 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINTERSPEECH 2021 ConferencingSpeech Challenge: Towards Far-field Multi-Channel Speech Enhancement for Video Conferencing
Apr 02, 2021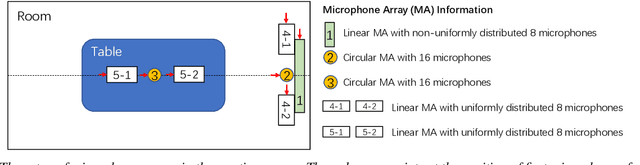

The ConferencingSpeech 2021 challenge is proposed to stimulate research on far-field multi-channel speech enhancement for video conferencing. The challenge consists of two separate tasks: 1) Task 1 is multi-channel speech enhancement with single microphone array and focusing on practical application with real-time requirement and 2) Task 2 is multi-channel speech enhancement with multiple distributed microphone arrays, which is a non-real-time track and does not have any constraints so that participants could explore any algorithms to obtain high speech quality. Targeting the real video conferencing room application, the challenge database was recorded from real speakers and all recording facilities were located by following the real setup of conferencing room. In this challenge, we open-sourced the list of open source clean speech and noise datasets, simulation scripts, and a baseline system for participants to develop their own system. The final ranking of the challenge will be decided by the subjective evaluation which is performed using Absolute Category Ratings (ACR) to estimate Mean Opinion Score (MOS), speech MOS (S-MOS), and noise MOS (N-MOS). This paper describes the challenge, tasks, datasets, and subjective evaluation. The baseline system which is a complex ratio mask based neural network and its experimental results are also presented.
A Two-Stage Approach to Device-Robust Acoustic Scene Classification
Nov 03, 2020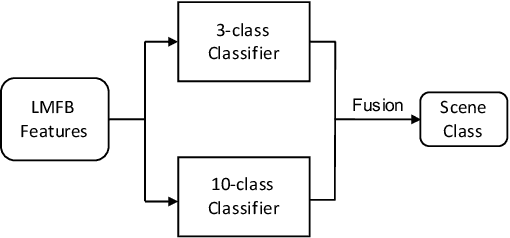

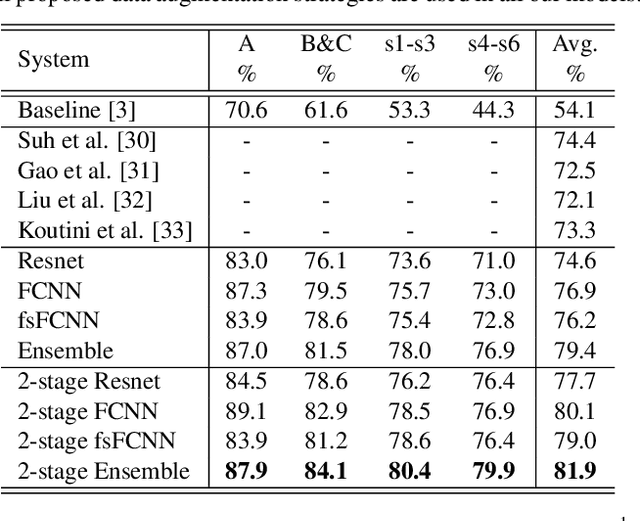
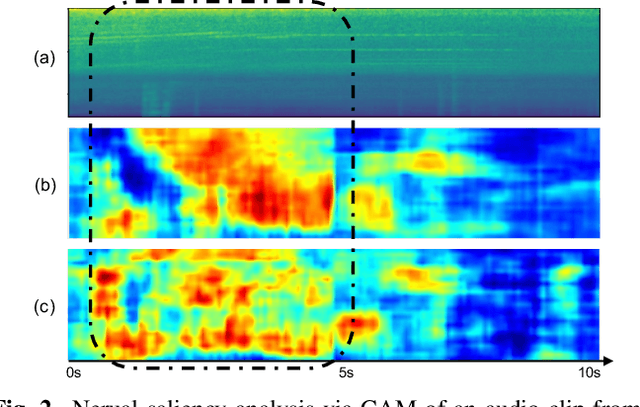
To improve device robustness, a highly desirable key feature of a competitive data-driven acoustic scene classification (ASC) system, a novel two-stage system based on fully convolutional neural networks (CNNs) is proposed. Our two-stage system leverages on an ad-hoc score combination based on two CNN classifiers: (i) the first CNN classifies acoustic inputs into one of three broad classes, and (ii) the second CNN classifies the same inputs into one of ten finer-grained classes. Three different CNN architectures are explored to implement the two-stage classifiers, and a frequency sub-sampling scheme is investigated. Moreover, novel data augmentation schemes for ASC are also investigated. Evaluated on DCASE 2020 Task 1a, our results show that the proposed ASC system attains a state-of-the-art accuracy on the development set, where our best system, a two-stage fusion of CNN ensembles, delivers a 81.9% average accuracy among multi-device test data, and it obtains a significant improvement on unseen devices. Finally, neural saliency analysis with class activation mapping (CAM) gives new insights on the patterns learnt by our models.
