 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Unsupervised Clean-to-Rendered Guitar Tone Transformation Using GANs and Integrated Unaligned Clean Data
Jun 22, 2024



Recent years have seen increasing interest in applying deep learning methods to the modeling of guitar amplifiers or effect pedals. Existing methods are mainly based on the supervised approach, requiring temporally-aligned data pairs of unprocessed and rendered audio. However, this approach does not scale well, due to the complicated process involved in creating the data pairs. A very recent work done by Wright et al. has explored the potential of leveraging unpaired data for training, using a generative adversarial network (GAN)-based framework. This paper extends their work by using more advanced discriminators in the GAN, and using more unpaired data for training. Specifically, drawing inspiration from recent advancements in neural vocoders, we employ in our GAN-based model for guitar amplifier modeling two sets of discriminators, one based on multi-scale discriminator (MSD) and the other multi-period discriminator (MPD). Moreover, we experiment with adding unprocessed audio signals that do not have the corresponding rendered audio of a target tone to the training data, to see how much the GAN model benefits from the unpaired data. Our experiments show that the proposed two extensions contribute to the modeling of both low-gain and high-gain guitar amplifiers.
Model-Based Deep Learning for Music Information Research
Jun 17, 2024



In this article, we investigate the notion of model-based deep learning in the realm of music information research (MIR). Loosely speaking, we refer to the term model-based deep learning for approaches that combine traditional knowledge-based methods with data-driven techniques, especially those based on deep learning, within a diff erentiable computing framework. In music, prior knowledge for instance related to sound production, music perception or music composition theory can be incorporated into the design of neural networks and associated loss functions. We outline three specifi c scenarios to illustrate the application of model-based deep learning in MIR, demonstrating the implementation of such concepts and their potential.
Local Periodicity-Based Beat Tracking for Expressive Classical Piano Music
Aug 20, 2023



To model the periodicity of beats, state-of-the-art beat tracking systems use "post-processing trackers" (PPTs) that rely on several empirically determined global assumptions for tempo transition, which work well for music with a steady tempo. For expressive classical music, however, these assumptions can be too rigid. With two large datasets of Western classical piano music, namely the Aligned Scores and Performances (ASAP) dataset and a dataset of Chopin's Mazurkas (Maz-5), we report on experiments showing the failure of existing PPTs to cope with local tempo changes, thus calling for new methods. In this paper, we propose a new local periodicity-based PPT, called predominant local pulse-based dynamic programming (PLPDP) tracking, that allows for more flexible tempo transitions. Specifically, the new PPT incorporates a method called "predominant local pulses" (PLP) in combination with a dynamic programming (DP) component to jointly consider the locally detected periodicity and beat activation strength at each time instant. Accordingly, PLPDP accounts for the local periodicity, rather than relying on a global tempo assumption. Compared to existing PPTs, PLPDP particularly enhances the recall values at the cost of a lower precision, resulting in an overall improvement of F1-score for beat tracking in ASAP (from 0.473 to 0.493) and Maz-5 (from 0.595 to 0.838).
