 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNBQ: Next-Best-Question for Dynamic Profiling
May 30, 2026Many real-world conversational settings for knowledge discovery, including podcasts, hiring screens, and marketplaces, require a purpose-driven understanding of a person. We study the Next-Best-Question (NBQ) problem: at each turn, an interviewer should ask the question with the highest expected information gain given what has already been learned and the conversation goal. We propose NBQ, a plug-and-play framework that seeds a diverse pool of candidate questions, maintains a compact and continuously updated user state, adaptively selects the next question within a turn budget, and distills the resulting free-form dialogue into a structured vector-based user profile. As a demanding application, we instantiate NBQ for reciprocal matchmaking, where compatibility must be mutual and each person is modeled by both self-description and counterpart-preference representations. To support large-scale matching, we further introduce QuickMatch, an efficient retrieval layer that recasts reciprocal matching from quadratic pairwise scoring to approximate vector search. Experiments show that NBQ improves user profiling quality by up to 13.6% and 14.0% in AC@T and AR@T, respectively, while QuickMatch accelerates retrieval by up to 22.9x with recall up to 0.989.
GEM-Bench: A Benchmark for Ad-Injected Response Generation within Generative Engine Marketing
Sep 17, 2025



Generative Engine Marketing (GEM) is an emerging ecosystem for monetizing generative engines, such as LLM-based chatbots, by seamlessly integrating relevant advertisements into their responses. At the core of GEM lies the generation and evaluation of ad-injected responses. However, existing benchmarks are not specifically designed for this purpose, which limits future research. To address this gap, we propose GEM-Bench, the first comprehensive benchmark for ad-injected response generation in GEM. GEM-Bench includes three curated datasets covering both chatbot and search scenarios, a metric ontology that captures multiple dimensions of user satisfaction and engagement, and several baseline solutions implemented within an extensible multi-agent framework. Our preliminary results indicate that, while simple prompt-based methods achieve reasonable engagement such as click-through rate, they often reduce user satisfaction. In contrast, approaches that insert ads based on pre-generated ad-free responses help mitigate this issue but introduce additional overhead. These findings highlight the need for future research on designing more effective and efficient solutions for generating ad-injected responses in GEM.
You Are What You Bought: Generating Customer Personas for E-commerce Applications
Apr 24, 2025In e-commerce, user representations are essential for various applications. Existing methods often use deep learning techniques to convert customer behaviors into implicit embeddings. However, these embeddings are difficult to understand and integrate with external knowledge, limiting the effectiveness of applications such as customer segmentation, search navigation, and product recommendations. To address this, our paper introduces the concept of the customer persona. Condensed from a customer's numerous purchasing histories, a customer persona provides a multi-faceted and human-readable characterization of specific purchase behaviors and preferences, such as Busy Parents or Bargain Hunters. This work then focuses on representing each customer by multiple personas from a predefined set, achieving readable and informative explicit user representations. To this end, we propose an effective and efficient solution GPLR. To ensure effectiveness, GPLR leverages pre-trained LLMs to infer personas for customers. To reduce overhead, GPLR applies LLM-based labeling to only a fraction of users and utilizes a random walk technique to predict personas for the remaining customers. We further propose RevAff, which provides an absolute error $\epsilon$ guarantee while improving the time complexity of the exact solution by a factor of at least $O(\frac{\epsilon\cdot|E|N}{|E|+N\log N})$, where $N$ represents the number of customers and products, and $E$ represents the interactions between them. We evaluate the performance of our persona-based representation in terms of accuracy and robustness for recommendation and customer segmentation tasks using three real-world e-commerce datasets. Most notably, we find that integrating customer persona representations improves the state-of-the-art graph convolution-based recommendation model by up to 12% in terms of NDCG@K and F1-Score@K.
A Privacy-preserving Distributed Training Framework for Cooperative Multi-agent Deep Reinforcement Learning
Sep 30, 2021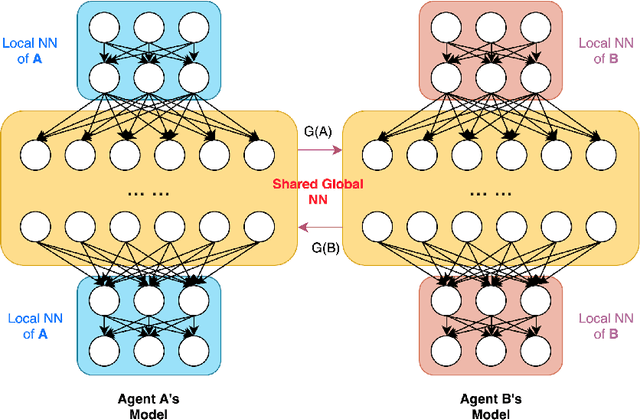
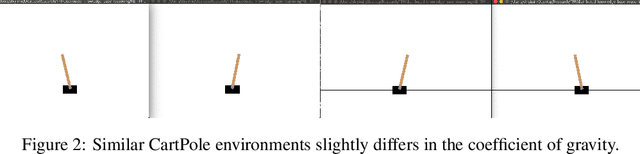
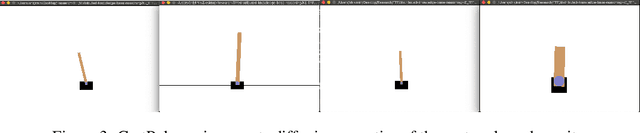
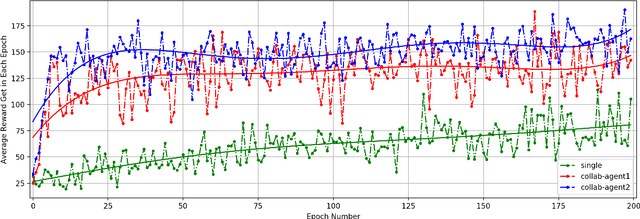
Deep Reinforcement Learning (DRL) sometimes needs a large amount of data to converge in the training procedure and in some cases, each action of the agent may produce regret. This barrier naturally motivates different data sets or environment owners to cooperate to share their knowledge and train their agents more efficiently. However, it raises privacy concerns if we directly merge the raw data from different owners. To solve this problem, we proposed a new Deep Neural Network (DNN) architecture with both global NN and local NN, and a distributed training framework. We allow the global weights to be updated by all the collaborator agents while the local weights are only updated by the agent they belong to. In this way, we hope the global weighs can share the common knowledge among these collaborators while the local NN can keep the specialized properties and ensure the agent to be compatible with its specific environment. Experiments show that the framework can efficiently help agents in the same or similar environments to collaborate in their training process and gain a higher convergence rate and better performance.