Device-Robust Acoustic Scene Classification Based on Two-Stage Categorization and Data Augmentation
Aug 27, 2020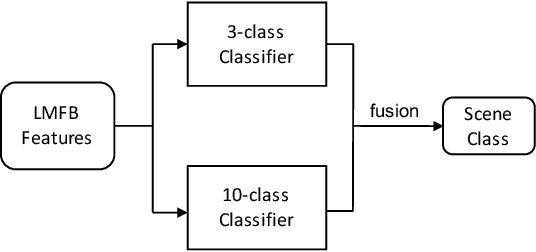
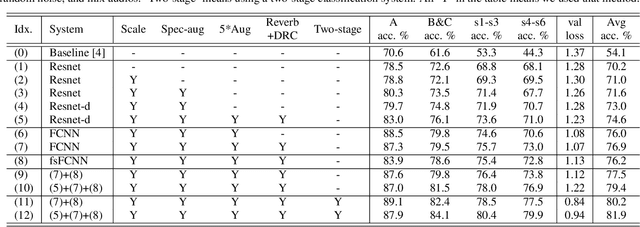
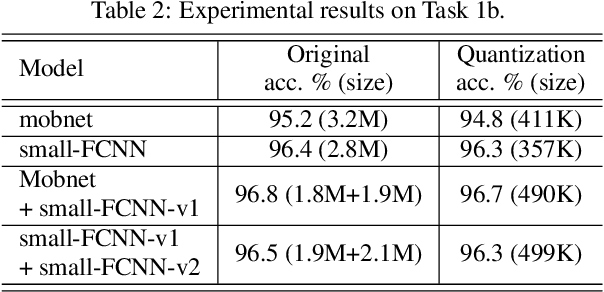
In this technical report, we present a joint effort of four groups, namely GT, USTC, Tencent, and UKE, to tackle Task 1 - Acoustic Scene Classification (ASC) in the DCASE 2020 Challenge. Task 1 comprises two different sub-tasks: (i) Task 1a focuses on ASC of audio signals recorded with multiple (real and simulated) devices into ten different fine-grained classes, and (ii) Task 1b concerns with classification of data into three higher-level classes using low-complexity solutions. For Task 1a, we propose a novel two-stage ASC system leveraging upon ad-hoc score combination of two convolutional neural networks (CNNs), classifying the acoustic input according to three classes, and then ten classes, respectively. Four different CNN-based architectures are explored to implement the two-stage classifiers, and several data augmentation techniques are also investigated. For Task 1b, we leverage upon a quantization method to reduce the complexity of two of our top-accuracy three-classes CNN-based architectures. On Task 1a development data set, an ASC accuracy of 76.9\% is attained using our best single classifier and data augmentation. An accuracy of 81.9\% is then attained by a final model fusion of our two-stage ASC classifiers. On Task 1b development data set, we achieve an accuracy of 96.7\% with a model size smaller than 500KB. Code is available: https://github.com/MihawkHu/DCASE2020_task1.