An Analysis Method for Metric-Level Switching in Beat Tracking
Oct 13, 2022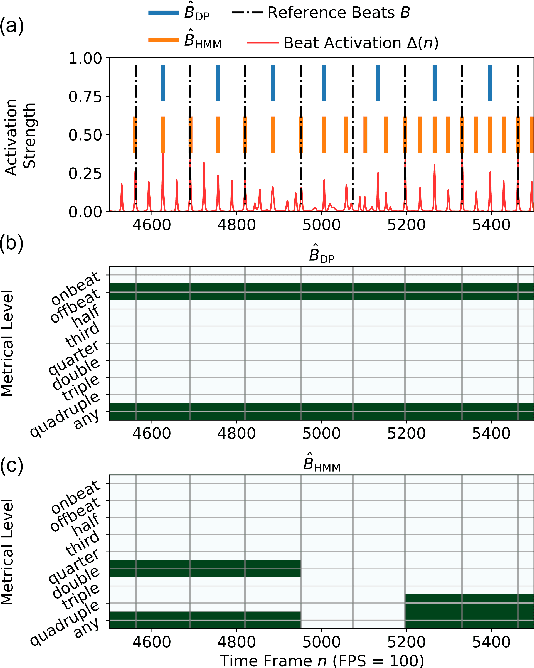
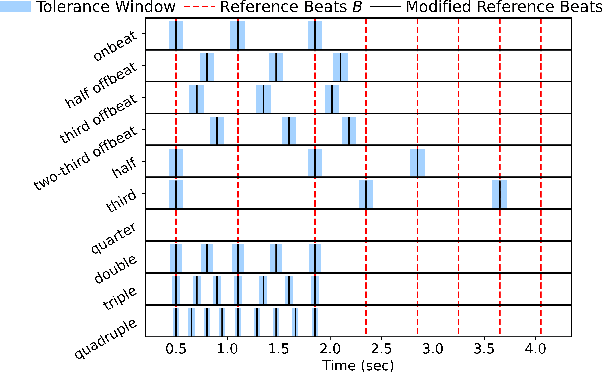
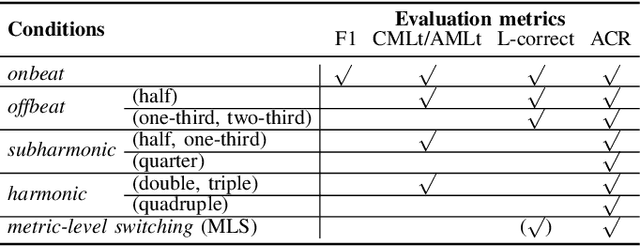
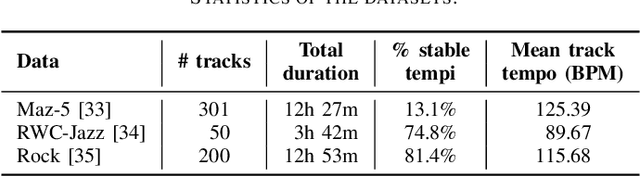
For expressive music, the tempo may change over time, posing challenges to tracking the beats by an automatic model. The model may first tap to the correct tempo, but then may fail to adapt to a tempo change, or switch between several incorrect but perceptually plausible ones (e.g., half- or double-tempo). Existing evaluation metrics for beat tracking do not reflect such behaviors, as they typically assume a fixed relationship between the reference beats and estimated beats. In this paper, we propose a new performance analysis method, called annotation coverage ratio (ACR), that accounts for a variety of possible metric-level switching behaviors of beat trackers. The idea is to derive sequences of modified reference beats of all metrical levels for every two consecutive reference beats, and compare every sequence of modified reference beats to the subsequences of estimated beats. We show via experiments on three datasets of different genres the usefulness of ACR when utilized alongside existing metrics, and discuss the new insights to be gained.
JukeDrummer: Conditional Beat-aware Audio-domain Drum Accompaniment Generation via Transformer VQ-VA
Oct 12, 2022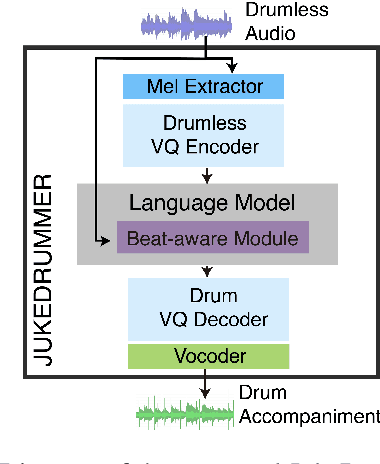
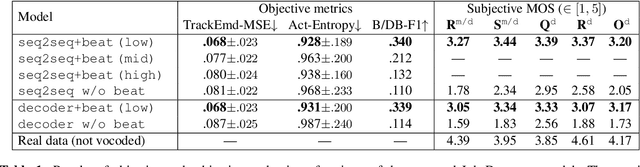
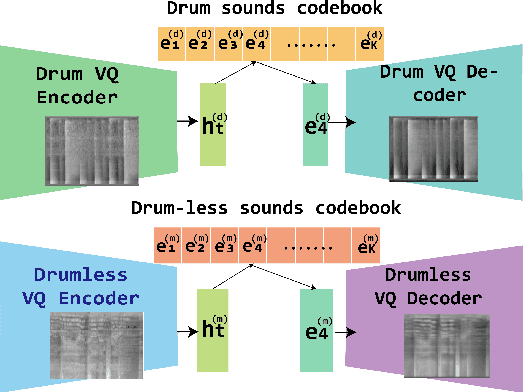
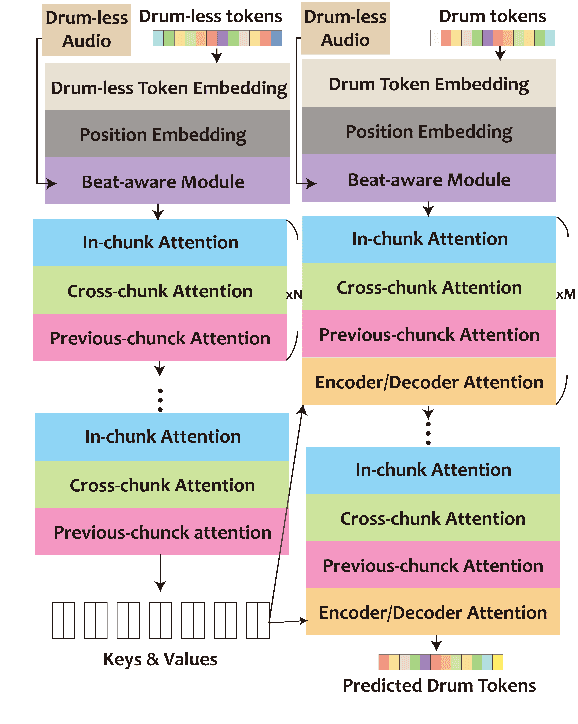
This paper proposes a model that generates a drum track in the audio domain to play along to a user-provided drum-free recording. Specifically, using paired data of drumless tracks and the corresponding human-made drum tracks, we train a Transformer model to improvise the drum part of an unseen drumless recording. We combine two approaches to encode the input audio. First, we train a vector-quantized