 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRAQuant: Mixed-Precision Quantization of LoRA to Ultra-Low Bits
Oct 30, 2025Low-Rank Adaptation (LoRA) has become a popular technique for parameter-efficient fine-tuning of large language models (LLMs). In many real-world scenarios, multiple adapters are loaded simultaneously to enable LLM customization for personalized user experiences or to support a diverse range of tasks. Although each adapter is lightweight in isolation, their aggregate cost becomes substantial at scale. To address this, we propose LoRAQuant, a mixed-precision post-training quantization method tailored to LoRA. Specifically, LoRAQuant reparameterizes each adapter by singular value decomposition (SVD) to concentrate the most important information into specific rows and columns. This makes it possible to quantize the important components to higher precision, while quantizing the rest to ultra-low bitwidth. We conduct comprehensive experiments with LLaMA 2-7B, LLaMA 2-13B, and Mistral 7B models on mathematical reasoning, coding, and summarization tasks. Results show that our LoRAQuant uses significantly lower bits than other quantization methods, but achieves comparable or even higher performance.
Can LLMs Reason Abstractly Over Math Word Problems Without CoT? Disentangling Abstract Formulation From Arithmetic Computation
May 29, 2025



Final-answer-based metrics are commonly used for evaluating large language models (LLMs) on math word problems, often taken as proxies for reasoning ability. However, such metrics conflate two distinct sub-skills: abstract formulation (capturing mathematical relationships using expressions) and arithmetic computation (executing the calculations). Through a disentangled evaluation on GSM8K and SVAMP, we find that the final-answer accuracy of Llama-3 and Qwen2.5 (1B-32B) without CoT is overwhelmingly bottlenecked by the arithmetic computation step and not by the abstract formulation step. Contrary to the common belief, we show that CoT primarily aids in computation, with limited impact on abstract formulation. Mechanistically, we show that these two skills are composed conjunctively even in a single forward pass without any reasoning steps via an abstract-then-compute mechanism: models first capture problem abstractions, then handle computation. Causal patching confirms these abstractions are present, transferable, composable, and precede computation. These behavioural and mechanistic findings highlight the need for disentangled evaluation to accurately assess LLM reasoning and to guide future improvements.
NeuZip: Memory-Efficient Training and Inference with Dynamic Compression of Neural Networks
Oct 28, 2024



The performance of neural networks improves when more parameters are used. However, the model sizes are constrained by the available on-device memory during training and inference. Although applying techniques like quantization can alleviate the constraint, they suffer from performance degradation. In this work, we introduce NeuZip, a new weight compression scheme based on the entropy of floating-point numbers in neural networks. With NeuZip, we are able to achieve memory-efficient training and inference without sacrificing performance. Notably, we significantly reduce the memory footprint of training a Llama-3 8B model from 31GB to less than 16GB, while keeping the training dynamics fully unchanged. In inference, our method can reduce memory usage by more than half while maintaining near-lossless performance. Our code is publicly available.
Leveraging Environment Interaction for Automated PDDL Generation and Planning with Large Language Models
Jul 17, 2024



Large Language Models (LLMs) have shown remarkable performance in various natural language tasks, but they often struggle with planning problems that require structured reasoning. To address this limitation, the conversion of planning problems into the Planning Domain Definition Language (PDDL) has been proposed as a potential solution, enabling the use of automated planners. However, generating accurate PDDL files typically demands human inputs or correction, which can be time-consuming and costly. In this paper, we propose a novel approach that leverages LLMs and environment feedback to automatically generate PDDL domain and problem description files without the need for human intervention. Our method introduces an iterative refinement process that generates multiple problem PDDL candidates and progressively refines the domain PDDL based on feedback obtained from interacting with the environment. To guide the refinement process, we develop an Exploration Walk (EW) metric, which provides rich feedback signals for LLMs to update the PDDL file. We evaluate our approach on PDDL environments. We achieve an average task solve rate of 66% compared to a 29% solve rate by GPT-4's intrinsic planning with chain-of-thought prompting. Our work enables the automated modeling of planning environments using LLMs and environment feedback, eliminating the need for human intervention in the PDDL generation process and paving the way for more reliable LLM agents in challenging problems.
Jump Starting Bandits with LLM-Generated Prior Knowledge
Jun 27, 2024



We present substantial evidence demonstrating the benefits of integrating Large Language Models (LLMs) with a Contextual Multi-Armed Bandit framework. Contextual bandits have been widely used in recommendation systems to generate personalized suggestions based on user-specific contexts. We show that LLMs, pre-trained on extensive corpora rich in human knowledge and preferences, can simulate human behaviours well enough to jump-start contextual multi-armed bandits to reduce online learning regret. We propose an initialization algorithm for contextual bandits by prompting LLMs to produce a pre-training dataset of approximate human preferences for the bandit. This significantly reduces online learning regret and data-gathering costs for training such models. Our approach is validated empirically through two sets of experiments with different bandit setups: one which utilizes LLMs to serve as an oracle and a real-world experiment utilizing data from a conjoint survey experiment.
EBBS: An Ensemble with Bi-Level Beam Search for Zero-Shot Machine Translation
Feb 29, 2024



