 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelizing non-linear sequential models over the sequence length
Oct 03, 2023



Sequential models, such as Recurrent Neural Networks and Neural Ordinary Differential Equations, have long suffered from slow training due to their inherent sequential nature. For many years this bottleneck has persisted, as many thought sequential models could not be parallelized. We challenge this long-held belief with our parallel algorithm that accelerates GPU evaluation of sequential models by up to 3 orders of magnitude faster without compromising output accuracy. The algorithm does not need any special structure in the sequential models' architecture, making it applicable to a wide range of architectures. Using our method, training sequential models can be more than 10 times faster than the common sequential method without any meaningful difference in the training results. Leveraging this accelerated training, we discovered the efficacy of the Gated Recurrent Unit in a long time series classification problem with 17k time samples. By overcoming the training bottleneck, our work serves as the first step to unlock the potential of non-linear sequential models for long sequence problems.
Constants of motion network
Aug 23, 2022
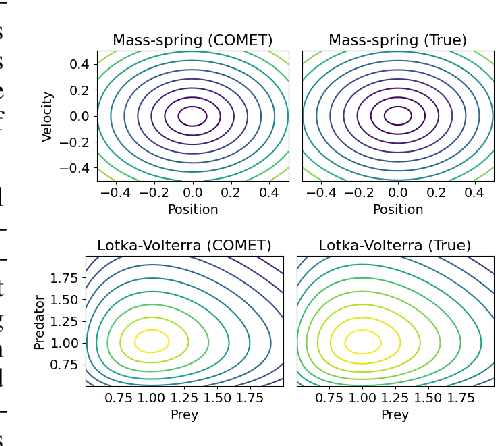

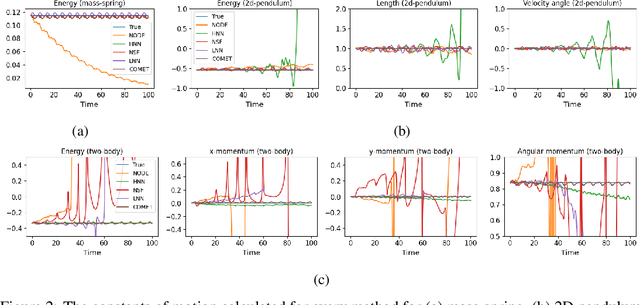
The beauty of physics is that there is usually a conserved quantity in an always-changing system, known as the constant of motion. Finding the constant of motion is important in understanding the dynamics of the system, but typically requires mathematical proficiency and manual analytical work. In this paper, we present a neural network that can simultaneously learn the dynamics of the system and the constants of motion from data. By exploiting the discovered constants of motion, it can produce better predictions on dynamics and can work on a wider range of systems than Hamiltonian-based neural networks. In addition, the training progresses of our method can be used as an indication of the number of constants of motion in a system which could be useful in studying a novel physical system.