Exploring Deep Hybrid Tensor-to-Vector Network Architectures for Regression Based Speech Enhancement
Aug 03, 2020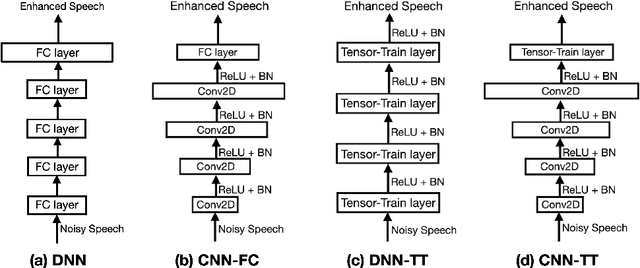
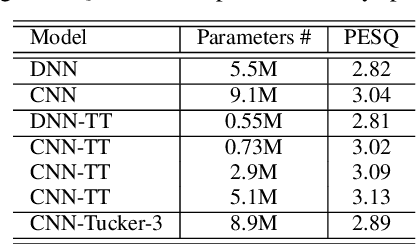
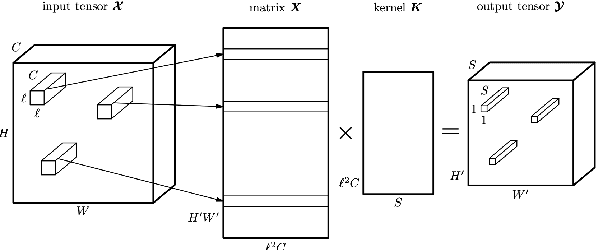
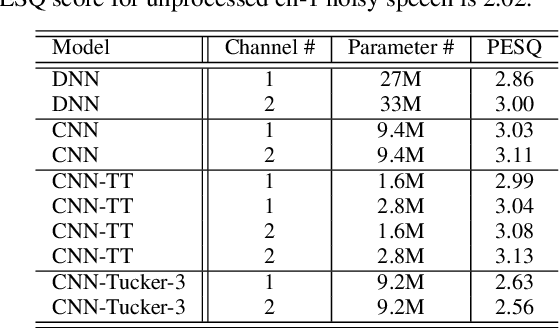
This paper investigates different trade-offs between the number of model parameters and enhanced speech qualities by employing several deep tensor-to-vector regression models for speech enhancement. We find that a hybrid architecture, namely CNN-TT, is capable of maintaining a good quality performance with a reduced model parameter size. CNN-TT is composed of several convolutional layers at the bottom for feature extraction to improve speech quality and a tensor-train (TT) output layer on the top to reduce model parameters. We first derive a new upper bound on the generalization power of the convolutional neural network (CNN) based vector-to-vector regression models. Then, we provide experimental evidence on the Edinburgh noisy speech corpus to demonstrate that, in single-channel speech enhancement, CNN outperforms DNN at the expense of a small increment of model sizes. Besides, CNN-TT slightly outperforms the CNN counterpart by utilizing only 32\% of the CNN model parameters. Besides, further performance improvement can be attained if the number of CNN-TT parameters is increased to 44\% of the CNN model size. Finally, our experiments of multi-channel speech enhancement on a simulated noisy WSJ0 corpus demonstrate that our proposed hybrid CNN-TT architecture achieves better results than both DNN and CNN models in terms of better-enhanced speech qualities and smaller parameter sizes.
