 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpaired Cross-Domain Calibration of DMSP to VIIRS Nighttime Light Data Based on CUT Network
Mar 17, 2026Defense Meteorological Satellite Program (DMSP-OLS) and Suomi National Polar-orbiting Partnership (SNPP-VIIRS) nighttime light (NTL) data are vital for monitoring urbanization, yet sensor incompatibilities hinder long-term analysis. This study proposes a cross-sensor calibration method using Contrastive Unpaired Translation (CUT) network to transform DMSP data into VIIRS-like format, correcting DMSP defects. The method employs multilayer patch-wise contrastive learning to maximize mutual information between corresponding patches, preserving content consistency while learning cross-domain similarity. Utilizing 2012-2013 overlapping data for training, the network processes 1992-2013 DMSP imagery to generate enhanced VIIRS-style raster data. Validation results demonstrate that generated VIIRS-like data exhibits high consistency with actual VIIRS observations (R-squared greater than 0.87) and socioeconomic indicators. This approach effectively resolves cross-sensor data fusion issues and calibrates DMSP defects, providing reliable attempt for extended NTL time-series.
UnPWC-SVDLO: Multi-SVD on PointPWC for Unsupervised Lidar Odometry
May 17, 2022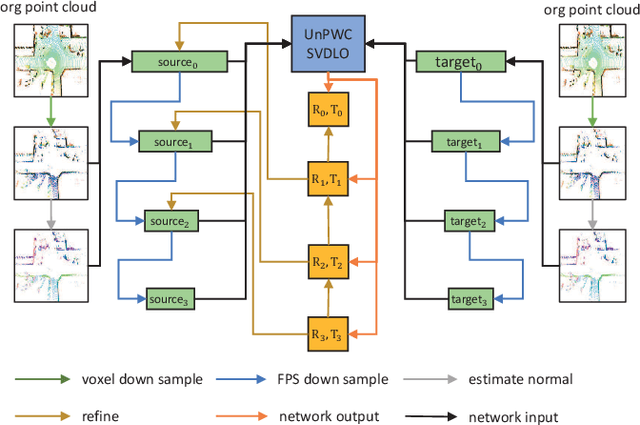
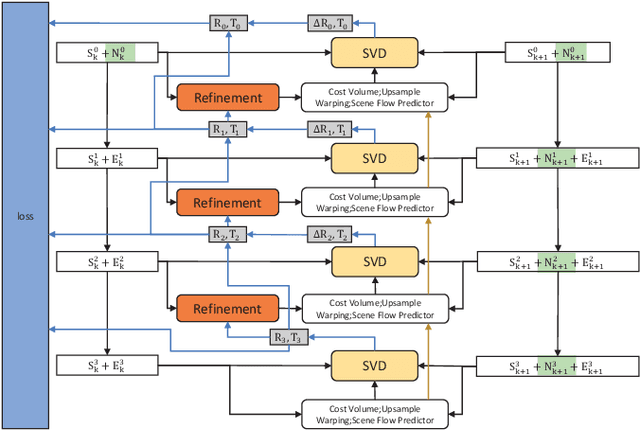
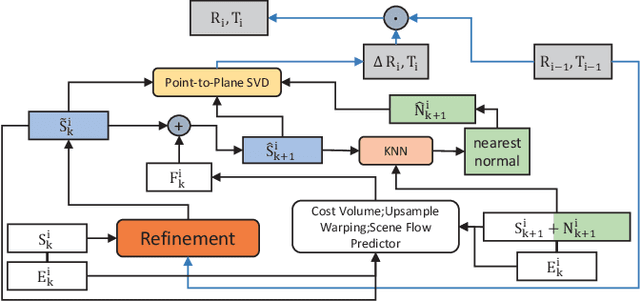
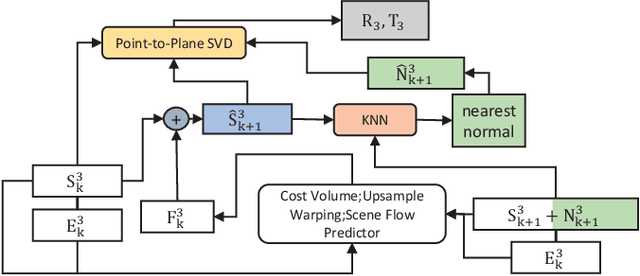
High-precision lidar odomety is an essential part of autonomous driving. In recent years, deep learning methods have been widely used in lidar odomety tasks, but most of the current methods only extract the global features of the point clouds. It is impossible to obtain more detailed point-level features in this way. In addition, only the fully connected layer is used to estimate the pose. The fully connected layer has achieved obvious results in the classification task, but the changes in pose are a continuous rather than discrete process, high-precision pose estimation can not be obtained only by using the fully connected layer. Our method avoids problems mentioned above. We use PointPWC as our backbone network. PointPWC is originally used for scene flow estimation. The scene flow estimation task has a strong correlation with lidar odomety. Traget point clouds can be obtained by adding the scene flow and source point clouds. We can achieve the pose directly through ICP algorithm solved by SVD, and the fully connected layer is no longer used. PointPWC extracts point-level features from point clouds with different sampling levels, which solves the problem of too rough feature extraction. We conduct experiments on KITTI, Ford Campus Vision and Lidar DataSe and Apollo-SouthBay Dataset. Our result is comparable with the state-of-the-art unsupervised deep learing method SelfVoxeLO.
