 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOctopus: Agentic Multimodal Reasoning with Six-Capability Orchestration
Nov 19, 2025Existing multimodal reasoning models and frameworks suffer from fundamental architectural limitations: most lack the human-like ability to autonomously explore diverse reasoning pathways-whether in direct inference, tool-driven visual exploration, programmatic visual manipulation, or intrinsic visual imagination. Consequently, they struggle to adapt to dynamically changing capability requirements in real-world tasks. Meanwhile, humans exhibit a complementary set of thinking abilities when addressing such tasks, whereas existing methods typically cover only a subset of these dimensions. Inspired by this, we propose Octopus: Agentic Multimodal Reasoning with Six-Capability Orchestration, a new paradigm for multimodal agentic reasoning. We define six core capabilities essential for multimodal reasoning and organize a comprehensive evaluation benchmark, Octopus-Bench, accordingly. Octopus is capable of autonomously exploring during reasoning and dynamically selecting the most appropriate capability based on the current state. Experimental results show that Octopus achieves the best performance on the vast majority of tasks in Octopus-Bench, highlighting the crucial role of capability coordination in agentic multimodal reasoning.
Design an Editable Speech-to-Sign-Language Transformer System: A Human-Centered AI Approach
Jun 17, 2025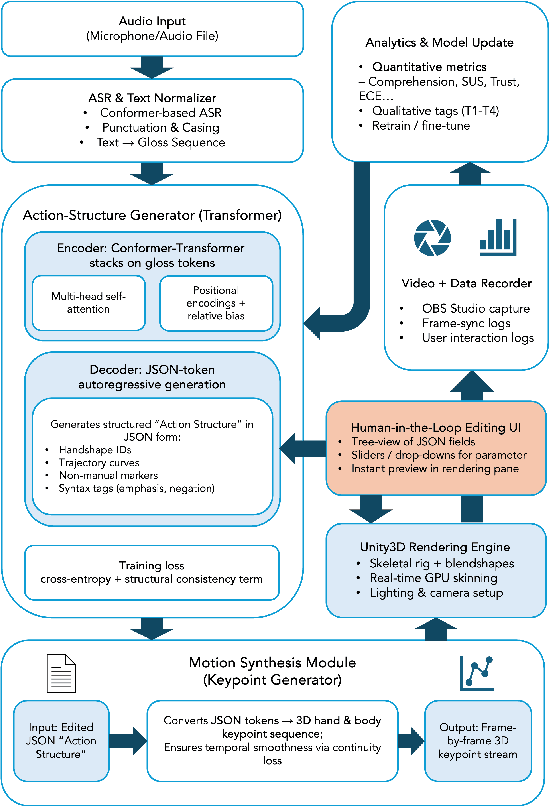

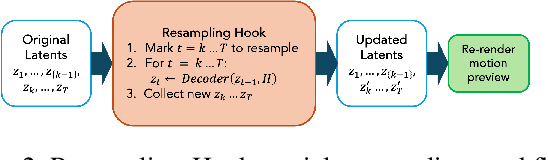
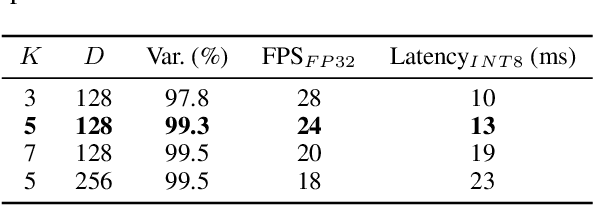
This paper presents a human-centered, real-time, user-adaptive speech-to-sign language animation system that integrates Transformer-based motion generation with a transparent, user-editable JSON intermediate layer. The framework overcomes key limitations in prior sign language technologies by enabling direct user inspection and modification of sign segments, thus enhancing naturalness, expressiveness, and user agency. Leveraging a streaming Conformer encoder and autoregressive Transformer-MDN decoder, the system synchronizes spoken input into upper-body and facial motion for 3D avatar rendering. Edits and user ratings feed into a human-in-the-loop optimization loop for continuous improvement. Experiments with 20 deaf signers and 5 interpreters show that the editable interface and participatory feedback significantly improve comprehension, naturalness, usability, and trust, while lowering cognitive load. With sub-20 ms per-frame inference on standard hardware, the system is ready for real-time communication and education. This work illustrates how technical and participatory innovation together enable accessible, explainable, and user-adaptive AI for sign language technology.