 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFamily-Aware Residual Architecture for Predicting Quantum Circuit Simulation Performance
Jun 10, 2026Approximate tensor-network simulators enable classical simulation of quantum circuits beyond the reach of exact methods, but selecting optimal approximation parameters -- such as bond dimension thresholds -- remains a costly trial-and-error process. We present a family-aware neural architecture that predicts both the minimum approximation threshold required to achieve target fidelity and the expected wall-clock runtime for quantum circuit simulation, given only the circuit's OpenQASM description and execution context. Our key insight is that quantum circuits from different algorithmic families (e.g., QFT, Grover, VQE) exhibit fundamentally distinct simulation cost profiles due to their differing entanglement structures. We employ family-conditioned residual corrections -- additive, family-specific adjustments atop a shared backbone, drawing on established conditional computation techniques -- enabling the model to capture both universal circuit properties and algorithmic nuances. The architecture incorporates a pretrained family classifier (97.5% accuracy) and domain-informed algorithm fingerprint features derived from gate-composition heuristics. Evaluated on circuits spanning 7--130 qubits across 10 algorithm families, our system achieves 79.5% exact threshold accuracy (91.2% within one rung) and $R^2 = 0.82$ runtime correlation, with inference completing in approximately 50 ms -- replacing trial-and-error simulation runs that may take minutes to hours. Ablation studies confirm that family-aware modeling provides the single largest performance improvement (+3.2 percentage points), validating the hypothesis that algorithm family is a first-class feature for simulation cost prediction.
SDW-ASL: A Dynamic System to Generate Large Scale Dataset for Continuous American Sign Language
Oct 13, 2022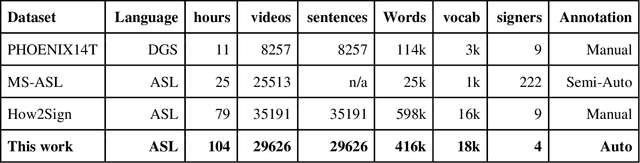

Despite tremendous progress in natural language processing using deep learning techniques in recent years, sign language production and comprehension has advanced very little. One critical barrier is the lack of largescale datasets available to the public due to the unbearable cost of labeled data generation. Efforts to provide public data for American Sign Language (ASL) comprehension have yielded two datasets, comprising more than thousand video clips. These datasets are large enough to enable a meaningful start to deep learning research on sign languages but are far too small to lead to any solution that can be practically deployed. So far, there is still no suitable dataset for ASL production. We proposed a system that can generate large scale ASL datasets for continuous ASL. It is suitable for general ASL processing and is particularly useful for ASL production. The continuous ASL dataset contains English labeled human articulations in condensed body pose data formats. To better serve the research community, we are releasing the first version of our ASL dataset, which contains 30k sentences, 416k words, a vocabulary of 18k words, in a total of 104 hours. This is the largest continuous sign language dataset published to date in terms of video duration. We also describe a system that can evolve and expand the dataset to incorporate better data processing techniques and more contents when available. It is our hope that the release of this ASL dataset and the sustainable dataset generation system to the public will propel better deep-learning research in ASL natural language processing.