UnDeepLIO: Unsupervised Deep Lidar-Inertial Odometry
Sep 03, 2021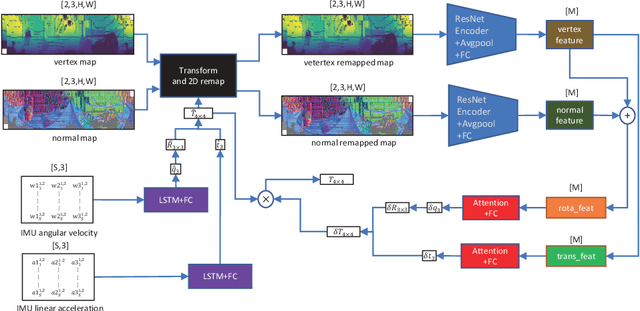
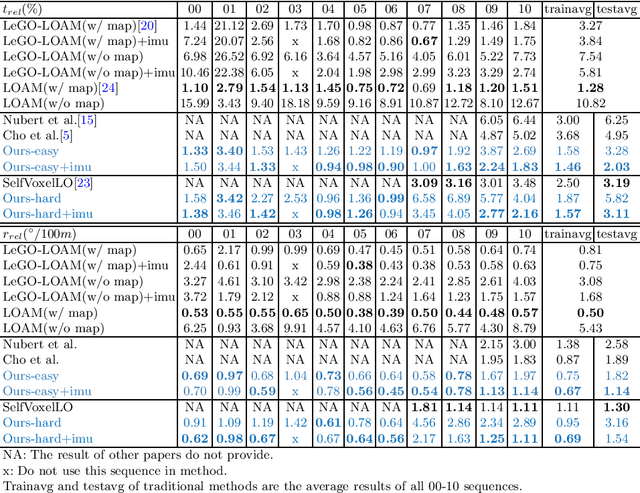
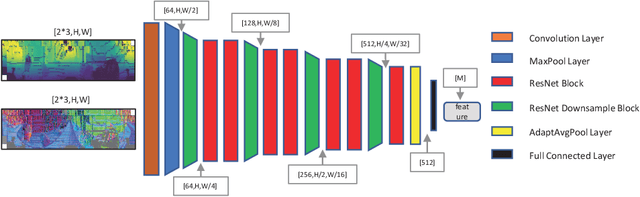

Extensive research efforts have been dedicated to deep learning based odometry. Nonetheless, few efforts are made on the unsupervised deep lidar odometry. In this paper, we design a novel framework for unsupervised lidar odometry with the IMU, which is never used in other deep methods. First, a pair of siamese LSTMs are used to obtain the initial pose from the linear acceleration and angular velocity of IMU. With the initial pose, we perform the rigid transform on the current frame and align it closer to the last frame. Then, we extract vertex and normal features from the transformed point clouds and its normals. Next a two-branches attention modules are proposed to estimate residual rotation and translation from the extracted vertex and normal features, respectively. Finally, our model outputs the sum of initial and residual poses as the final pose. For unsupervised training, we introduce an unsupervised loss function which is employed on the voxelized point clouds. The proposed approach is evaluated on the KITTI odometry estimation benchmark and achieves comparable performances against other state-of-the-art methods.