variational autoencoder (VQ-VAE) to represent the input audio with discrete codes, which can then be readily used in a Transformer. Second, using an audio-domain beat tracking model, we compute beat-related features of the input audio and use them as embeddings in the Transformer. Instead of generating the drum track directly as waveforms, we use a separate VQ-VAE to encode the mel-spectrogram of a drum track into another set of discrete codes, and train the Transformer to predict the sequence of drum-related discrete codes. The output codes are then converted to a mel-spectrogram with a decoder, and then to the waveform with a vocoder. We report both objective and subjective evaluations of variants of the proposed model, demonstrating that the model with beat information generates drum accompaniment that is rhythmically and stylistically consistent with the input audio.
Melody Infilling with User-Provided Structural Context
Oct 06, 2022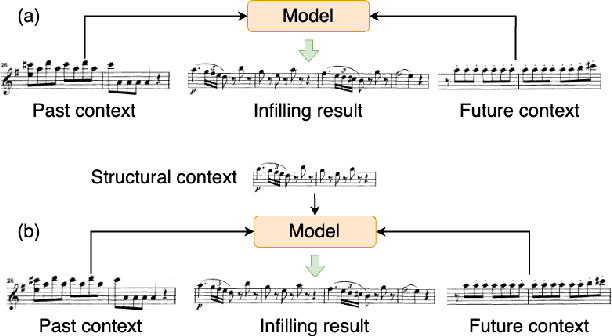
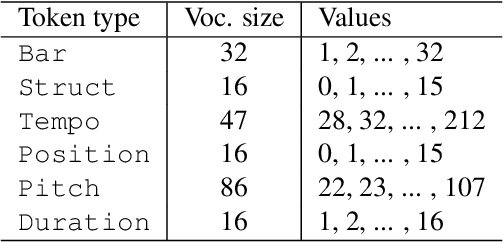
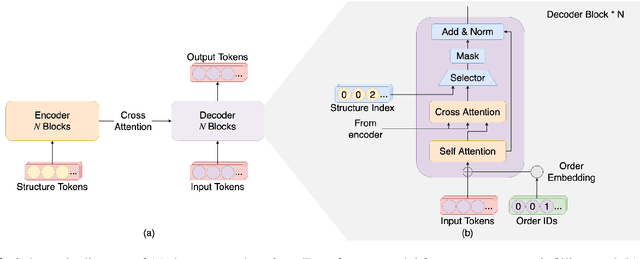
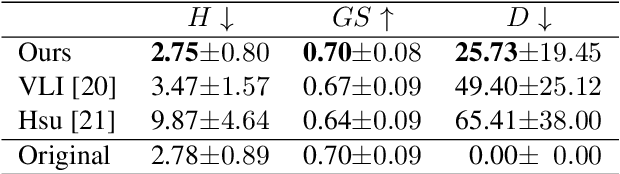
This paper proposes a novel Transformer-based model for music score infilling, to generate a music passage that fills in the gap between given past and future contexts. While existing infilling approaches can generate a passage that connects smoothly locally with the given contexts, they do not take into account the musical form or structure of the music and may therefore generate overly smooth results. To address this issue, we propose a structure-aware conditioning approach that employs a novel attention-selecting module to supply user-provided structure-related information to the Transformer for infilling. With both objective and subjective evaluations, we show that the proposed model can harness the structural information effectively and generate melodies in the style of pop of higher quality than the two existing structure-agnostic infilling models.
