 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLoRA+: A Low-Rank Parameter-Efficient Fine-Tuning Method for Large Language Models
Apr 15, 2026Fine-tuning large language models (LLMs) aims to adapt pre-trained models to specific tasks using relatively small and domain-specific datasets. Among Parameter-Efficient Fine-Tuning (PEFT) methods, Low-Rank Adaptation (LoRA) stands out by matching the performance of full fine-tuning while avoiding additional inference latency. In this paper, we propose a novel PEFT method that incorporates the TLoRA+ optimizer into the weight matrices of pre-trained models. The proposed approach not only preserves the efficiency of low-rank adaptation but also further enhances performance without significantly increasing computational cost. We conduct experiments on the GLUE benchmark across diverse model architectures. Numerical experiments consistently demonstrate the effectiveness and robustness of our proposed method.
Adaptive Weighted Multiview Kernel Matrix Factorization with its application in Alzheimer's Disease Analysis -- A clustering Perspective
Mar 07, 2023Recent technology and equipment advancements provide with us opportunities to better analyze Alzheimer's disease (AD), where we could collect and employ the data from different image and genetic modalities that may potentially enhance the predictive performance. To perform better clustering in AD analysis, in this paper we propose a novel model to leverage data from all different modalities/views, which can learn the weights of each view adaptively. Different from previous vanilla Non-negative Matrix Factorization which assumes data is linearly separable, we propose a simple yet efficient method based on kernel matrix factorization, which is not only able to deal with non-linear data structure but also can achieve better prediction accuracy. Experimental results on ADNI dataset demonstrate the effectiveness of our proposed method, which indicate promising prospects of kernel application in AD analysis.
Robust Principal Component Analysis: A Construction Error Minimization Perspective
Nov 23, 2021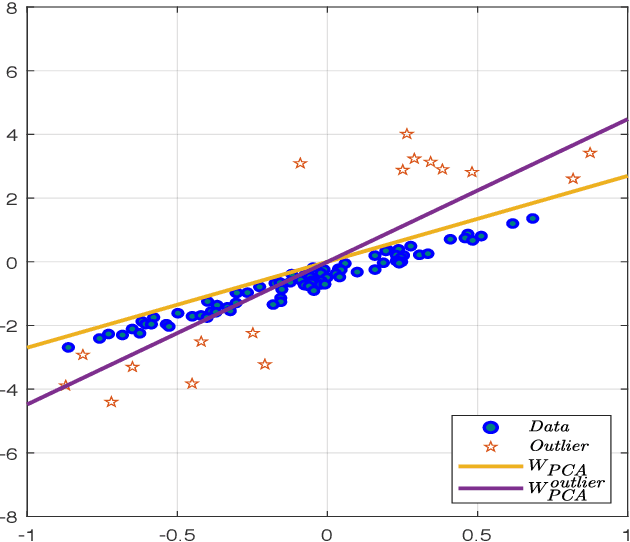
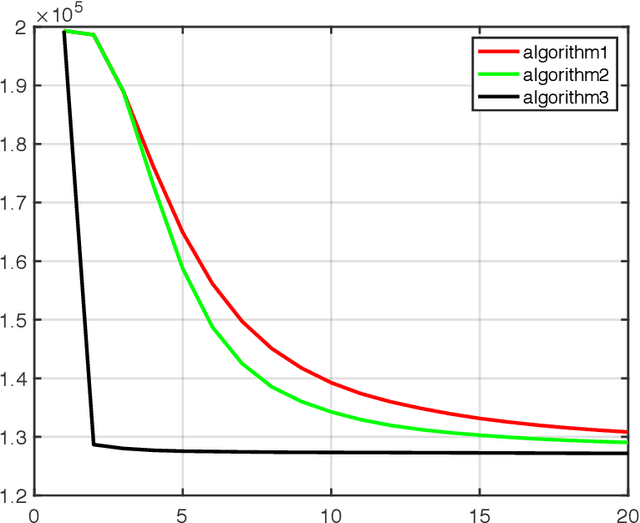
In this paper we propose a novel optimization framework to systematically solve robust PCA problem with rigorous theoretical guarantee, based on which we investigate very computationally economic updating algorithms.