 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time Bounds for Distributionally Robust TD Learning with Linear Function Approximation
Oct 02, 2025Distributionally robust reinforcement learning (DRRL) focuses on designing policies that achieve good performance under model uncertainties. In particular, we are interested in maximizing the worst-case long-term discounted reward, where the data for RL comes from a nominal model while the deployed environment can deviate from the nominal model within a prescribed uncertainty set. Existing convergence guarantees for robust temporal-difference (TD) learning for policy evaluation are limited to tabular MDPs or are dependent on restrictive discount-factor assumptions when function approximation is used. We present the first robust TD learning with linear function approximation, where robustness is measured with respect to the total-variation distance and Wasserstein-l distance uncertainty set. Additionally, our algorithm is both model-free and does not require generative access to the MDP. Our algorithm combines a two-time-scale stochastic-approximation update with an outer-loop target-network update. We establish an $\tilde{O}(1/\epsilon^2)$ sample complexity to obtain an $\epsilon$-accurate value estimate. Our results close a key gap between the empirical success of robust RL algorithms and the non-asymptotic guarantees enjoyed by their non-robust counterparts. The key ideas in the paper also extend in a relatively straightforward fashion to robust Q-learning with function approximation.
Performance of NPG in Countable State-Space Average-Cost RL
May 30, 2024We consider policy optimization methods in reinforcement learning settings where the state space is arbitrarily large, or even countably infinite. The motivation arises from control problems in communication networks, matching markets, and other queueing systems. We consider Natural Policy Gradient (NPG), which is a popular algorithm for finite state spaces. Under reasonable assumptions, we derive a performance bound for NPG that is independent of the size of the state space, provided the error in policy evaluation is within a factor of the true value function. We obtain this result by establishing new policy-independent bounds on the solution to Poisson's equation, i.e., the relative value function, and by combining these bounds with previously known connections between MDPs and learning from experts.
On the Global Convergence of Policy Gradient in Average Reward Markov Decision Processes
Mar 11, 2024



We present the first finite time global convergence analysis of policy gradient in the context of infinite horizon average reward Markov decision processes (MDPs). Specifically, we focus on ergodic tabular MDPs with finite state and action spaces. Our analysis shows that the policy gradient iterates converge to the optimal policy at a sublinear rate of $O\left({\frac{1}{T}}\right),$ which translates to $O\left({\log(T)}\right)$ regret, where $T$ represents the number of iterations. Prior work on performance bounds for discounted reward MDPs cannot be extended to average reward MDPs because the bounds grow proportional to the fifth power of the effective horizon. Thus, our primary contribution is in proving that the policy gradient algorithm converges for average-reward MDPs and in obtaining finite-time performance guarantees. In contrast to the existing discounted reward performance bounds, our performance bounds have an explicit dependence on constants that capture the complexity of the underlying MDP. Motivated by this observation, we reexamine and improve the existing performance bounds for discounted reward MDPs. We also present simulations to empirically evaluate the performance of average reward policy gradient algorithm.
Performance Bounds for Policy-Based Average Reward Reinforcement Learning Algorithms
Feb 15, 2023Many policy-based reinforcement learning (RL) algorithms can be viewed as instantiations of approximate policy iteration (PI), i.e., where policy improvement and policy evaluation are both performed approximately. In applications where the average reward objective is the meaningful performance metric, often discounted reward formulations are used with the discount factor being close to 1, which is equivalent to making the expected horizon very large. However, the corresponding theoretical bounds for error performance scale with the square of the horizon. Thus, even after dividing the total reward by the length of the horizon, the corresponding performance bounds for average reward problems go to infinity. Therefore, an open problem has been to obtain meaningful performance bounds for approximate PI and RL algorithms for the average-reward setting. In this paper, we solve this open problem by obtaining the first non-trivial error bounds for average-reward MDPs which go to zero in the limit where when policy evaluation and policy improvement errors go to zero.
Modified Policy Iteration for Exponential Cost Risk Sensitive MDPs
Feb 08, 2023