Compose & Embellish: Well-Structured Piano Performance Generation via A Two-Stage Approach
Sep 17, 2022
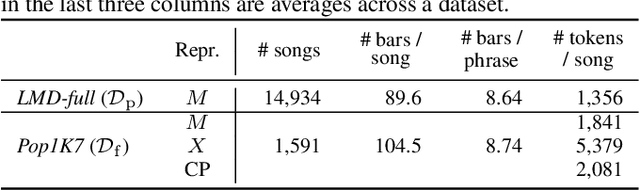
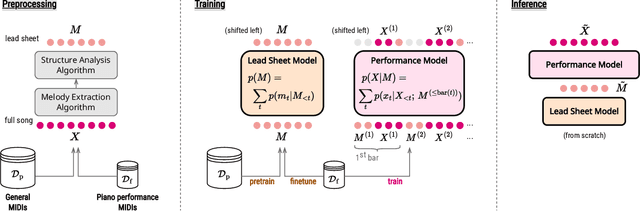
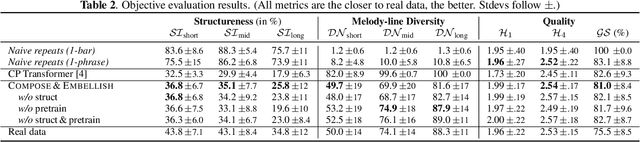
Even with strong sequence models like Transformers, generating expressive piano performances with long-range musical structures remains challenging. Meanwhile, methods to compose well-structured melodies or lead sheets (melody + chords), i.e., simpler forms of music, gained more success. Observing the above, we devise a two-stage Transformer-based framework that Composes a lead sheet first, and then Embellishes it with accompaniment and expressive touches. Such a factorization also enables pretraining on non-piano data. Our objective and subjective experiments show that Compose & Embellish shrinks the gap in structureness between a current state of the art and real performances by half, and improves other musical aspects such as richness and coherence as well.
