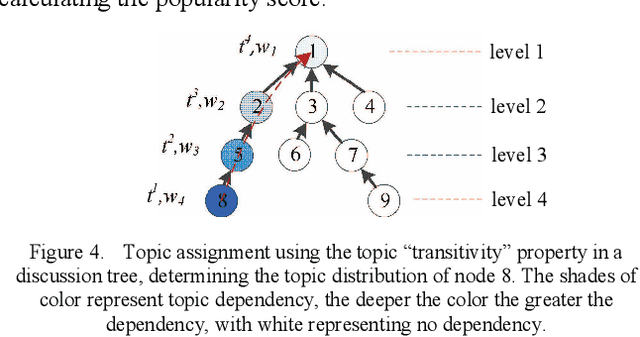
Millions of online discussions are generated everyday on social media platforms. Topic modelling is an efficient way of better understanding large text datasets at scale. Conventional topic models have had limited success in online discussions, and to overcome their limitations, we use the discussion thread tree structure and propose a "popularity" metric to quantify the number of replies to a comment to extend the frequency of word occurrences, and the "transitivity" concept to characterize topic dependency among nodes in a nested discussion thread. We build a Conversational Structure Aware Topic Model (CSATM) based on popularity and transitivity to infer topics and their assignments to comments. Experiments on real forum datasets are used to demonstrate improved performance for topic extraction with six different measurements of coherence and impressive accuracy for topic assignments.
Context Aware Image Annotation in Active Learning
Feb 06, 2020
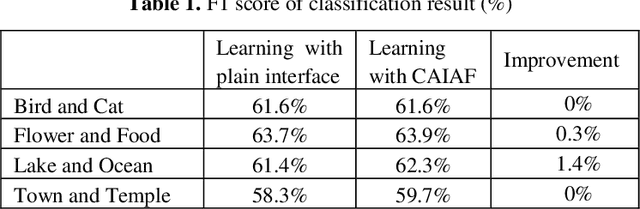

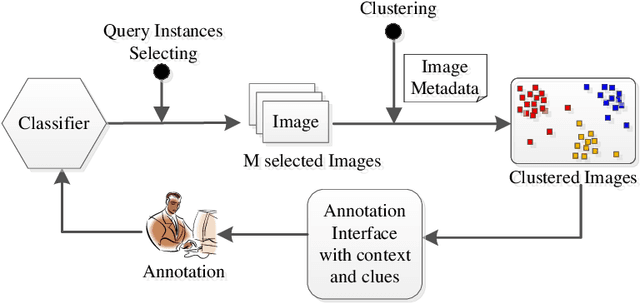
Image annotation for active learning is labor-intensive. Various automatic and semi-automatic labeling methods are proposed to save the labeling cost, but a reduction in the number of labeled instances does not guarantee a reduction in cost because the queries that are most valuable to the learner may be the most difficult or ambiguous cases, and therefore the most expensive for an oracle to label accurately. In this paper, we try to solve this problem by using image metadata to offer the oracle more clues about the image during annotation process. We propose a Context Aware Image Annotation Framework (CAIAF) that uses image metadata as similarity metric to cluster images into groups for annotation. We also present useful metadata information as context for each image on the annotation interface. Experiments show that it reduces that annotation cost with CAIAF compared to the conventional framework, while maintaining a high classification performance.
* arXiv admin note: text overlap with arXiv:1508.07647, arXiv:1207.3809 by other authors
Knowledge-guided Text Structuring in Clinical Trials
Dec 28, 2019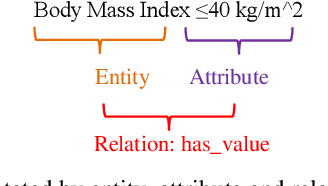

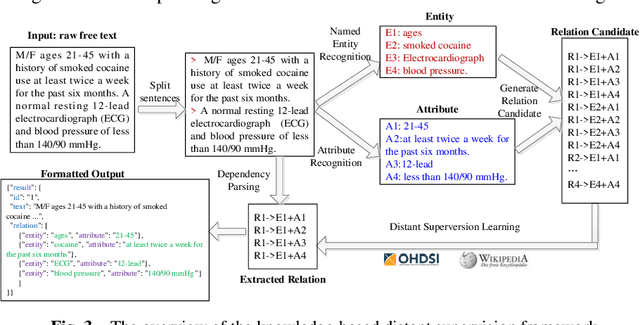
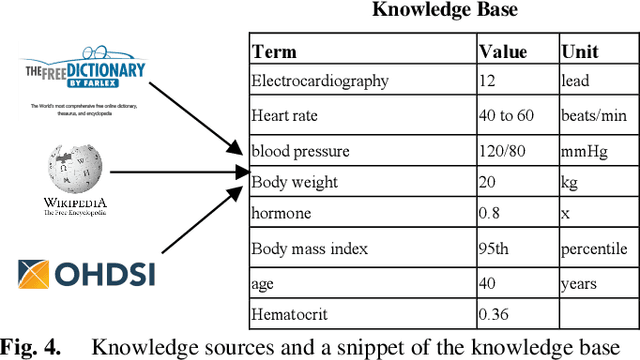
Clinical trial records are variable resources or the analysis of patients and diseases. Information extraction from free text such as eligibility criteria and summary of results and conclusions in clinical trials would better support computer-based eligibility query formulation and electronic patient screening. Previous research has focused on extracting information from eligibility criteria, with usually a single pair of medical entity and attribute, but seldom considering other kinds of free text with multiple entities, attributes and relations that are more complex for parsing. In this paper, we propose a knowledge-guided text structuring framework with an automatically generated knowledge base as training corpus and word dependency relations as context information to transfer free text into formal, computer-interpretable representations. Experimental results show that our method can achieve overall high precision and recall, demonstrating the effectiveness and efficiency of the proposed method.