 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Minimal Adversarial Perturbations with Integrated Adaptive Gradients
May 20, 2019
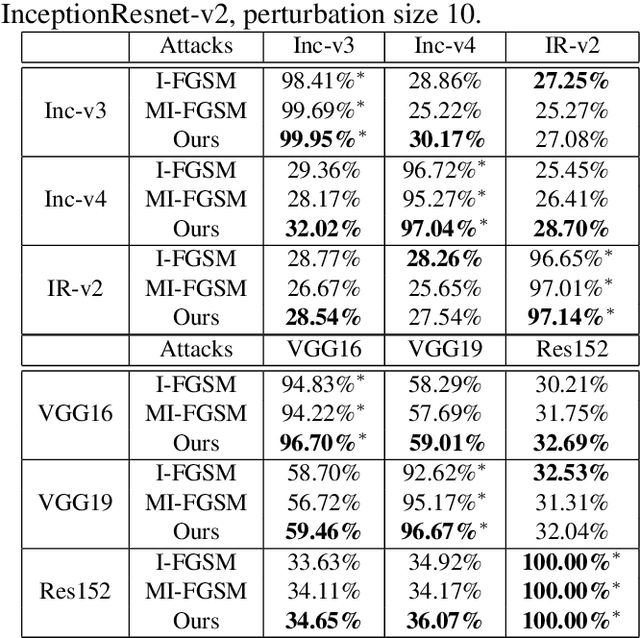
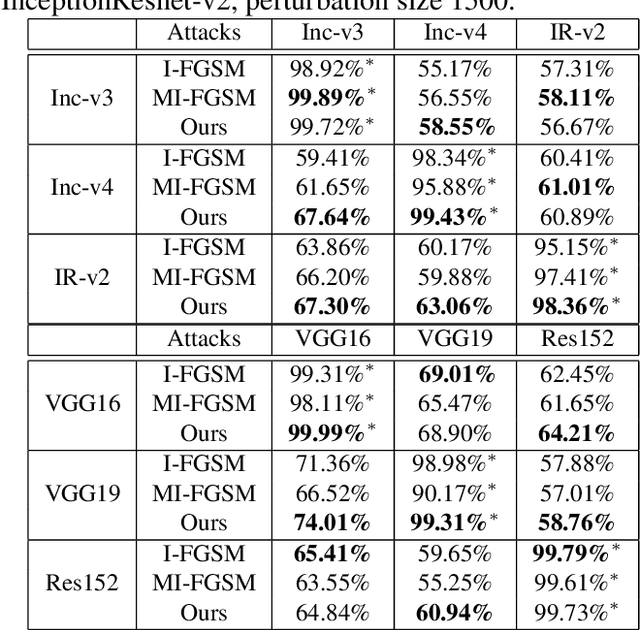
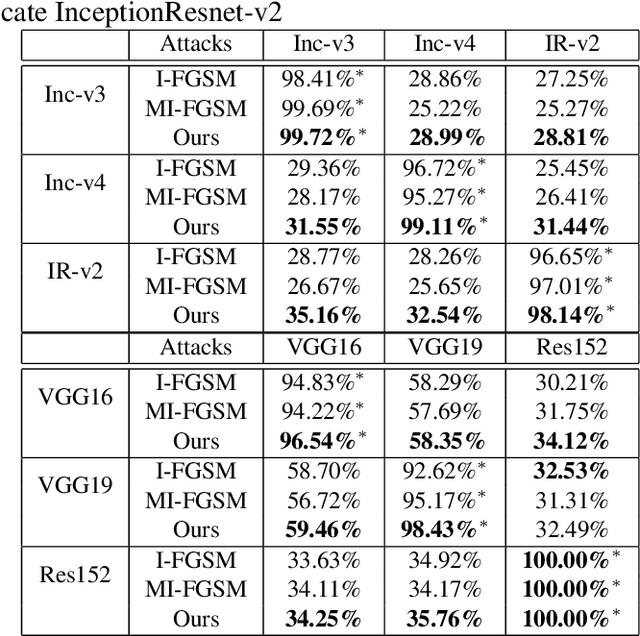
Deep neural networks are easily fooled high confidence predictions for adversarial samples
Adaptive Gradient for Adversarial Perturbations Generation
Apr 12, 2019
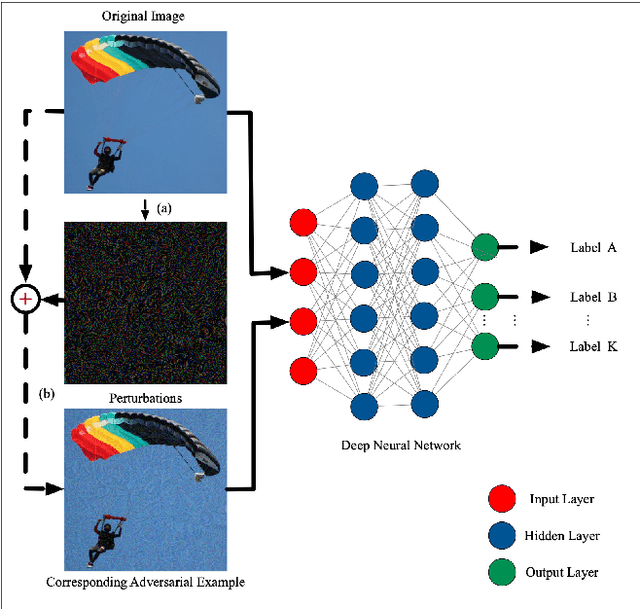
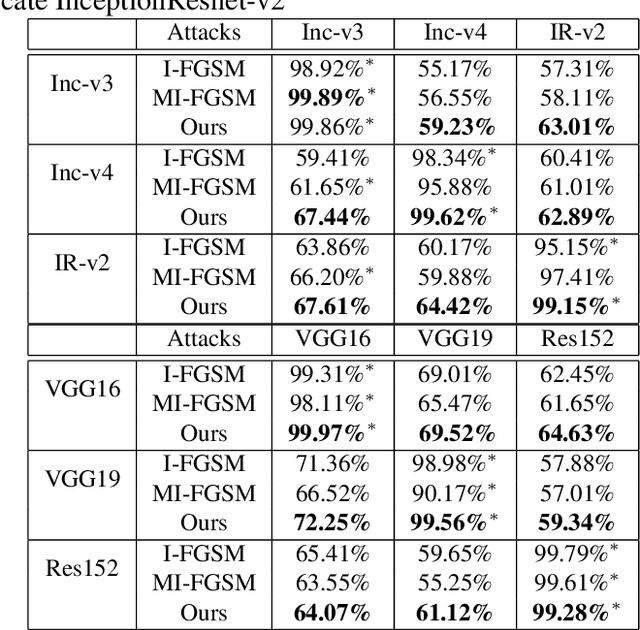
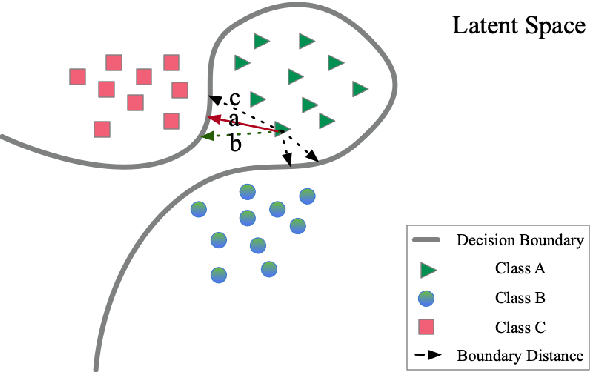
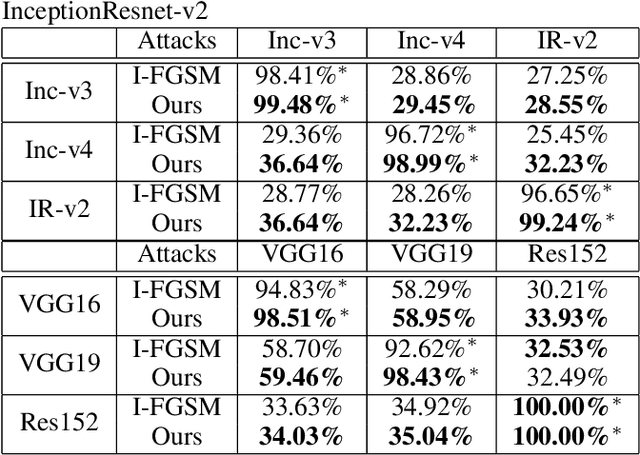
Deep Neural Networks have achieved remarkable success in computer vision, natural language processing, and audio tasks. However, in image classification domain, researches proved that deep neural models are easily fooled when affected by perturbation, which may cause server results. Many attack methods generate