 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite-box Testing of NLP models with Mask Neuron Coverage
May 10, 2022
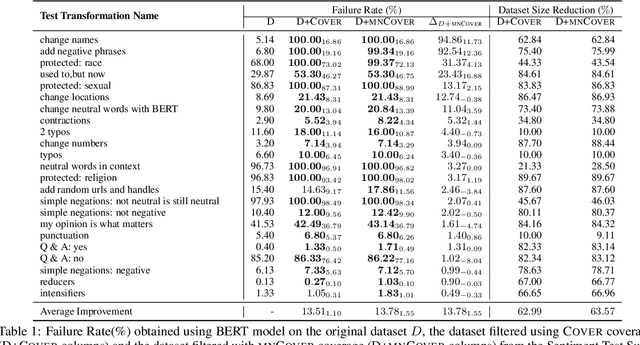
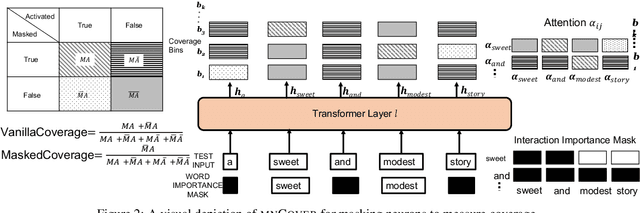
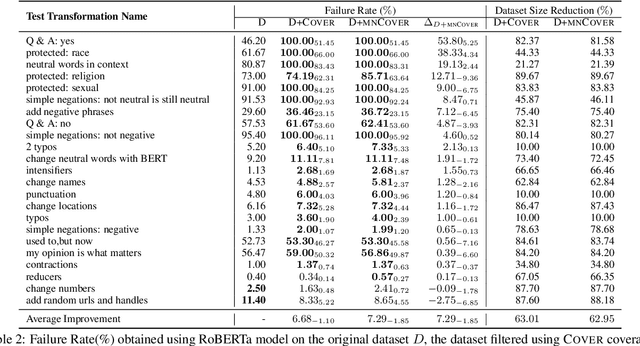
Recent literature has seen growing interest in using black-box strategies like CheckList for testing the behavior of NLP models. Research on white-box testing has developed a number of methods for evaluating how thoroughly the internal behavior of deep models is tested, but they are not applicable to NLP models. We propose a set of white-box testing methods that are customized for transformer-based NLP models. These include Mask Neuron Coverage (MNCOVER) that measures how thoroughly the attention layers in models are exercised during testing. We show that MNCOVER can refine testing suites generated by CheckList by substantially reduce them in size, for more than 60\% on average, while retaining failing tests -- thereby concentrating the fault detection power of the test suite. Further we show how MNCOVER can be used to guide CheckList input generation, evaluate alternative NLP testing methods, and drive data augmentation to improve accuracy.
* Findings of NAACL 2022 submission, 12 pages
Estimating and Maximizing Mutual Information for Knowledge Distillation
Oct 29, 2021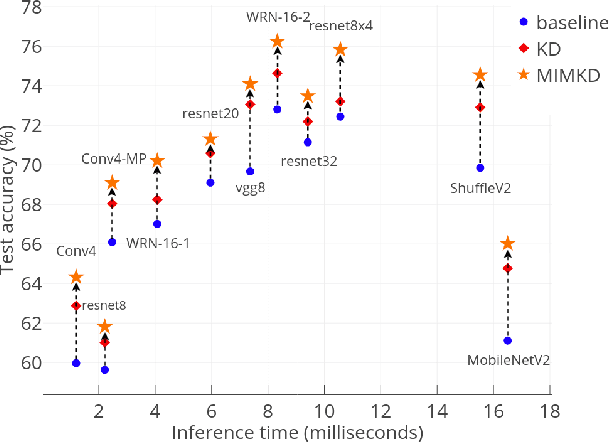
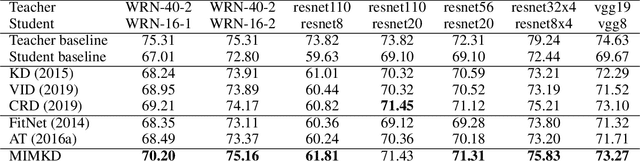
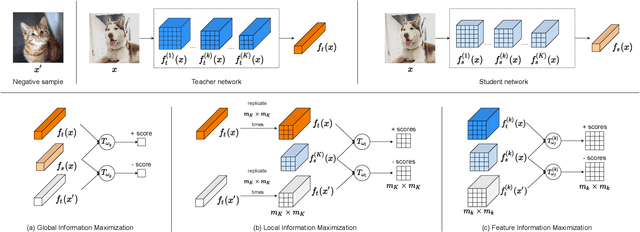
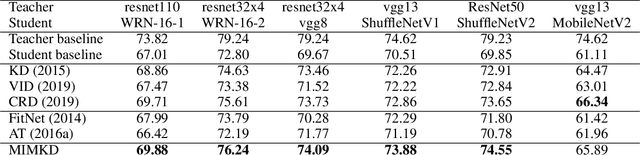
Knowledge distillation is a widely used general technique to transfer knowledge from a teacher network to a student network. In this work, we propose Mutual Information Maximization Knowledge Distillation (MIMKD). Our method uses a contrastive objective to simultaneously estimate