 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Encoded Stochastic Variational Inference
Dec 19, 2019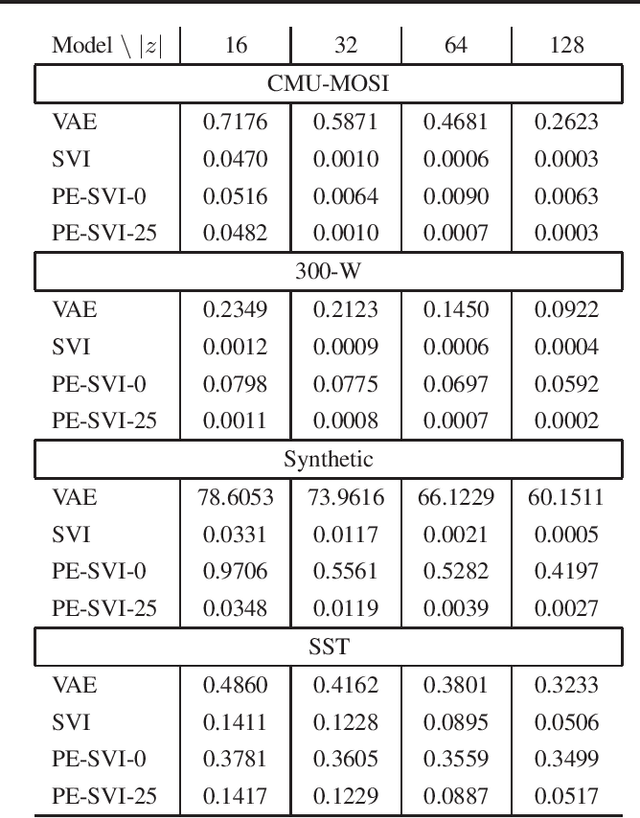
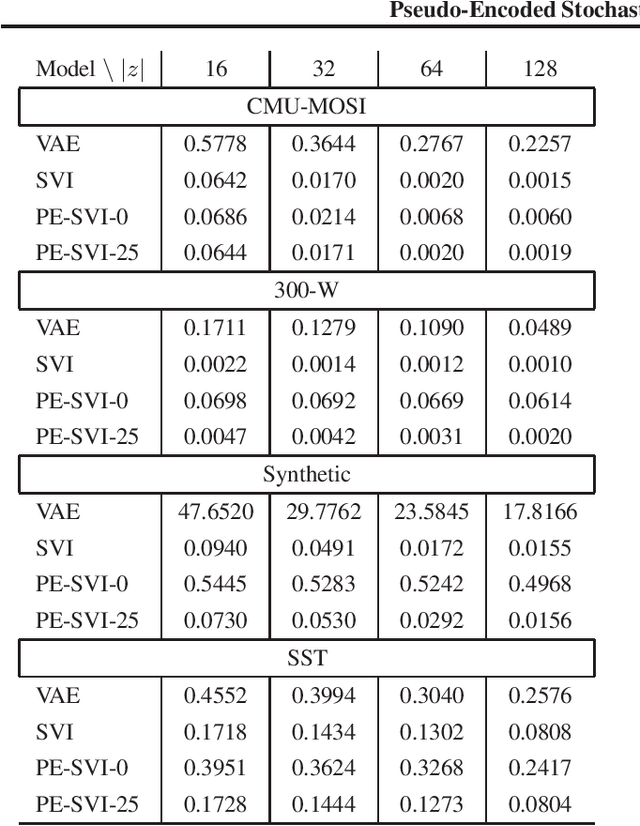
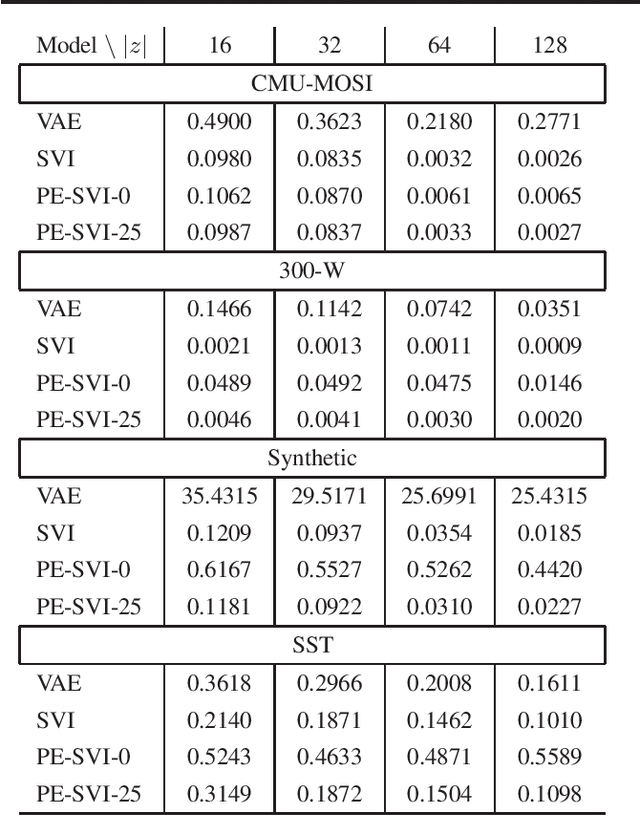
Posterior inference in directed graphical models is commonly done using a probabilistic encoder (a.k.a inference model) conditioned on the input. Often this inference model is trained jointly with the probabilistic decoder (a.k.a generator model). If probabilistic encoder encounters complexities during training (e.g. suboptimal complxity or parameterization), then learning reaches a suboptimal objective; a phenomena commonly called inference suboptimality. In Variational Inference (VI), optimizing the ELBo using Stochastic Variational Inference (SVI) can eliminate the inference suboptimality (as demonstrated in this paper), however, this solution comes at a substantial computational cost when inference needs to be done on new data points. Essentially, a long sequential chain of gradient updates is required to fully optimize approximate posteriors. In this paper, we present an approach called Pseudo-Encoded Stochastic Variational Inference (PE-SVI), to reduce the inference complexity of SVI during test time. Our approach relies on finding a suitable initial start point for gradient operations, which naturally reduces the required gradient steps. Furthermore, this initialization allows for adopting larger step sizes (compared to random initialization used in SVI), which further reduces the inference time complexity. PE-SVI reaches the same ELBo objective as SVI using less than one percent of required steps, on average.
