 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Entropy: Modeling Game State Stability from Multimodality Trajectory Prediction
Jun 06, 2025Complex interactions among agents present a significant challenge for autonomous driving in real-world scenarios. Recently, a promising approach has emerged, which formulates the interactions of agents as a level-k game framework. It effectively decouples agent policies by hierarchical game levels. However, this framework ignores both the varying driving complexities among agents and the dynamic changes in agent states across game levels, instead treating them uniformly. Consequently, redundant and error-prone computations are introduced into this framework. To tackle the issue, this paper proposes a metric, termed as Trajectory Entropy, to reveal the game status of agents within the level-k game framework. The key insight stems from recognizing the inherit relationship between agent policy uncertainty and the associated driving complexity. Specifically, Trajectory Entropy extracts statistical signals representing uncertainty from the multimodality trajectory prediction results of agents in the game. Then, the signal-to-noise ratio of this signal is utilized to quantify the game status of agents. Based on the proposed Trajectory Entropy, we refine the current level-k game framework through a simple gating mechanism, significantly improving overall accuracy while reducing computational costs. Our method is evaluated on the Waymo and nuPlan datasets, in terms of trajectory prediction, open-loop and closed-loop planning tasks. The results demonstrate the state-of-the-art performance of our method, with precision improved by up to 19.89% for prediction and up to 16.48% for planning.
DMESA: Densely Matching Everything by Segmenting Anything
Aug 01, 2024We propose MESA and DMESA as novel feature matching methods, which utilize Segment Anything Model (SAM) to effectively mitigate matching redundancy. The key insight of our methods is to establish implicit-semantic area matching prior to point matching, based on advanced image understanding of SAM. Then, informative area matches with consistent internal semantic are able to undergo dense feature comparison, facilitating precise inside-area point matching. Specifically, MESA adopts a sparse matching framework and first obtains candidate areas from SAM results through a novel Area Graph (AG). Then, area matching among the candidates is formulated as graph energy minimization and solved by graphical models derived from AG. To address the efficiency issue of MESA, we further propose DMESA as its dense counterpart, applying a dense matching framework. After candidate areas are identified by AG, DMESA establishes area matches through generating dense matching distributions. The distributions are produced from off-the-shelf patch matching utilizing the Gaussian Mixture Model and refined via the Expectation Maximization. With less repetitive computation, DMESA showcases a speed improvement of nearly five times compared to MESA, while maintaining competitive accuracy. Our methods are extensively evaluated on five datasets encompassing indoor and outdoor scenes. The results illustrate consistent performance improvements from our methods for five distinct point matching baselines across all datasets. Furthermore, our methods exhibit promise generalization and improved robustness against image resolution variations. The code is publicly available at https://github.com/Easonyesheng/A2PM-MESA.
MESA: Matching Everything by Segmenting Anything
Jan 30, 2024Feature matching is a crucial task in the field of computer vision, which involves finding correspondences between images. Previous studies achieve remarkable performance using learning-based feature comparison. However, the pervasive presence of matching redundancy between images gives rise to unnecessary and error-prone computations in these methods, imposing limitations on their accuracy. To address this issue, we propose MESA, a novel approach to establish precise area (or region) matches for efficient matching redundancy reduction. MESA first leverages the advanced image understanding capability of SAM, a state-of-the-art foundation model for image segmentation, to obtain image areas with implicit semantic. Then, a multi-relational graph is proposed to model the spatial structure of these areas and construct their scale hierarchy. Based on graphical models derived from the graph, the area matching is reformulated as an energy minimization task and effectively resolved. Extensive experiments demonstrate that MESA yields substantial precision improvement for multiple point matchers in indoor and outdoor downstream tasks, e.g. +13.61% for DKM in indoor pose estimation.
Searching from Area to Point: A Hierarchical Framework for Semantic-Geometric Combined Feature Matching
May 05, 2023



Feature matching is a crucial technique in computer vision. Essentially, it can be considered as a searching problem to establish correspondences between images. The key challenge in this task lies in the lack of a well-defined search space, leading to inaccurate point matching of current methods. In pursuit of a reasonable matching search space, this paper introduces a hierarchical feature matching framework: Area to Point Matching (A2PM), to first find semantic area matches between images, and then perform point matching on area matches, thus setting the search space as the area matches with salient features to achieve high matching precision. This proper search space of A2PM framework also alleviates the accuracy limitation in state-of-the-art Transformer-based matching methods. To realize this framework, we further propose Semantic and Geometry Area Matching (SGAM) method, which utilizes semantic prior and geometry consistency to establish accurate area matches between images. By integrating SGAM with off-the-shelf Transformer-based matchers, our feature matching methods, adopting the A2PM framework, achieve encouraging precision improvements in massive point matching and pose estimation experiments for present arts.