and maximize a lower bound on the mutual information between intermediate and global feature representations from the teacher and the student networks. Our method is flexible, as the proposed mutual information maximization does not impose significant constraints on the structure of the intermediate features of the networks. As such, we can distill knowledge from arbitrary teachers to arbitrary students. Our empirical results show that our method outperforms competing approaches across a wide range of student-teacher pairs with different capacities, with different architectures, and when student networks are with extremely low capacity. We are able to obtain 74.55% accuracy on CIFAR100 with a ShufflenetV2 from a baseline accuracy of 69.8% by distilling knowledge from ResNet50.
A Closer Look at Advantage-Filtered Behavioral Cloning in High-Noise Datasets
Oct 10, 2021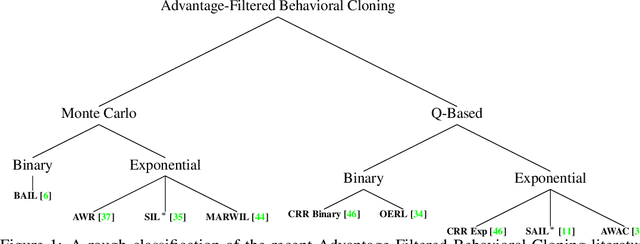
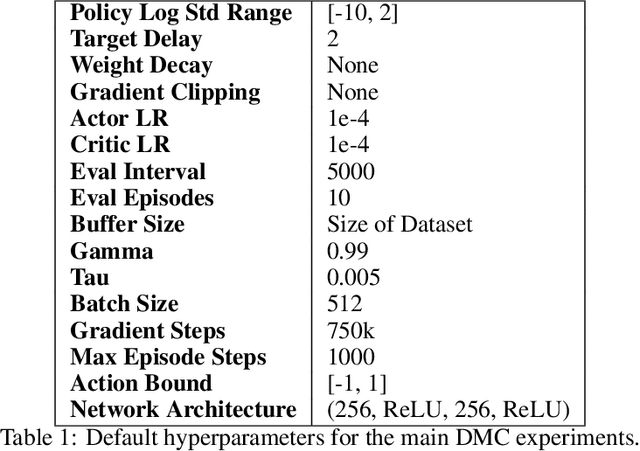
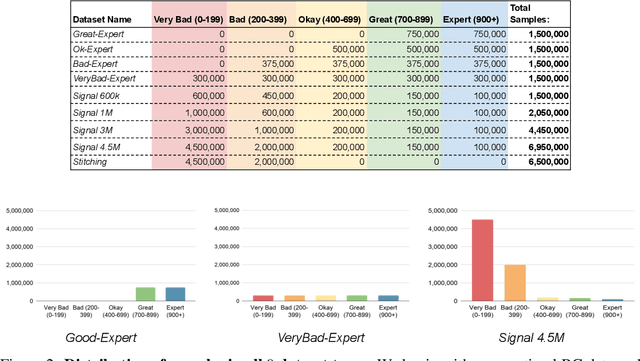

Recent Offline Reinforcement Learning methods have succeeded in learning high-performance policies from fixed datasets of experience. A particularly effective approach learns to first identify and then mimic optimal decision-making strategies. Our work evaluates this method's ability to scale to vast datasets consisting almost entirely of sub-optimal noise. A thorough investigation on a custom benchmark helps identify several key challenges involved in learning from high-noise datasets. We re-purpose prioritized experience sampling to locate expert-level demonstrations among millions of low-performance samples. This modification enables offline agents to learn state-of-the-art policies in benchmark tasks using datasets where expert actions are outnumbered nearly 65:1.