Relational Teacher Student Learning with Neural Label Embedding for Device Adaptation in Acoustic Scene Classification
Jul 31, 2020
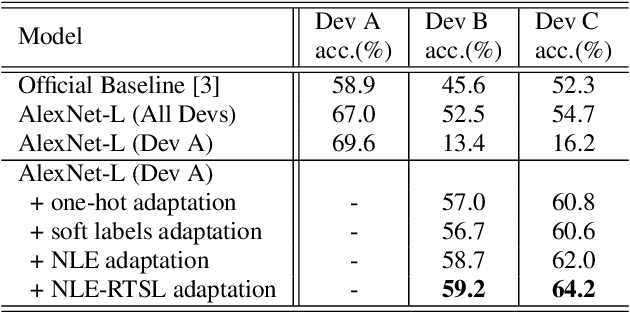
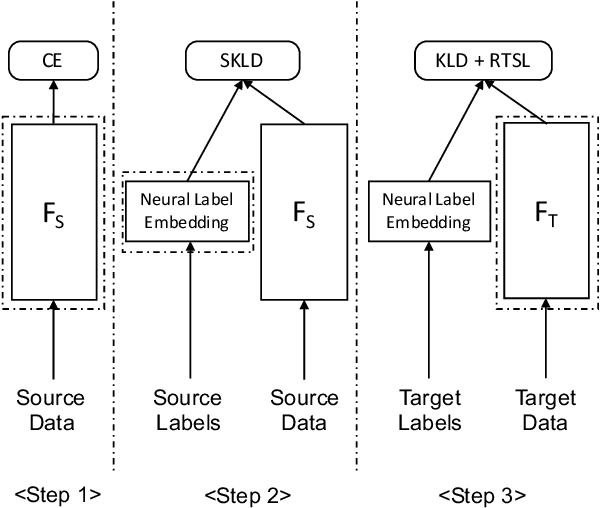

In this paper, we propose a domain adaptation framework to address the device mismatch issue in acoustic scene classification leveraging upon neural label embedding (NLE) and relational teacher student learning (RTSL). Taking into account the structural relationships between acoustic scene classes, our proposed framework captures such relationships which are intrinsically device-independent. In the training stage, transferable knowledge is condensed in NLE from the source domain. Next in the adaptation stage, a novel RTSL strategy is adopted to learn adapted target models without using paired source-target data often required in conventional teacher student learning. The proposed framework is evaluated on the DCASE 2018 Task1b data set. Experimental results based on AlexNet-L deep classification models confirm the effectiveness of our proposed approach for mismatch situations. NLE-alone adaptation compares favourably with the conventional device adaptation and teacher student based adaptation techniques. NLE with RTSL further improves the classification accuracy.
An Acoustic Segment Model Based Segment Unit Selection Approach to Acoustic Scene Classification with Partial Utterances
Jul 31, 2020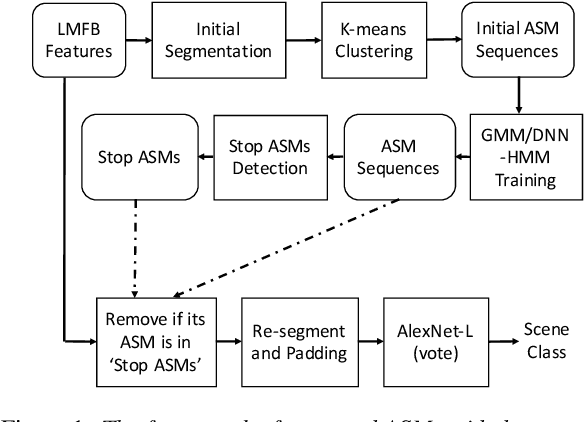
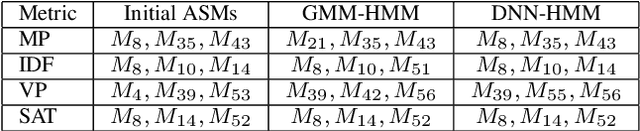

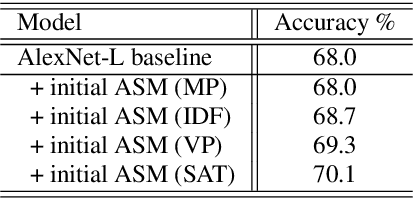
In this paper, we propose a sub-utterance unit selection framework to remove acoustic segments in audio recordings that carry little information for acoustic scene classification (ASC). Our approach is built upon a universal set of acoustic segment units covering the overall acoustic scene space. First, those units are modeled with acoustic segment models (ASMs) used to tokenize acoustic scene utterances into sequences of acoustic segment units. Next, paralleling the idea of stop words in information retrieval, stop ASMs are automatically detected. Finally, acoustic segments associated with the stop ASMs are blocked, because of their low indexing power in retrieval of most acoustic scenes. In contrast to building scene models with whole utterances, the ASM-removed sub-utterances, i.e., acoustic utterances without stop acoustic segments, are then used as inputs to the AlexNet-L back-end for final classification. On the DCASE 2018 dataset, scene classification accuracy increases from 68%, with whole utterances, to 72.1%, with segment selection. This represents a competitive accuracy without any data augmentation, and/or ensemble strategy. Moreover, our approach compares favourably to AlexNet-L with attention.