Modified policy iteration (MPI) also known as optimistic policy iteration is at the core of many reinforcement learning algorithms. It works by combining elements of policy iteration and value iteration. The convergence of MPI has been well studied in the case of discounted and average-cost MDPs. In this work, we consider the exponential cost risk-sensitive MDP formulation, which is known to provide some robustness to model parameters. Although policy iteration and value iteration have been well studied in the context of risk sensitive MDPs, modified policy iteration is relatively unexplored. We provide the first proof that MPI also converges for the risk-sensitive problem in the case of finite state and action spaces. Since the exponential cost formulation deals with the multiplicative Bellman equation, our main contribution is a convergence proof which is quite different than existing results for discounted and risk-neutral average-cost problems. The proof of approximate modified policy iteration for risk sensitive MDPs is also provided in the appendix.
A Lagrangian Model to Predict Microscallop Motion in non Newtonian Fluids
Feb 15, 2019
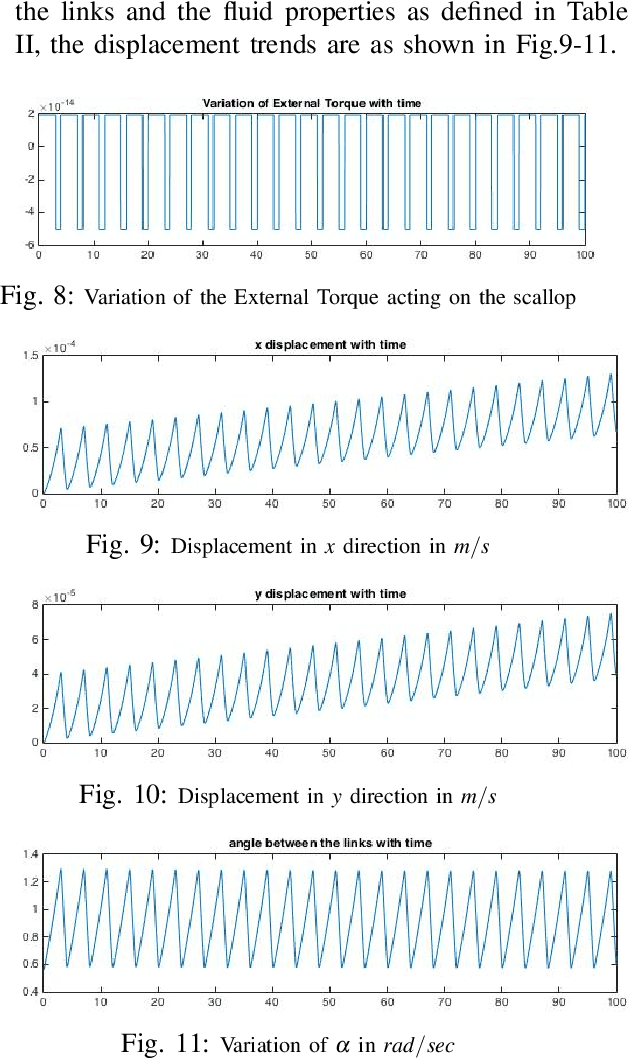
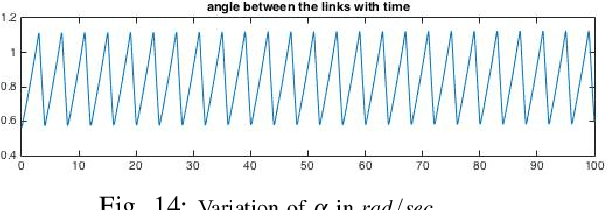
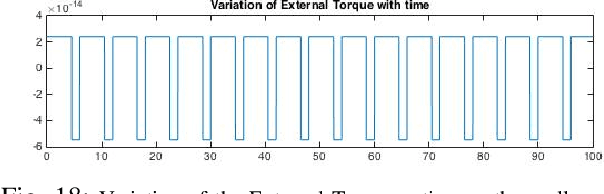
The need to develop models to predict the motion of microrobots, or robots of a much smaller scale, moving in fluids in a low Reynolds number regime, and in particular, in non Newtonian fluids, cannot be understated. The article develops a Lagrangian based model for one such mechanism - a two-link mechanism termed a microscallop, moving in a low Reynolds number environment in a non Newtonian fluid. The modelling proceeds through the conventional Lagrangian construction for a two-link mechanism and then goes on to model the external fluid forces using empirically based models for viscosity to complete the dynamic model. The derived model is then simulated for different initial conditions and key parameters of the non Newtonian fluid, and the results are corroborated with a few existing experimental results on a similar mechanism under identical conditions. Lastly, with a view to implementing control algorithms we explore accessibility of the system at certain configurations.
Nonlinear Dynamics of Binocular Rivalry: A Comparative Study
Nov 25, 2018

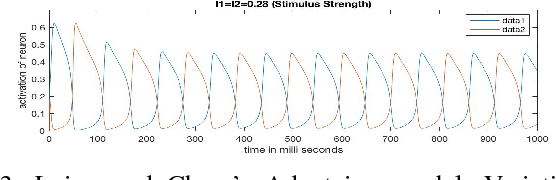
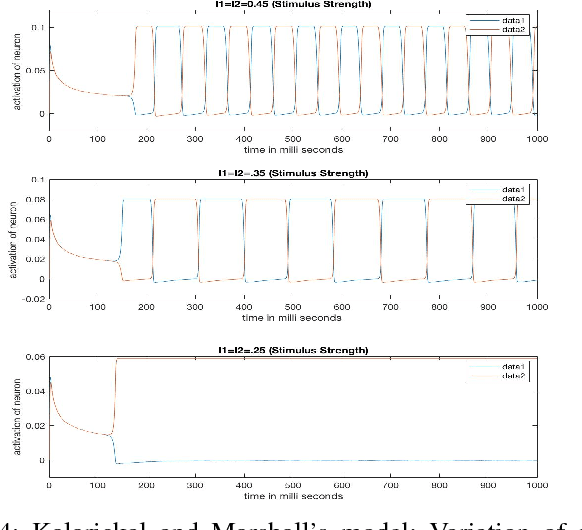
When our eyes are presented with the same image, the brain processes it to view it as a single coherent one. The lateral shift in the position of our eyes, causes the two images to possess certain differences, which our brain exploits for the purpose of depth perception and to gauge the size of objects at different distances, a process commonly known as stereopsis. However, when presented with two different visual stimuli, the visual awareness alternates. This phenomenon of binocular rivalry is a result of competition between the corresponding neuronal populations of the two eyes. The article presents a comparative study of various dynamical models proposed to capture this process. It goes on to study the effect of a certain parameter on the rate of perceptual alternations and proceeds to disprove the initial propositions laid down to characterise this phenomenon. It concludes with a discussion on the possible future work that can be conducted to obtain a better picture of the neuronal functioning behind this rivalry.