ST-MAML: A Stochastic-Task based Method for Task-Heterogeneous Meta-Learning
Sep 27, 2021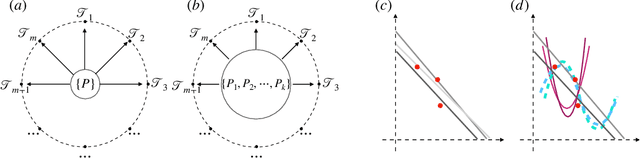
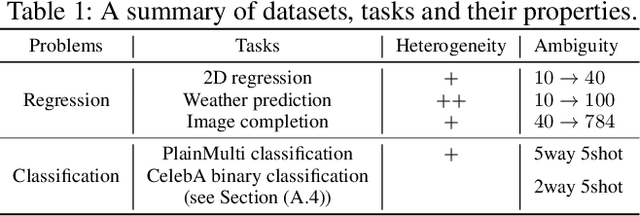
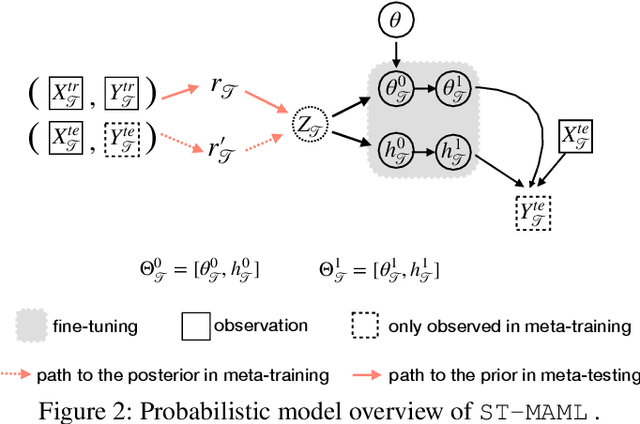

Optimization-based meta-learning typically assumes tasks are sampled from a single distribution - an assumption oversimplifies and limits the diversity of tasks that meta-learning can model. Handling tasks from multiple different distributions is challenging for meta-learning due to a so-called task ambiguity issue. This paper proposes a novel method, ST-MAML, that empowers model-agnostic meta-learning (MAML) to learn from multiple task distributions. ST-MAML encodes tasks using a stochastic neural network module, that summarizes every task with a stochastic representation. The proposed Stochastic Task (ST) strategy allows a meta-model to get tailored for the current task and enables us to learn a distribution of solutions for an ambiguous task. ST-MAML also propagates the task representation to revise the encoding of input variables. Empirically, we demonstrate that ST-MAML matches or outperforms the state-of-the-art on two few-shot image classification tasks, one curve regression benchmark, one image completion problem, and a real-world temperature prediction application. To the best of authors' knowledge, this is the first time optimization-based meta-learning method being applied on a large-scale real-world task.
Long-Range Transformers for Dynamic Spatiotemporal Forecasting
Sep 24, 2021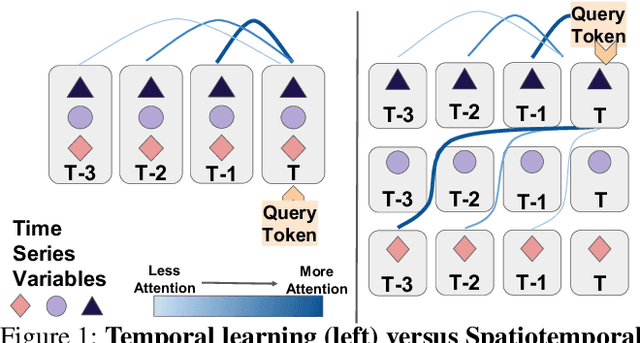
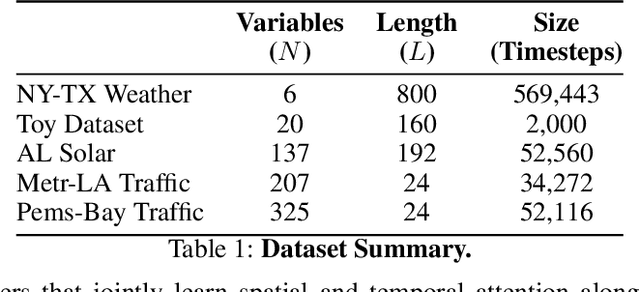
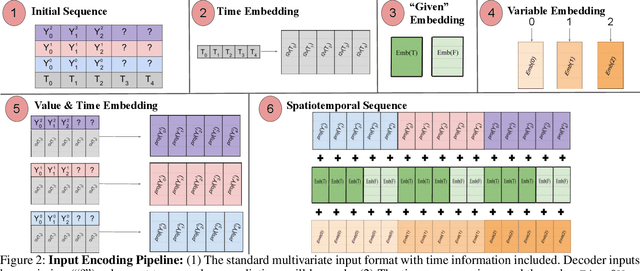
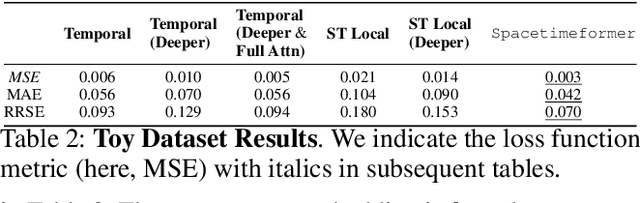
Multivariate Time Series Forecasting (TSF) focuses on the prediction of future values based on historical context. In these problems, dependent variables provide additional information or early warning signs of changes in future behavior. State-of-the-art forecasting models rely on neural attention between timesteps. This allows for temporal learning but fails to consider distinct spatial relationships between variables. This