Tensor-to-Vector Regression for Multi-channel Speech Enhancement based on Tensor-Train Network
Feb 03, 2020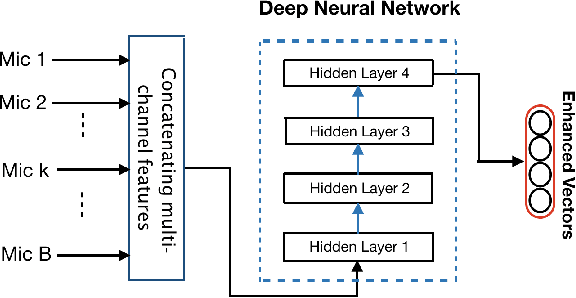
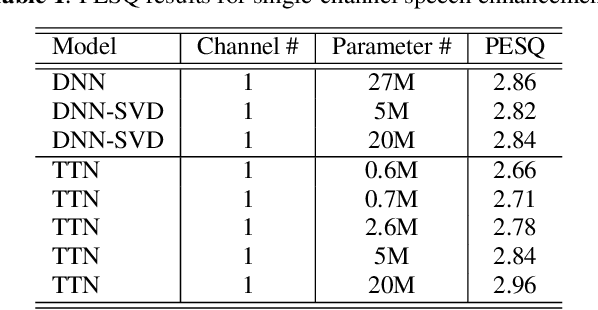
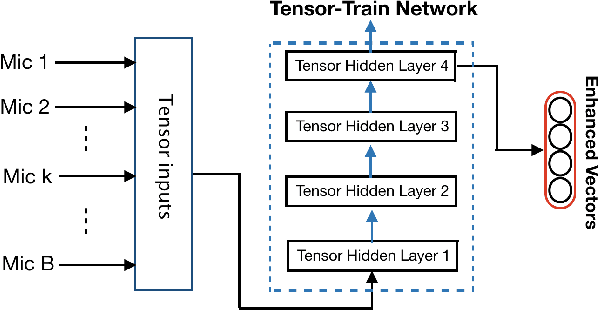
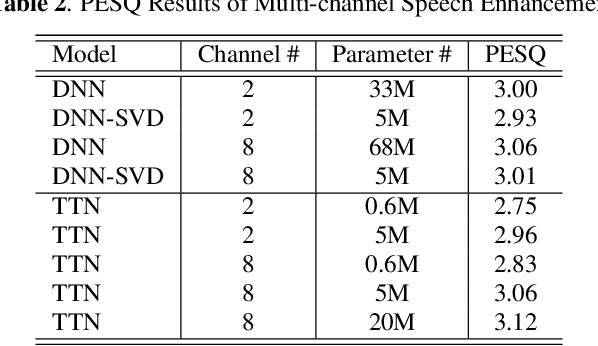
We propose a tensor-to-vector regression approach to multi-channel speech enhancement in order to address the issue of input size explosion and hidden-layer size expansion. The key idea is to cast the conventional deep neural network (DNN) based vector-to-vector regression formulation under a tensor-train network (TTN) framework. TTN is a recently emerged solution for compact representation of deep models with fully connected hidden layers. Thus TTN maintains DNN's expressive power yet involves a much smaller amount of trainable parameters. Furthermore, TTN can handle a multi-dimensional tensor input by design, which exactly matches the desired setting in multi-channel speech enhancement. We first provide a theoretical extension from DNN to TTN based regression. Next, we show that TTN can attain speech enhancement quality comparable with that for DNN but with much fewer parameters, e.g., a reduction from 27 million to only 5 million parameters is observed in a single-channel scenario. TTN also improves PESQ over DNN from 2.86 to 2.96 by slightly increasing the number of trainable parameters. Finally, in 8-channel conditions, a PESQ of 3.12 is achieved using 20 million parameters for TTN, whereas a DNN with 68 million parameters can only attain a PESQ of 3.06. Our implementation is available online https://github.com/uwjunqi/Tensor-Train-Neural-Network.
* Accepted to ICASSP 2020. Update reproducible code