adversarial perturbation with large-scale pixel modification and low similarity between origin and corresponding adversarial examples, to address these issues, we propose an adversarial approach with the adaptive mechanism by self-adjusting perturbation intensity to seek the boundary distance between different classes directly which can escape local minimal in gradient processing. In this paper, we evaluate several traditional perturbations generating methods with our works. Experimental results show that our approach works well and outperform recent techniques in the change of misclassifying image prediction, and presents excellent efficiency in fooling deep network models.
Generating Adversarial Perturbation with Root Mean Square Gradient
Jan 26, 2019
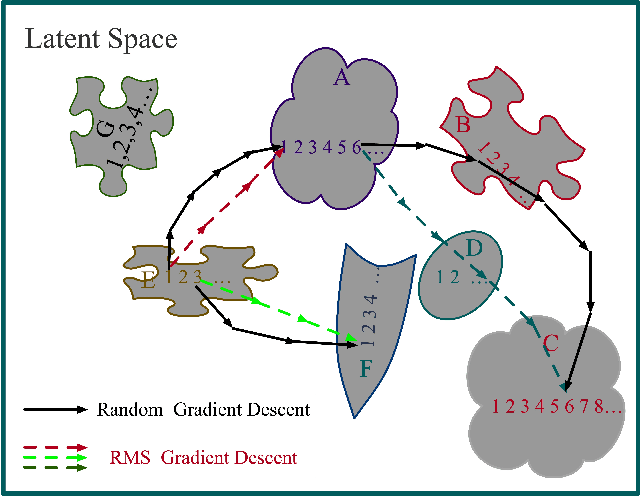
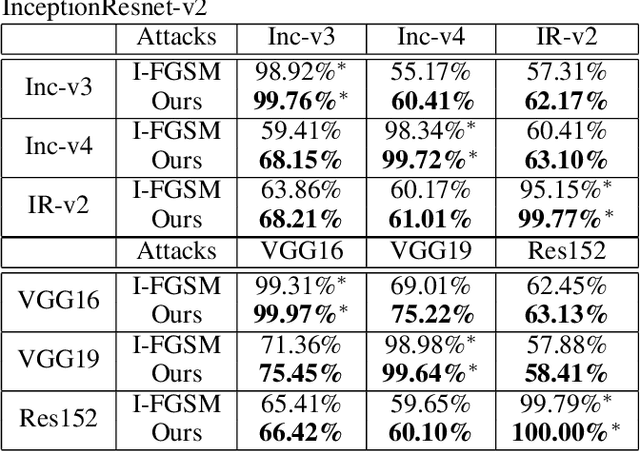
Deep Neural Models are vulnerable to adversarial perturbations in classification. Many attack methods generate adversarial examples with large pixel modification and low cosine similarity with original images. In this paper, we propose an adversarial method generating perturbations based on root mean square gradient which formulates adversarial perturbation size in root mean square level and update gradient in direction, due to updating gradients with adaptive and root mean square stride, our method map origin, and corresponding adversarial image directly which shows good transferability in adversarial examples generation. We evaluate several traditional perturbations creating ways in image classification with our methods. Experimental results show that our approach works well and outperform recent techniques in the change of misclassifying image classification with slight pixel modification, and excellent efficiency in fooling deep network models.