paper addresses the problem by translating multivariate TSF into a novel spatiotemporal sequence formulation where each input token represents the value of a single variable at a given timestep. Long-Range Transformers can then learn interactions between space, time, and value information jointly along this extended sequence. Our method, which we call Spacetimeformer, scales to high dimensional forecasting problems dominated by Graph Neural Networks that rely on predefined variable graphs. We achieve competitive results on benchmarks from traffic forecasting to electricity demand and weather prediction while learning spatial and temporal relationships purely from data.
Towards Improving Adversarial Training of NLP Models
Sep 11, 2021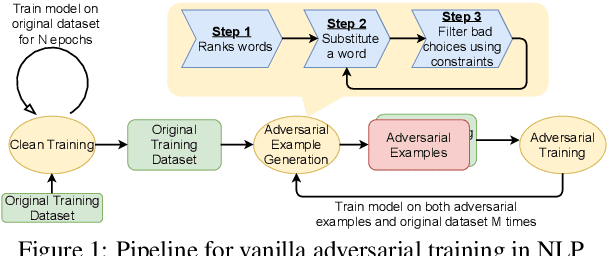


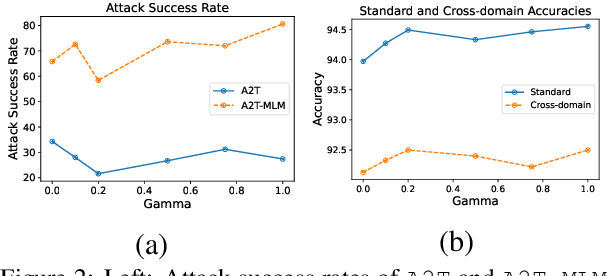
Adversarial training, a method for learning robust deep neural networks, constructs adversarial examples during training. However, recent methods for generating NLP adversarial examples involve combinatorial search and expensive sentence encoders for constraining the generated instances. As a result, it remains challenging to use vanilla adversarial training to improve NLP models' performance, and the benefits are mainly uninvestigated. This paper proposes a simple and improved vanilla adversarial training process for NLP models, which we name Attacking to Training (A2T). The core part of A2T is a new and cheaper word substitution attack optimized for vanilla adversarial training. We use A2T to train BERT and RoBERTa models on IMDB, Rotten Tomatoes, Yelp, and SNLI datasets. Our results empirically show that it is possible to train robust NLP models using a much cheaper adversary. We demonstrate that vanilla adversarial training with A2T can improve an NLP model's robustness to the attack it was originally trained with and also defend the model against other types of word substitution attacks. Furthermore, we show that A2T can improve NLP models' standard accuracy, cross-domain generalization, and interpretability. Code is available at https://github.com/QData/Textattack-A2T .
