 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Where Things Are to What They Are For: Benchmarking Spatial-Functional Intelligence in Multimodal LLMs
May 04, 2026Human-level agentic intelligence extends beyond low-level geometric perception, evolving from recognizing where things are to understanding what they are for. While existing benchmarks effectively evaluate the geometric perception capabilities of multimodal large language models (MLLMs), they fall short of probing the higher-order cognitive abilities required for grounded intelligence. To address this gap, we introduce the Spatial-Functional Intelligence Benchmark (SFI-Bench), a video-based benchmark with over 1,500 expert-annotated questions derived from diverse egocentric indoor video scans. SFI-Bench systematically evaluates two complementary dimensions of advanced reasoning: (1) Structured Spatial Reasoning, which requires understanding complex layouts and forming coherent spatial representations, and (2) Functional Reasoning, which involves inferring object affordances and their context-dependent utility. The benchmark includes tasks such as conditional counting, multi-hop relational reasoning, functional pairing, and knowledge-grounded troubleshooting, directly challenging models to integrate perception, memory, and inference. Our experiments reveal that current MLLMs consistently struggle to combine spatial memory with functional reasoning and external knowledge, highlighting a critical bottleneck in achieving grounded intelligence. SFI-Bench therefore provides a diagnostic tool for measuring progress toward more cognitively capable and truly grounded multimodal agents.
Leveraging an Efficient and Semantic Location Embedding to Seek New Ports of Bike Share Services
Nov 06, 2020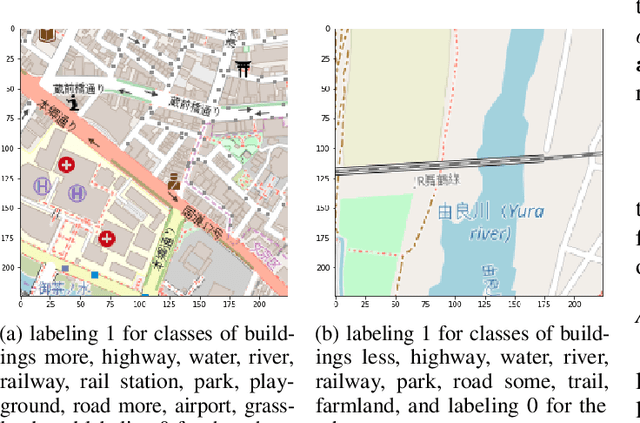
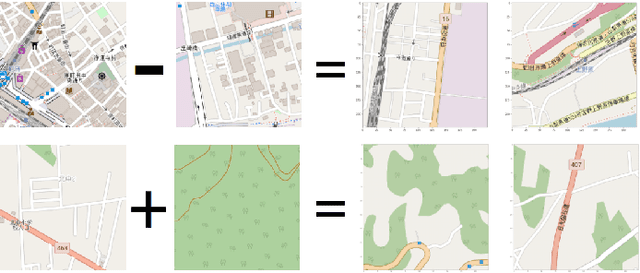
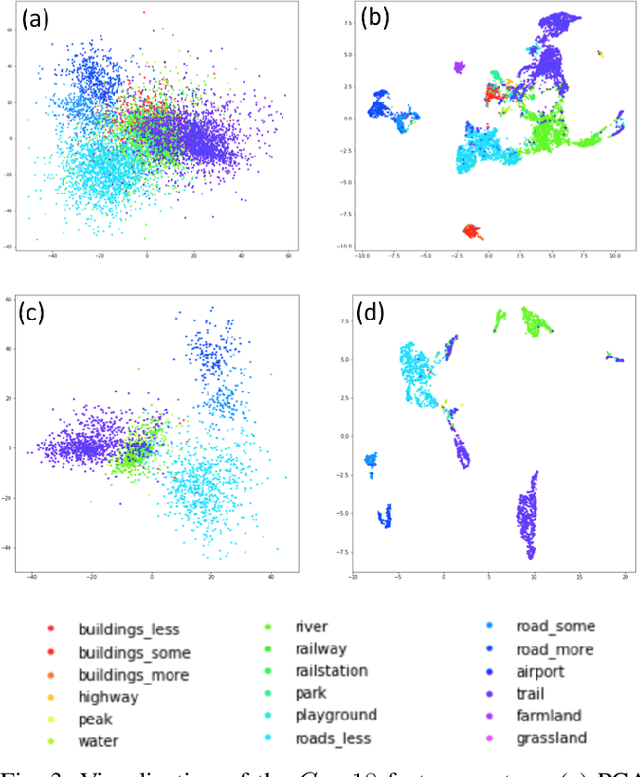
For short distance traveling in crowded urban areas, bike share services are becoming popular owing to the flexibility and convenience. To expand the service coverage, one of the key tasks is to seek new service ports, which requires to well understand the underlying features of the existing service ports. In this paper, we propose a new model, named for Efficient and Semantic Location Embedding (ESLE), which carries both geospatial and semantic information of the geo-locations. To generate ESLE, we first train a multi-label model with a deep Convolutional Neural Network (CNN) by feeding the static map-tile images and then extract location embedding vectors from the model. Compared to most recent relevant literature, ESLE is not only much cheaper in computation, but also easier to interpret via a systematic semantic analysis. Finally, we apply ESLE to seek new service ports for NTT DOCOMO's bike share services operated in Japan. The initial results demonstrate the effectiveness of ESLE, and provide a few insights that might be difficult to discover by using the conventional approaches.