 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Fake Narratives in Spreading Hateful Stories: A Dual-Head RoBERTa Model with Multi-Task Learning
Dec 18, 2025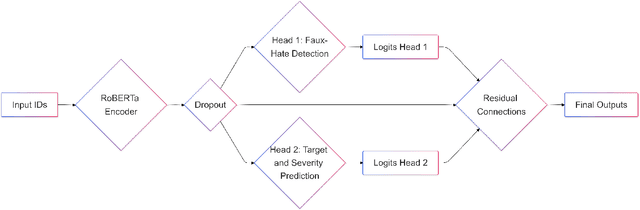
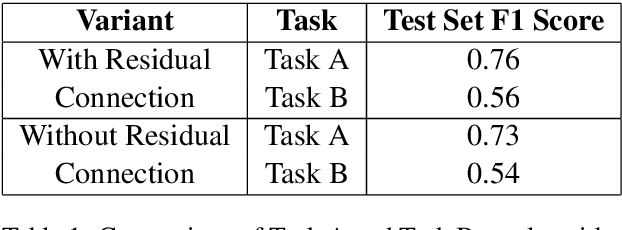
Social media platforms, while enabling global connectivity, have become hubs for the rapid spread of harmful content, including hate speech and fake narratives \cite{davidson2017automated, shu2017fake}. The Faux-Hate shared task focuses on detecting a specific phenomenon: the generation of hate speech driven by fake narratives, termed Faux-Hate. Participants are challenged to identify such instances in code-mixed Hindi-English social media text. This paper describes our system developed for the shared task, addressing two primary sub-tasks: (a) Binary Faux-Hate detection, involving fake and hate speech classification, and (b) Target and Severity prediction, categorizing the intended target and severity of hateful content. Our approach combines advanced natural language processing techniques with domain-specific pretraining to enhance performance across both tasks. The system achieved competitive results, demonstrating the efficacy of leveraging multi-task learning for this complex problem.
* Accepted Paper, Anthology ID: 2024.icon-fauxhate.3, 4 pages, 1 figure, 1 table
Yes-MT's Submission to the Low-Resource Indic Language Translation Shared Task in WMT 2024
Dec 17, 2025



This paper presents the systems submitted by the Yes-MT team for the Low-Resource Indic Language Translation Shared Task at WMT 2024 (Pakray et al., 2024), focusing on translating between English and the Assamese, Mizo, Khasi, and Manipuri languages. The experiments explored various approaches, including fine-tuning pre-trained models like mT5 (Xue et al., 2020) and IndicBart (Dabre et al., 2021) in both multilingual and monolingual settings, LoRA (Hu et al., 2021) fine-tuning IndicTrans2 (Gala et al., 2023), zero-shot and few-shot prompting (Brown, 2020) with large language models (LLMs) like Llama 3 (Dubey et al., 2024) and Mixtral 8x7b (Jiang et al., 2024), LoRA supervised fine-tuning of Llama 3 (Mecklenburg et al., 2024), and training Transformer models (Vaswani, 2017) from scratch. The results were evaluated on the WMT23 Low-Resource Indic Language Translation Shared Task test data using SacreBLEU (Post, 2018) and CHRF (Popovic, 2015), highlighting the challenges of low-resource translation and the potential of LLMs for these tasks, particularly with fine-tuning.
* Accepted at WMT 2024
Assessing Translation capabilities of Large Language Models involving English and Indian Languages
Nov 15, 2023



Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. In this work, our aim is to explore the multilingual capabilities of large language models by using machine translation as a task involving English and 22 Indian languages. We first investigate the translation capabilities of raw large language models, followed by exploring the in-context learning capabilities of the same raw models. We fine-tune these large language models using parameter efficient fine-tuning methods such as LoRA and additionally with full fine-tuning. Through our study, we have identified the best performing large language model for the translation task involving LLMs, which is based on LLaMA. Our results demonstrate significant progress, with average BLEU scores of 13.42, 15.93, 12.13, 12.30, and 12.07, as well as CHRF scores of 43.98, 46.99, 42.55, 42.42, and 45.39, respectively, using 2-stage fine-tuned LLaMA-13b for English to Indian languages on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Similarly, for Indian languages to English, we achieved average BLEU scores of 14.03, 16.65, 16.17, 15.35 and 12.55 along with chrF scores of 36.71, 40.44, 40.26, 39.51, and 36.20, respectively, using fine-tuned LLaMA-13b on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Overall, our findings highlight the potential and strength of large language models for machine translation capabilities, including for languages that are currently underrepresented in LLMs.