Exploiting Pre-trained Feature Networks for Generative Adversarial Networks in Audio-domain Loop Generation
Sep 05, 2022
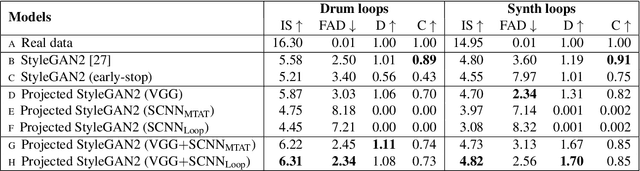
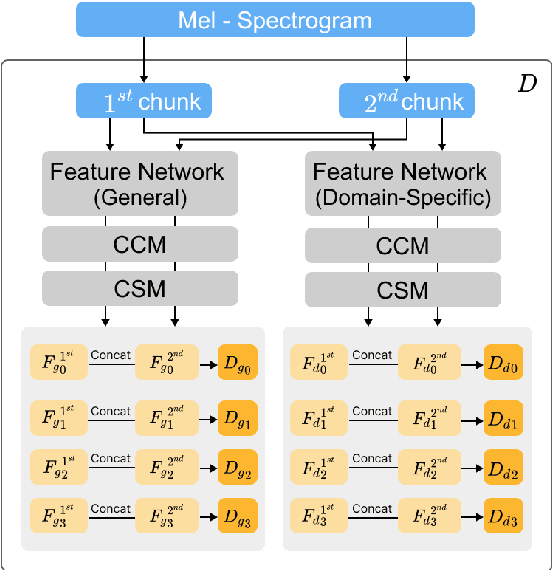

While generative adversarial networks (GANs) have been widely used in research on audio generation, the training of a GAN model is known to be unstable, time consuming, and data inefficient. Among the attempts to ameliorate the training process of GANs, the idea of Projected GAN emerges as an effective solution for GAN-based image generation, establishing the state-of-the-art in different image applications. The core idea is to use a pre-trained classifier to constrain the feature space of the discriminator to stabilize and improve GAN training. This paper investigates whether Projected GAN can similarly improve audio generation, by evaluating the performance of a StyleGAN2-based audio-domain loop generation model with and without using a pre-trained feature space in the discriminator. Moreover, we compare the performance of using a general versus domain-specific classifier as the pre-trained audio classifier. With experiments on both drum loop and synth loop generation, we show that a general audio classifier works better, and that with Projected GAN our loop generation models can converge around 5 times faster without performance degradation.
DDSP-based Singing Vocoders: A New Subtractive-based Synthesizer and A Comprehensive Evaluation
Aug 19, 2022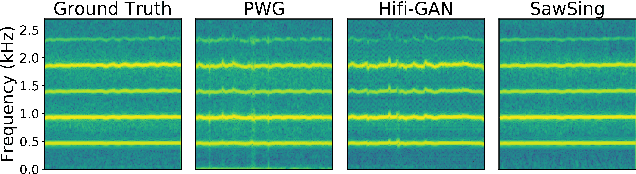
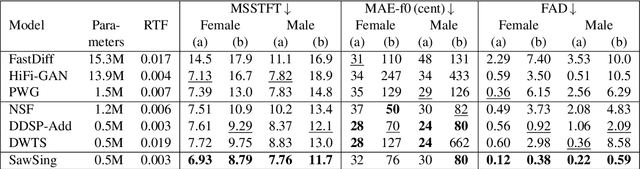
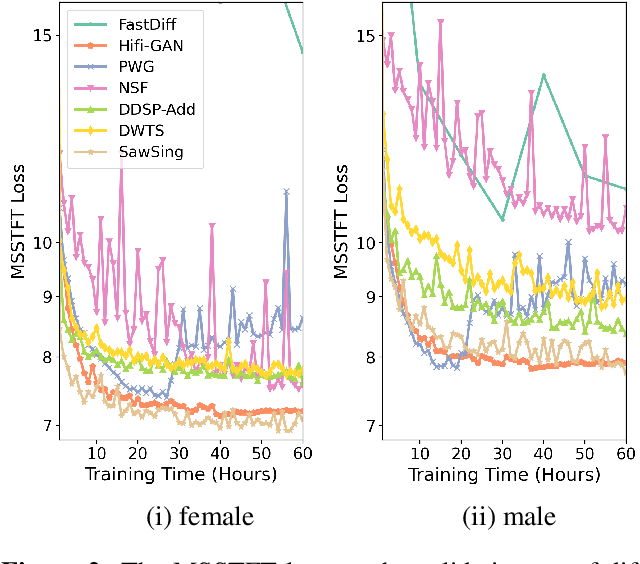
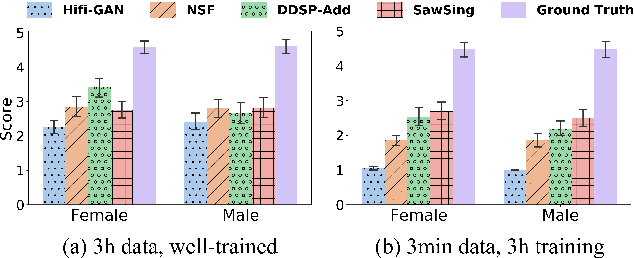
A vocoder is a conditional audio generation model that converts acoustic features such as mel-spectrograms into waveforms. Taking inspiration from Differentiable Digital Signal Processing (DDSP), we propose a new vocoder named SawSing for singing voices. SawSing synthesizes the harmonic part of singing voices by filtering a sawtooth source signal with a linear time-variant finite impulse response filter whose coefficients are estimated from the input mel-spectrogram by a neural network. As this approach enforces phase continuity, SawSing can generate singing voices without the phase-discontinuity glitch of many existing vocoders. Moreover, the source-filter assumption provides an inductive bias that allows SawSing to be trained on a small amount of data. Our experiments show that SawSing converges much faster and outperforms state-of-the-art generative adversarial network and diffusion-based vocoders in a resource-limited scenario with only 3 training recordings and a 3-hour training time.