Learning-Based Framework for Camera Calibration with Distortion Correction and High Precision Feature Detection
Feb 13, 2022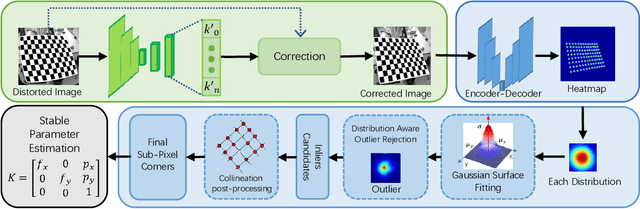
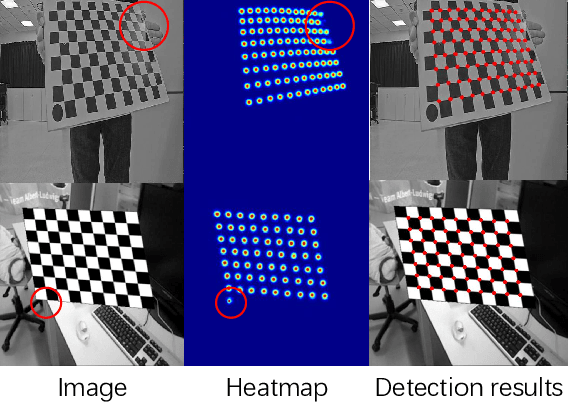
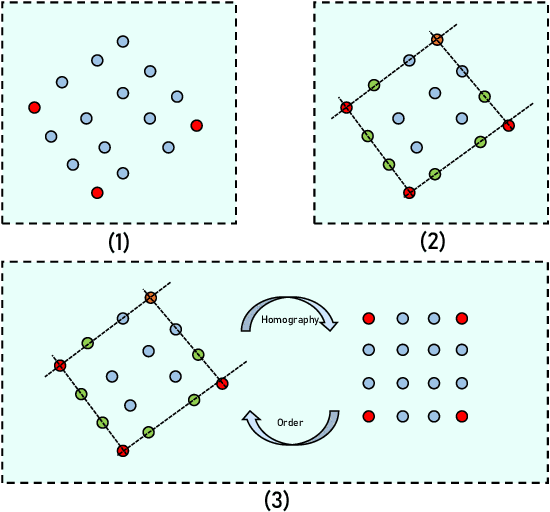
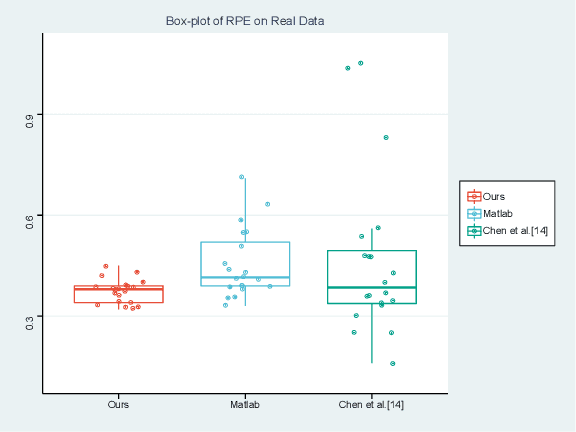
Camera calibration is a crucial technique which significantly influences the performance of many robotic systems. Robustness and high precision have always been the pursuit of diverse calibration methods. State-of-the-art calibration techniques based on classical Zhang's method, however, still suffer from environmental noise, radial lens distortion and sub-optimal parameter estimation. Therefore, in this paper, we propose a hybrid camera calibration framework which combines learning-based approaches with traditional methods to handle these bottlenecks. In particular, this framework leverages learning-based approaches to perform efficient distortion correction and robust chessboard corner coordinate encoding. For sub-pixel accuracy of corner detection, a specially-designed coordinate decoding algorithm with embed outlier rejection mechanism is proposed. To avoid sub-optimal estimation results, we improve the traditional parameter estimation by RANSAC algorithm and achieve stable results. Compared with two widely-used camera calibration toolboxes, experiment results on both real and synthetic datasets manifest the better robustness and higher precision of the proposed framework. The massive synthetic dataset is the basis of our framework's decent performance and will be publicly available along with the code at https://github.com/Easonyesheng/CCS.
An End to End Network Architecture for Fundamental Matrix Estimation
Oct 29, 2020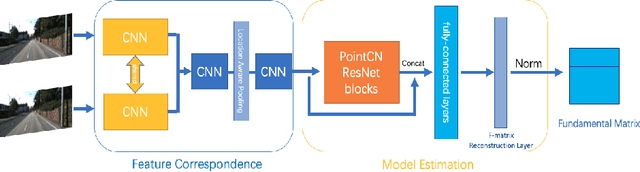
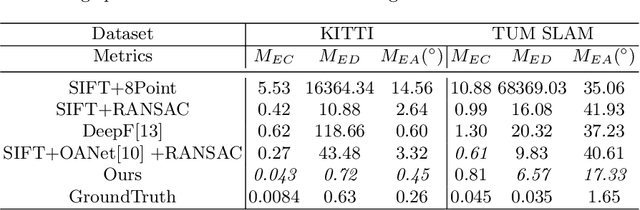
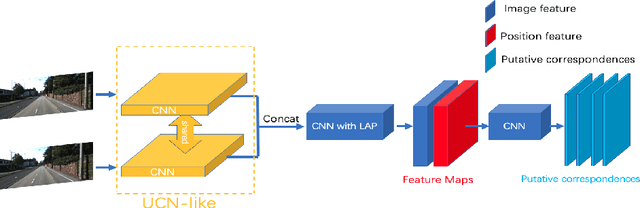
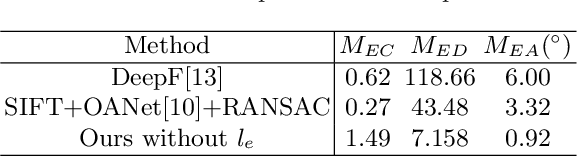
In this paper, we present a novel end-to-end network architecture to estimate fundamental matrix directly from stereo images. To establish a complete working pipeline, different deep neural networks in charge of finding correspondences in images, performing outlier rejection and calculating fundamental matrix, are integrated into an end-to-end network architecture. To well train the network and preserve geometry properties of fundamental matrix, a new loss function is introduced. To evaluate the accuracy of estimated fundamental matrix more reasonably, we design a new evaluation metric which is highly consistent with visualization result. Experiments conducted on both outdoor and indoor data-sets show that this network outperforms traditional methods as well as previous deep learning based methods on various metrics and achieves significant performance improvements.