Unifying physical systems' inductive biases in neural ODE using dynamics constraints
Aug 03, 2022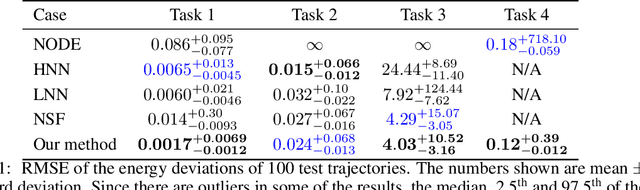
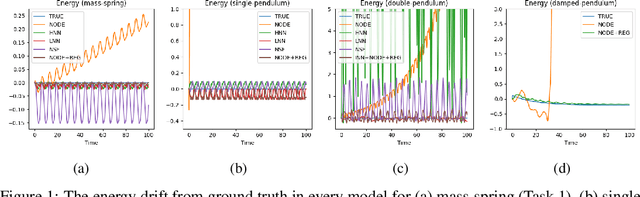
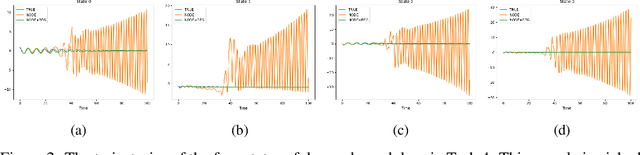
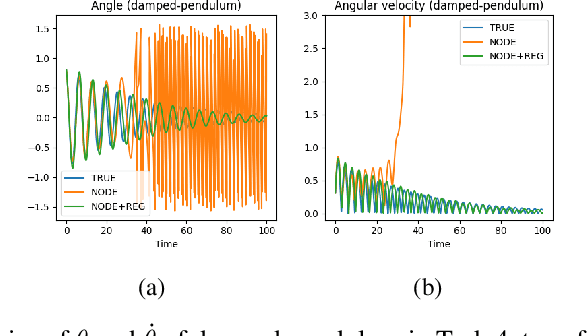
Conservation of energy is at the core of many physical phenomena and dynamical systems. There have been a significant number of works in the past few years aimed at predicting the trajectory of motion of dynamical systems using neural networks while adhering to the law of conservation of energy. Most of these works are inspired by classical mechanics such as Hamiltonian and Lagrangian mechanics as well as Neural Ordinary Differential Equations. While these works have been shown to work well in specific domains respectively, there is a lack of a unifying method that is more generally applicable without requiring significant changes to the neural network architectures. In this work, we aim to address this issue by providing a simple method that could be applied to not just energy-conserving systems, but also dissipative systems, by including a different inductive bias in different cases in the form of a regularisation term in the loss function. The proposed method does not require changing the neural network architecture and could form the basis to validate a novel idea, therefore showing promises to accelerate research in this direction.
Reducing the Long Tail Losses in Scientific Emulations with Active Learning
Nov 15, 2021
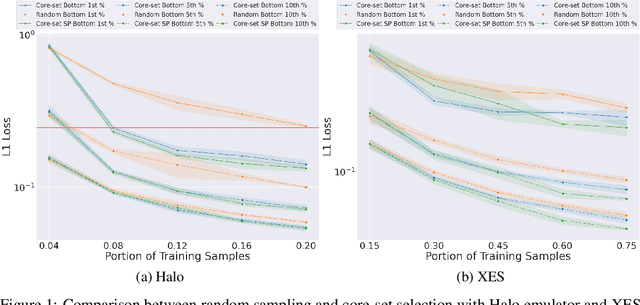
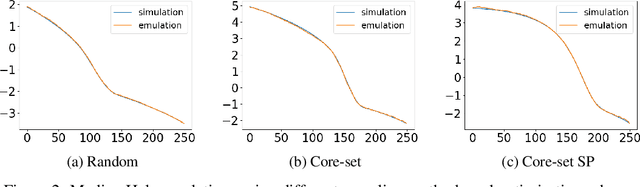
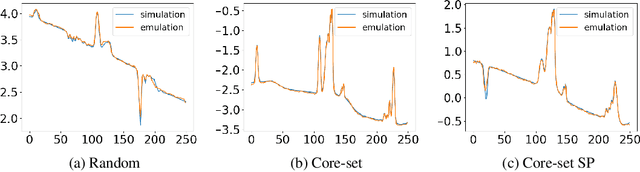
Deep-learning-based models are increasingly used to emulate scientific simulations to accelerate scientific research. However, accurate, supervised deep learning models require huge amount of labelled data, and that often becomes the bottleneck in employing neural networks. In this work, we leveraged an active learning approach called core-set selection to actively select data, per a pre-defined budget, to be labelled for training. To further improve the model performance and reduce the training costs, we also warm started the training using a shrink-and-perturb trick. We tested on two case studies in different fields, namely galaxy halo occupation distribution modelling in astrophysics and x-ray emission spectroscopy in plasma physics, and the results are promising: we achieved competitive overall performance compared to using a random sampling baseline, and more importantly, successfully reduced the larger absolute losses, i.e. the long tail in the loss distribution, at virtually no overhead costs.