 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Optimization in Hybrid Discrete-Continuous Action Spaces via Mixed Gradients
May 14, 2026We study reinforcement learning in hybrid discrete-continuous action spaces, such as settings where the discrete component selects a regime (or index) and the continuous component optimizes within it -- a structure common in robotics, control, and operations problems. Standard model-free policy gradient methods rely on score-function (SF) estimators and suffer from severe credit-assignment issues in high-dimensional settings, leading to poor gradient quality. On the other hand, differentiable simulation largely sidesteps these issues by backpropagating through a simulator, but the presence of discrete actions or non-smooth dynamics yields biased or uninformative gradients. To address this, we propose Hybrid Policy Optimization (HPO), which backpropagates through the simulator wherever smoothness permits, using a mixed gradient estimator that combines pathwise and SF gradients while maintaining unbiasedness. We also show how problems with action discontinuities can be reformulated in hybrid form, further broadening its applicability. Empirically, HPO substantially outperforms PPO on inventory control and switched linear-quadratic regulator problems, with performance gaps increasing as the continuous action dimension grows. Finally, we characterize the structure of the mixed gradient, showing that its cross term -- which captures how continuous actions influence future discrete decisions -- becomes negligible near a discrete best response, thereby enabling approximate decentralized updates of the continuous and discrete components and reducing variance near optimality. All resources are available at github.com/MatiasAlvo/hybrid-rl.
The Fault in Our Recommendations: On the Perils of Optimizing the Measurable
May 07, 2024Recommendation systems are widespread, and through customized recommendations, promise to match users with options they will like. To that end, data on engagement is collected and used. Most recommendation systems are ranking-based, where they rank and recommend items based on their predicted engagement. However, the engagement signals are often only a crude proxy for utility, as data on the latter is rarely collected or available. This paper explores the following question: By optimizing for measurable proxies, are recommendation systems at risk of significantly under-delivering on utility? If so, how can one improve utility which is seldom measured? To study these questions, we introduce a model of repeated user consumption in which, at each interaction, users select between an outside option and the best option from a recommendation set. Our model accounts for user heterogeneity, with the majority preferring ``popular'' content, and a minority favoring ``niche'' content. The system initially lacks knowledge of individual user preferences but can learn them through observations of users' choices over time. Our theoretical and numerical analysis demonstrate that optimizing for engagement can lead to significant utility losses. Instead, we propose a utility-aware policy that initially recommends a mix of popular and niche content. As the platform becomes more forward-looking, our utility-aware policy achieves the best of both worlds: near-optimal utility and near-optimal engagement simultaneously. Our study elucidates an important feature of recommendation systems; given the ability to suggest multiple items, one can perform significant exploration without incurring significant reductions in engagement. By recommending high-risk, high-reward items alongside popular items, systems can enhance discovery of high utility items without significantly affecting engagement.
Neural Inventory Control in Networks via Hindsight Differentiable Policy Optimization
Jun 20, 2023



Inventory management offers unique opportunities for reliably evaluating and applying deep reinforcement learning (DRL). Rather than evaluate DRL algorithms by comparing against one another or against human experts, we can compare to the optimum itself in several problem classes with hidden structure. Our DRL methods consistently recover near-optimal policies in such settings, despite being applied with up to 600-dimensional raw state vectors. In others, they can vastly outperform problem-specific heuristics. To reliably apply DRL, we leverage two insights. First, one can directly optimize the hindsight performance of any policy using stochastic gradient descent. This uses (i) an ability to backtest any policy's performance on a subsample of historical demand observations, and (ii) the differentiability of the total cost incurred on any subsample with respect to policy parameters. Second, we propose a natural neural network architecture to address problems with weak (or aggregate) coupling constraints between locations in an inventory network. This architecture employs weight duplication for ``sibling'' locations in the network, and state summarization. We justify this architecture through an asymptotic guarantee, and empirically affirm its value in handling large-scale problems.
Matching while Learning
Oct 01, 2018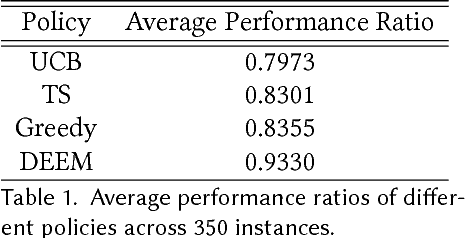
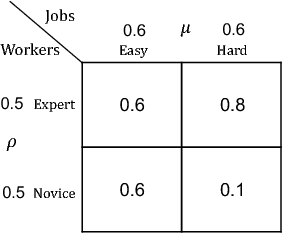
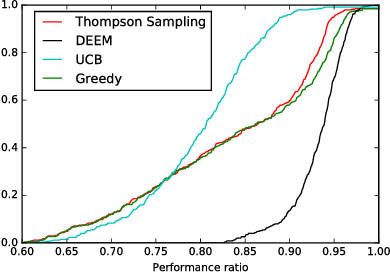
We consider the problem faced by a service platform that needs to match supply with demand, but also to learn attributes of new arrivals in order to match them better in the future. We introduce a benchmark model with heterogeneous workers and jobs that arrive over time. Job types are known to the platform, but worker types are unknown and must be learned by observing match outcomes. Workers depart after performing a certain number of jobs. The payoff from a match depends on the pair of types and the goal is to maximize the steady-state rate of accumulation of payoff. Our main contribution is a complete characterization of the structure of the optimal policy in the limit that each worker performs many jobs. The platform faces a trade-off for each worker between myopically maximizing payoffs (exploitation) and learning the type of the worker (\emph{exploration}). This creates a multitude of multi-armed bandit problems, one for each worker, coupled together by the constraint on the availability of jobs of different types (capacity constraints). We find that the platform should estimate a shadow price for each job type, and use the payoffs adjusted by these prices, first, to determine its learning goals and then, for each worker, (i) to balance learning with payoffs during the "exploration phase", and (ii) to myopically match after it has achieved its learning goals during the "exploitation phase."