Perturbing Inputs for Fragile Interpretations in Deep Natural Language Processing
Aug 11, 2021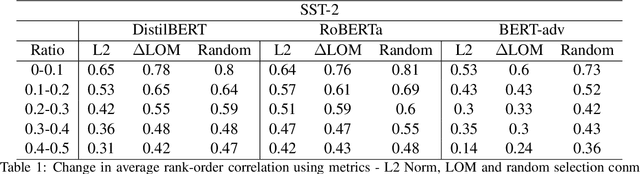
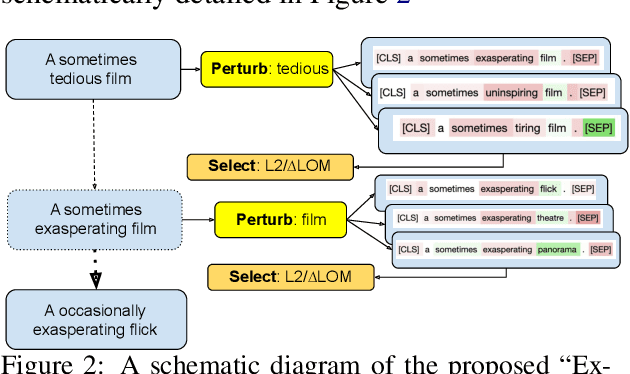
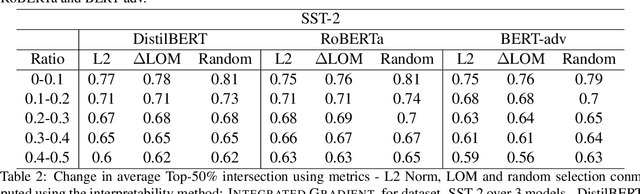
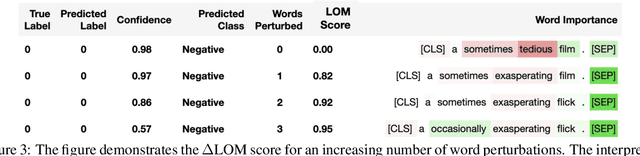
Interpretability methods like Integrated Gradient and LIME are popular choices for explaining natural language model predictions with relative word importance scores. These interpretations need to be robust for trustworthy NLP applications in high-stake areas like medicine or finance. Our paper demonstrates how interpretations can be manipulated by making simple word perturbations on an input text. Via a small portion of word-level swaps, these adversarial perturbations aim to make the resulting text semantically and spatially similar to its seed input (therefore sharing similar interpretations). Simultaneously, the generated examples achieve the same prediction label as the seed yet are given a substantially different explanation by the interpretation methods. Our experiments generate fragile interpretations to attack two SOTA interpretation methods, across three popular Transformer models and on two different NLP datasets. We observe that the rank order correlation drops by over 20% when less than 10% of words are perturbed on average. Further, rank-order correlation keeps decreasing as more words get perturbed. Furthermore, we demonstrate that candidates generated from our method have good quality metrics.
Evolving Image Compositions for Feature Representation Learning
Jun 16, 2021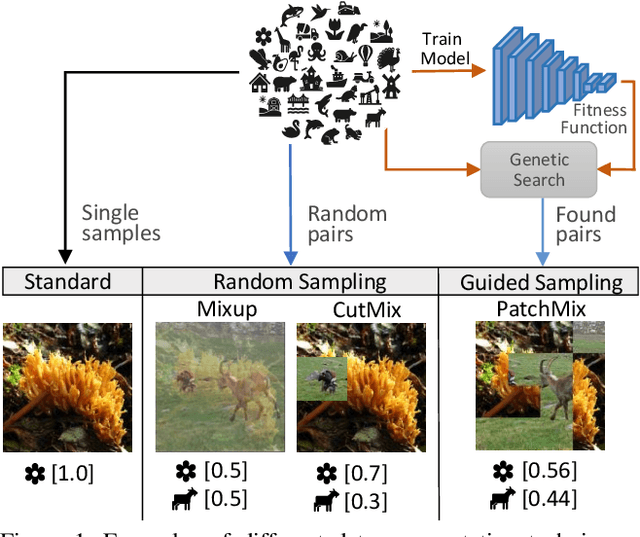
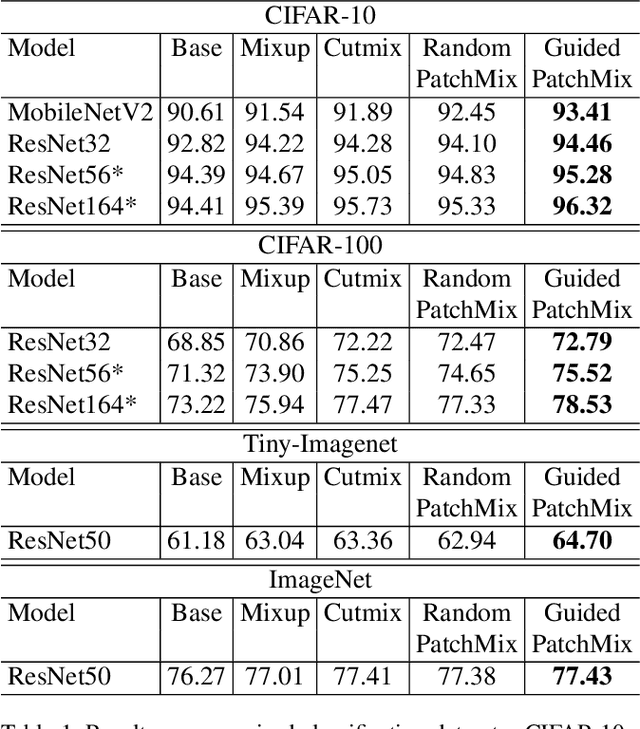
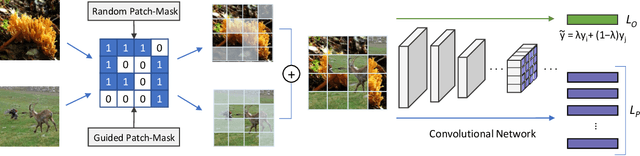
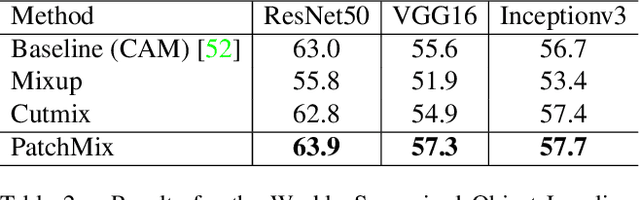