* Accepted at ISMIR 2022
towards automatic transcription of polyphonic electric guitar music:a new dataset and a multi-loss transformer model
Feb 20, 2022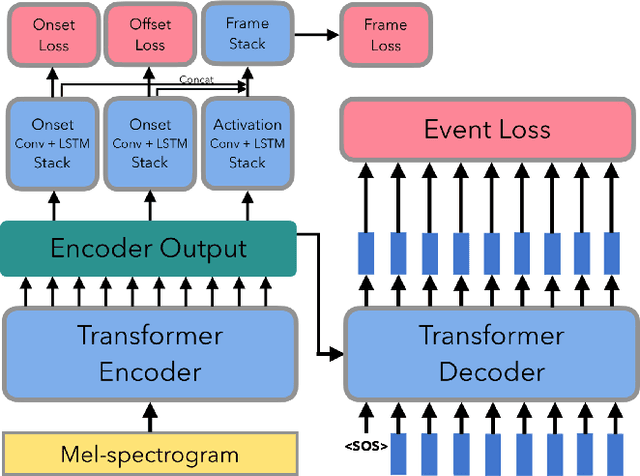
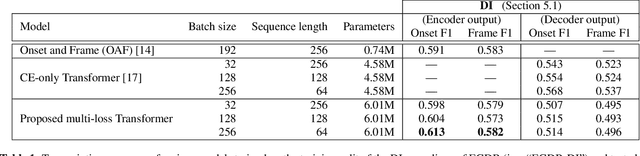
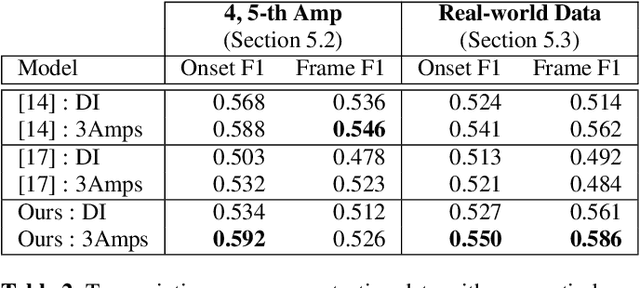
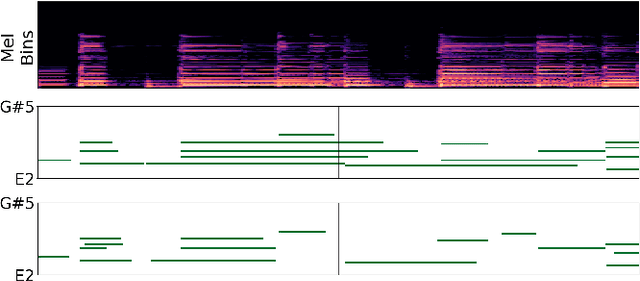
In this paper, we propose a new dataset named EGDB, that con-tains transcriptions of the electric guitar performance of 240 tab-latures rendered with different tones. Moreover, we benchmark theperformance of two well-known transcription models proposed orig-inally for the piano on this dataset, along with a multi-loss Trans-former model that we newly propose. Our evaluation on this datasetand a separate set of real-world recordings demonstrate the influenceof timbre on the accuracy of guitar sheet transcription, the potentialof using multiple losses for Transformers, as well as the room forfurther improvement for this task.