Variational Auto-Decoder
Apr 03, 2019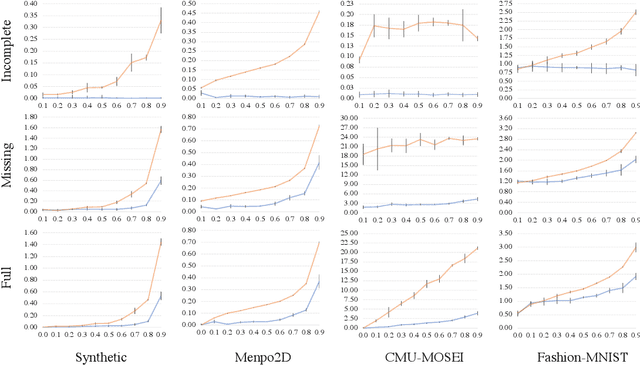
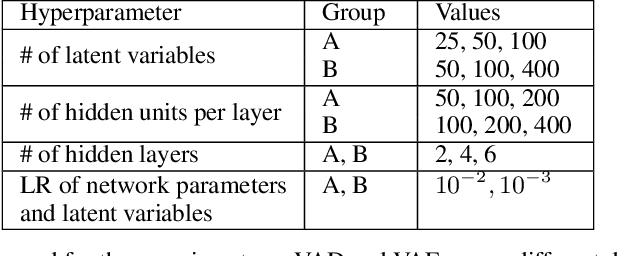
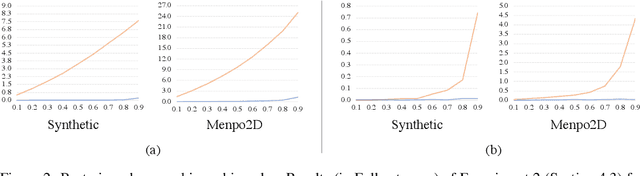
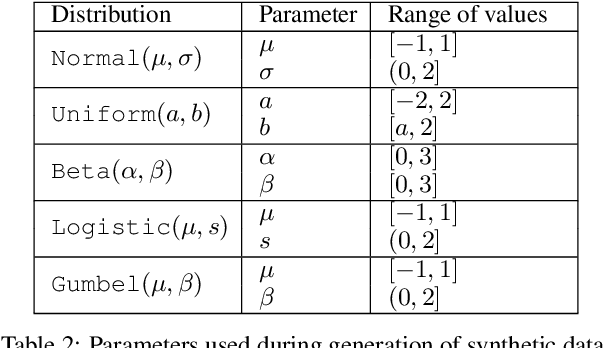
Learning a generative model from partial data (data with missingness) is a challenging area of machine learning research. We study a specific implementation of the Auto-Encoding Variational Bayes (AEVB) algorithm, named in this paper as a Variational Auto-Decoder (VAD). VAD is a generic framework which uses Variational Bayes and Markov Chain Monte Carlo (MCMC) methods to learn a generative model from partial data. The main distinction between VAD and Variational Auto-Encoder (VAE) is the encoder component, as VAD does not have one. Using a proposed efficient inference method from a multivariate Gaussian approximate posterior, VAD models allow inference to be performed via simple gradient ascent rather than MCMC sampling from a probabilistic decoder. This technique reduces the inference computational cost, allows for using more complex optimization techniques during latent space inference (which are shown to be crucial due to a high degree of freedom in the VAD latent space), and keeps the framework simple to implement. Through extensive experiments over several datasets and different missing ratios, we show that encoders cannot efficiently marginalize the input volatility caused by imputed missing values. We study multimodal datasets in this paper, which is a particular area of impact for VAD models.