 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Reason Abstractly Over Math Word Problems Without CoT? Disentangling Abstract Formulation From Arithmetic Computation
May 29, 2025



Final-answer-based metrics are commonly used for evaluating large language models (LLMs) on math word problems, often taken as proxies for reasoning ability. However, such metrics conflate two distinct sub-skills: abstract formulation (capturing mathematical relationships using expressions) and arithmetic computation (executing the calculations). Through a disentangled evaluation on GSM8K and SVAMP, we find that the final-answer accuracy of Llama-3 and Qwen2.5 (1B-32B) without CoT is overwhelmingly bottlenecked by the arithmetic computation step and not by the abstract formulation step. Contrary to the common belief, we show that CoT primarily aids in computation, with limited impact on abstract formulation. Mechanistically, we show that these two skills are composed conjunctively even in a single forward pass without any reasoning steps via an abstract-then-compute mechanism: models first capture problem abstractions, then handle computation. Causal patching confirms these abstractions are present, transferable, composable, and precede computation. These behavioural and mechanistic findings highlight the need for disentangled evaluation to accurately assess LLM reasoning and to guide future improvements.
SAGE: Saliency-Guided Mixup with Optimal Rearrangements
Oct 31, 2022



Data augmentation is a key element for training accurate models by reducing overfitting and improving generalization. For image classification, the most popular data augmentation techniques range from simple photometric and geometrical transformations, to more complex methods that use visual saliency to craft new training examples. As augmentation methods get more complex, their ability to increase the test accuracy improves, yet, such methods become cumbersome, inefficient and lead to poor out-of-domain generalization, as we show in this paper. This motivates a new augmentation technique that allows for high accuracy gains while being simple, efficient (i.e., minimal computation overhead) and generalizable. To this end, we introduce Saliency-Guided Mixup with Optimal Rearrangements (SAGE), which creates new training examples by rearranging and mixing image pairs using visual saliency as guidance. By explicitly leveraging saliency, SAGE promotes discriminative foreground objects and produces informative new images useful for training. We demonstrate on CIFAR-10 and CIFAR-100 that SAGE achieves better or comparable performance to the state of the art while being more efficient. Additionally, evaluations in the out-of-distribution setting, and few-shot learning on mini-ImageNet, show that SAGE achieves improved generalization performance without trading off robustness.
Uncertainty-based Cross-Modal Retrieval with Probabilistic Representations
Apr 20, 2022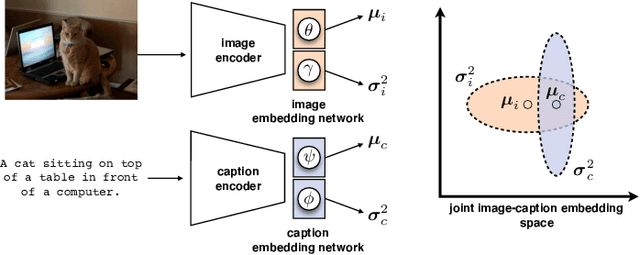
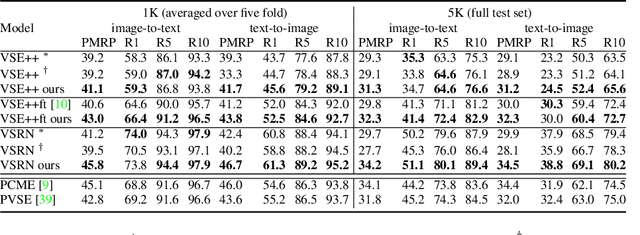
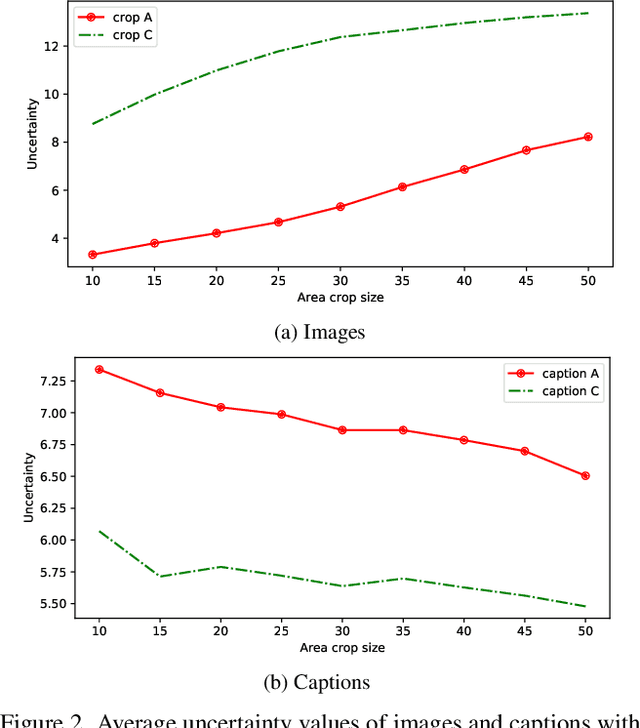
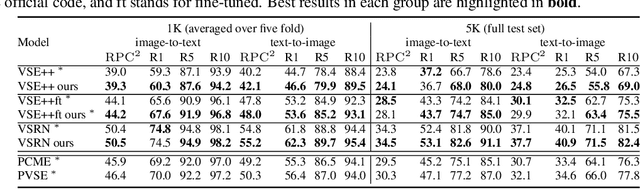
Probabilistic embeddings have proven useful for capturing polysemous word meanings, as well as ambiguity in image matching. In this paper, we study the advantages of probabilistic embeddings in a cross-modal setting (i.e., text and images), and propose a simple approach that replaces the standard vector point embeddings in extant image-text matching models with probabilistic distributions that are parametrically learned. Our guiding hypothesis is that the uncertainty encoded in the probabilistic embeddings captures the cross-modal ambiguity in the input instances, and that it is through capturing this uncertainty that the probabilistic models can perform better at downstream tasks, such as image-to-text or text-to-image retrieval. Through extensive experiments on standard and new benchmarks, we show a consistent advantage for probabilistic representations in cross-modal retrieval, and validate the ability of our embeddings to capture uncertainty.