 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient On-policy Visual-RL via Stochastic Decoupled Policy Gradient
May 26, 2026We present the stochastic decoupled policy gradient (SDPG), a lightweight visual reinforcement learning (RL) method that trains diverse visuomotor control policies end-to-end within a few hours on a single NVIDIA RTX 4080 GPU. SDPG estimates policy gradients via random perturbations of trajectory rollouts, requiring orders of magnitude fewer batch-rendered environments and substantially reducing compute and memory overhead. On visual MuJoCo benchmarks, SDPG consistently outperforms baseline methods in training time, memory usage, and rewards. Finally, to support future research, we introduce a suite of realistic visual robotics benchmarks spanning dexterous manipulation, challenging locomotion, and demonstrate effective sim-to-real transfer on physical hardware.
Asymptotically Optimal Ergodic Coverage on Generalized Motion Fields
May 13, 2026Autonomous robotic exploration in remote and extreme environments allows scientists to model complex transport phenomena and collective behaviors described by continuously deforming flow fields. Although these environments are naturally modeled as time-varying domains, most adaptive exploration methods assume static environments and fail to provide adequate coverage or satisfy any formal guarantees. This is especially the case in oceanography where autonomous underwater systems (UxS) have highly restrictive compute and payload requirements that necessitate path planning methods that yield robust data collection strategies in open-loop and underactuated settings. In this work, to address the aforementioned issues, we propose to formulate adaptive search as an ergodic coverage problem and investigate certifying coverage in the ergodic sense over evolving domains with flow-induced dynamics. We expand upon recent work demonstrating maximum mean discrepancy (MMD) as a functional ergodic metric, and derive a flow-adaptive formulation that explicitly accounts for domain evolution within the coverage objective. We show that this approach preserves ergodic coverage guarantees in ambient flows and enables effective exploration in under-actuated, and even open-loop planning settings by integrating environment dynamics. Experiments validate that our method generalizes to diverse spatiotemporal processes including ocean exploration, and tracking human and cattle movement. Physical experiments on aerial and legged robotic platforms validate our ability to obtain ergodic coverage in non-convex, flow-restricted environments while respecting robot dynamics.
Sample-Based Hybrid Mode Control: Asymptotically Optimal Switching of Algorithmic and Non-Differentiable Control Modes
Oct 21, 2025This paper investigates a sample-based solution to the hybrid mode control problem across non-differentiable and algorithmic hybrid modes. Our approach reasons about a set of hybrid control modes as an integer-based optimization problem where we select what mode to apply, when to switch to another mode, and the duration for which we are in a given control mode. A sample-based variation is derived to efficiently search the integer domain for optimal solutions. We find our formulation yields strong performance guarantees that can be applied to a number of robotics-related tasks. In addition, our approach is able to synthesize complex algorithms and policies to compound behaviors and achieve challenging tasks. Last, we demonstrate the effectiveness of our approach in real-world robotic examples that require reactive switching between long-term planning and high-frequency control.
Accelerating Visual-Policy Learning through Parallel Differentiable Simulation
May 15, 2025In this work, we propose a computationally efficient algorithm for visual policy learning that leverages differentiable simulation and first-order analytical policy gradients. Our approach decouple the rendering process from the computation graph, enabling seamless integration with existing differentiable simulation ecosystems without the need for specialized differentiable rendering software. This decoupling not only reduces computational and memory overhead but also effectively attenuates the policy gradient norm, leading to more stable and smoother optimization. We evaluate our method on standard visual control benchmarks using modern GPU-accelerated simulation. Experiments show that our approach significantly reduces wall-clock training time and consistently outperforms all baseline methods in terms of final returns. Notably, on complex tasks such as humanoid locomotion, our method achieves a $4\times$ improvement in final return, and successfully learns a humanoid running policy within 4 hours on a single GPU.
An Energy-Saving Snake Locomotion Gait Policy Using Deep Reinforcement Learning
Mar 08, 2021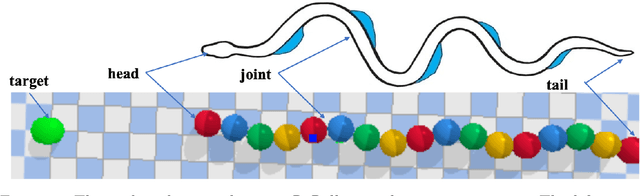


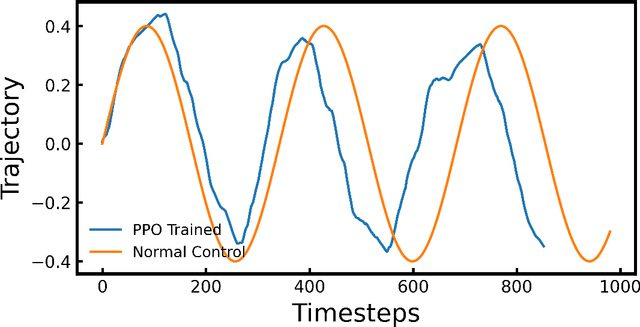
Snake robots, comprised of sequentially connected joint actuators, have recently gained increasing attention in the industrial field, like life detection in narrow space. Such robot can navigate through the complex environment via the cooperation of multiple motors located on the backbone. However, controlling the robots under unknown environment is challenging, and conventional control strategies can be energy inefficient or even fail to navigate to the destination. In this work, a snake locomotion gait policy is developed via deep reinforcement learning (DRL) for energy-efficient control. We apply proximal policy optimization (PPO) to each joint motor parameterized by angular velocity and the DRL agent learns the standard serpenoid curve at each timestep. The robot simulator and task environment are built upon PyBullet. Comparing to conventional control strategies, the snake robots controlled by the trained PPO agent can achieve faster movement and more energy-efficient locomotion gait. This work demonstrates that DRL provides an energy-efficient solution for robot control.