The ability of zero-shot translation emerges when we train a multilingual model with certain translation directions; the model can then directly translate in unseen directions. Alternatively, zero-shot translation can be accomplished by pivoting through a third language (e.g., English). In our work, we observe that both direct and pivot translations are noisy and achieve less satisfactory performance. We propose EBBS, an ensemble method with a novel bi-level beam search algorithm, where each ensemble component explores its own prediction step by step at the lower level but they are synchronized by a "soft voting" mechanism at the upper level. Results on two popular multilingual translation datasets show that EBBS consistently outperforms direct and pivot translations as well as existing ensemble techniques. Further, we can distill the ensemble's knowledge back to the multilingual model to improve inference efficiency; profoundly, our EBBS-based distillation does not sacrifice, or even improves, the translation quality.
Ginger: An Efficient Curvature Approximation with Linear Complexity for General Neural Networks
Feb 05, 2024


Second-order optimization approaches like the generalized Gauss-Newton method are considered more powerful as they utilize the curvature information of the objective function with preconditioning matrices. Albeit offering tempting theoretical benefits, they are not easily applicable to modern deep learning. The major reason is due to the quadratic memory and cubic time complexity to compute the inverse of the matrix. These requirements are infeasible even with state-of-the-art hardware. In this work, we propose Ginger, an eigendecomposition for the inverse of the generalized Gauss-Newton matrix. Our method enjoys efficient linear memory and time complexity for each iteration. Instead of approximating the conditioning matrix, we directly maintain its inverse to make the approximation more accurate. We provide the convergence result of Ginger for non-convex objectives. Our experiments on different tasks with different model architectures verify the effectiveness of our method. Our code is publicly available.
Flora: Low-Rank Adapters Are Secretly Gradient Compressors
Feb 05, 2024



Despite large neural networks demonstrating remarkable abilities to complete different tasks, they require excessive memory usage to store the optimization states for training. To alleviate this, the low-rank adaptation (LoRA) is proposed to reduce the optimization states by training fewer parameters. However, LoRA restricts overall weight update matrices to be low-rank, limiting the model performance. In this work, we investigate the dynamics of LoRA and identify that it can be approximated by a random projection. Based on this observation, we propose Flora, which is able to achieve high-rank updates by resampling the projection matrices while enjoying the sublinear space complexity of optimization states. We conduct experiments across different tasks and model architectures to verify the effectiveness of our approach.
Ensemble Distillation for Unsupervised Constituency Parsing
Oct 03, 2023We investigate the unsupervised constituency parsing task, which organizes words and phrases of a sentence into a hierarchical structure without using linguistically annotated data. We observe that existing unsupervised parsers capture differing aspects of parsing structures, which can be leveraged to enhance unsupervised parsing performance. To this end, we propose a notion of "tree averaging," based on which we further propose a novel ensemble method for unsupervised parsing. To improve inference efficiency, we further distill the ensemble knowledge into a student model; such an ensemble-then-distill process is an effective approach to mitigate the over-smoothing problem existing in common multi-teacher distilling methods. Experiments show that our method surpasses all previous approaches, consistently demonstrating its effectiveness and robustness across various runs, with different ensemble components, and under domain-shift conditions.
An Equal-Size Hard EM Algorithm for Diverse Dialogue Generation
Sep 29, 2022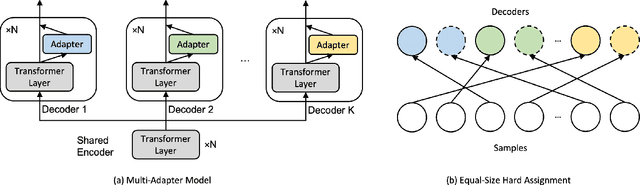
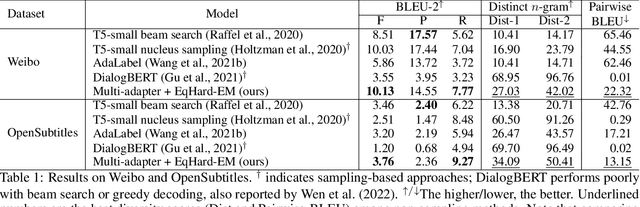
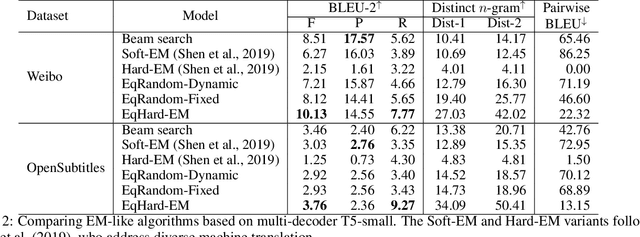
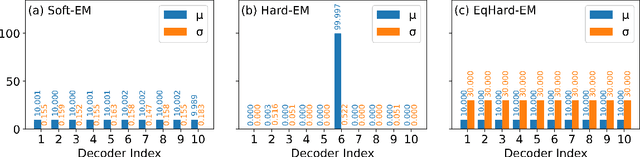
Open-domain dialogue systems aim to interact with humans through natural language texts in an open-ended fashion. However, the widely successful neural networks may not work well for dialogue systems, as they tend to generate generic responses. In this work, we propose an Equal-size Hard Expectation--Maximization (EqHard-EM) algorithm to train a multi-decoder model for diverse dialogue generation. Our algorithm assigns a sample to a decoder in a hard manner and additionally imposes an equal-assignment constraint to ensure that all decoders are well-trained. We provide detailed theoretical analysis to justify our approach. Further, experiments on two large-scale, open-domain dialogue datasets verify that our EqHard-EM algorithm generates high-quality diverse responses.