 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Semantic Aggregation Leveraging Foundation Model for Generalizable Medical Image Segmentation
Sep 10, 2025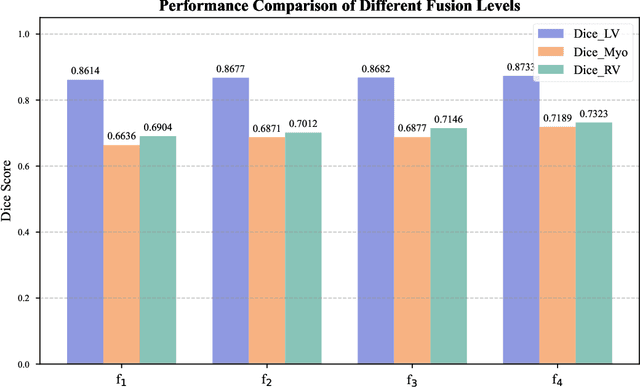
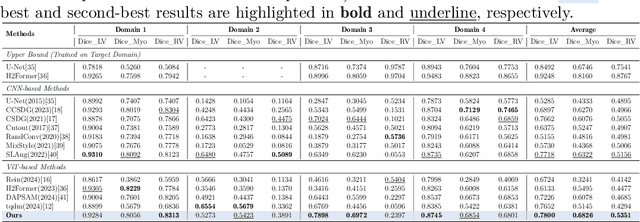
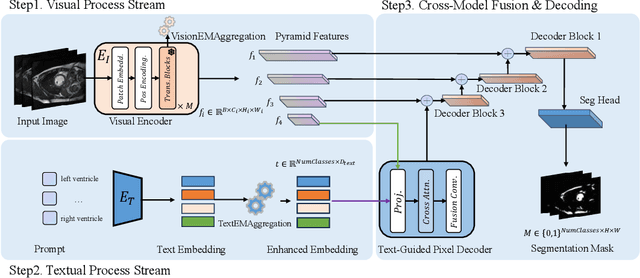
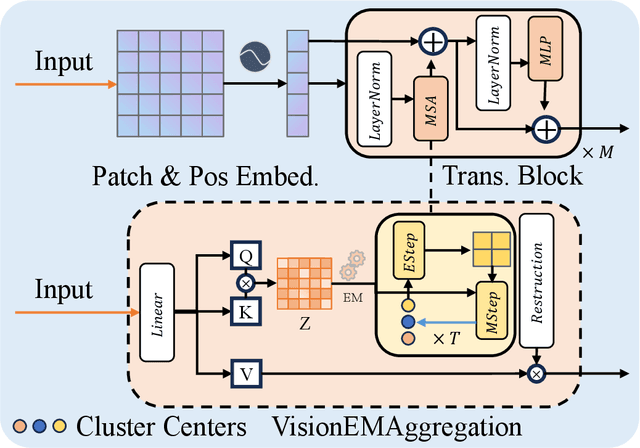
Multimodal models have achieved remarkable success in natural image segmentation, yet they often underperform when applied to the medical domain. Through extensive study, we attribute this performance gap to the challenges of multimodal fusion, primarily the significant semantic gap between abstract textual prompts and fine-grained medical visual features, as well as the resulting feature dispersion. To address these issues, we revisit the problem from the perspective of semantic aggregation. Specifically, we propose an Expectation-Maximization (EM) Aggregation mechanism and a Text-Guided Pixel Decoder. The former mitigates feature dispersion by dynamically clustering features into compact semantic centers to enhance cross-modal correspondence. The latter is designed to bridge the semantic gap by leveraging domain-invariant textual knowledge to effectively guide deep visual representations. The synergy between these two mechanisms significantly improves the model's generalization ability. Extensive experiments on public cardiac and fundus datasets demonstrate that our method consistently outperforms existing SOTA approaches across multiple domain generalization benchmarks.