Improving Target-driven Visual Navigation with Attention on 3D Spatial Relationships
Apr 29, 2020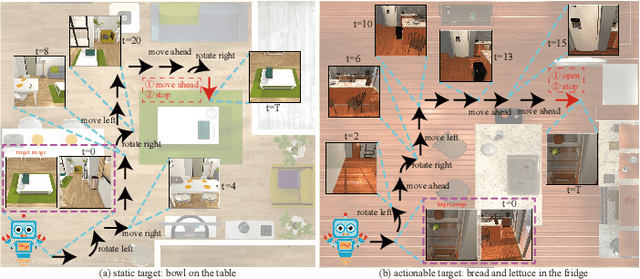
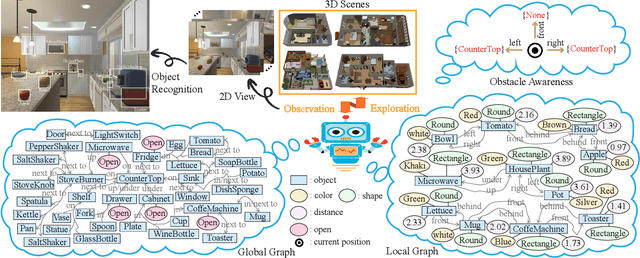
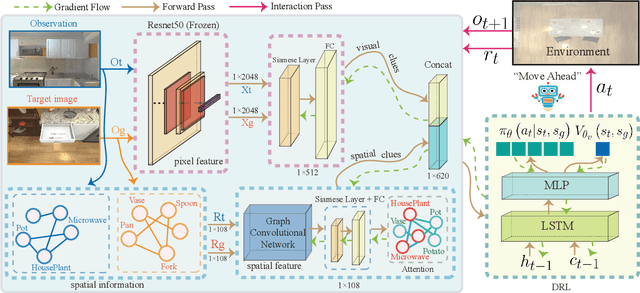
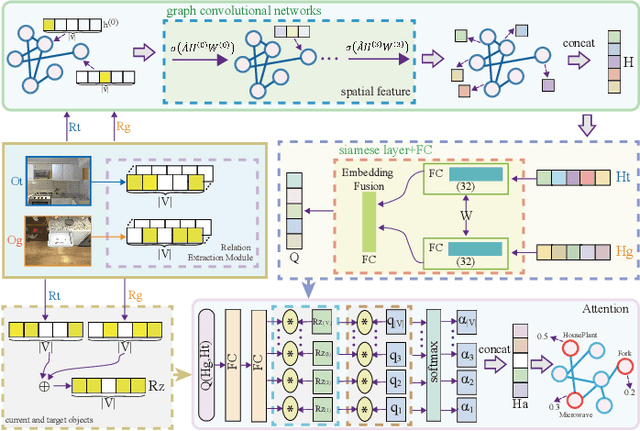
Embodied artificial intelligence (AI) tasks shift from tasks focusing on internet images to active settings involving embodied agents that perceive and act within 3D environments. In this paper, we investigate the target-driven visual navigation using deep reinforcement learning (DRL) in 3D indoor scenes, whose navigation task aims to train an agent that can intelligently make a series of decisions to arrive at a pre-specified target location from any possible starting positions only based on egocentric views. However, most navigation methods currently struggle against several challenging problems, such as data efficiency, automatic obstacle avoidance, and generalization. Generalization problem means that agent does not have the ability to transfer navigation skills learned from previous experience to unseen targets and scenes. To address these issues, we incorporate two designs into classic DRL framework: attention on 3D knowledge graph (KG) and target skill extension (TSE) module. On the one hand, our proposed method combines visual features and 3D spatial representations to learn navigation policy. On the other hand, TSE module is used to generate sub-targets which allow agent to learn from failures. Specifically, our 3D spatial relationships are encoded through recently popular graph convolutional network (GCN). Considering the real world settings, our work also considers open action and adds actionable targets into conventional navigation situations. Those more difficult settings are applied to test whether DRL agent really understand its task, navigating environment, and can carry out reasoning. Our experiments, performed in the AI2-THOR, show that our model outperforms the baselines in both SR and SPL metrics, and improves generalization ability across targets and scenes.