Convolutional neural networks for visual recognition require large amounts of training samples and usually benefit from data augmentation. This paper proposes PatchMix, a data augmentation method that creates new samples by composing patches from pairs of images in a grid-like pattern. These new samples' ground truth labels are set as proportional to the number of patches from each image. We then add a set of additional losses at the patch-level to regularize and to encourage good representations at both the patch and image levels. A ResNet-50 model trained on ImageNet using PatchMix exhibits superior transfer learning capabilities across a wide array of benchmarks. Although PatchMix can rely on random pairings and random grid-like patterns for mixing, we explore evolutionary search as a guiding strategy to discover optimal grid-like patterns and image pairing jointly. For this purpose, we conceive a fitness function that bypasses the need to re-train a model to evaluate each choice. In this way, PatchMix outperforms a base model on CIFAR-10 (+1.91), CIFAR-100 (+5.31), Tiny Imagenet (+3.52), and ImageNet (+1.16) by significant margins, also outperforming previous state-of-the-art pairwise augmentation strategies.
Towards Automatic Actor-Critic Solutions to Continuous Control
Jun 16, 2021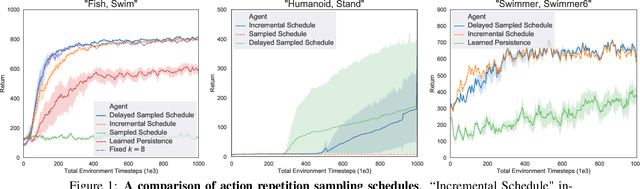

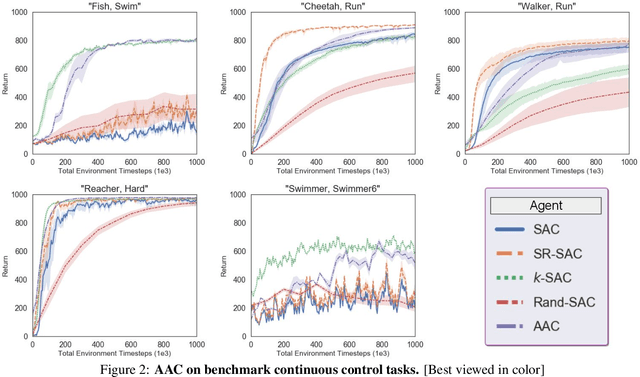

Model-free off-policy actor-critic methods are an efficient solution to complex continuous control tasks. However, these algorithms rely on a number of design tricks and many hyperparameters, making their applications to new domains difficult and computationally expensive. This paper creates an evolutionary approach that automatically tunes these design decisions and eliminates the RL-specific hyperparameters from the Soft Actor-Critic algorithm. Our design is sample efficient and provides practical advantages over baseline approaches, including improved exploration, generalization over multiple control frequencies, and a robust ensemble of high-performance policies. Empirically, we show that our agent outperforms well-tuned hyperparameter settings in popular benchmarks from the DeepMind Control Suite. We then apply it to new control tasks to find high-performance solutions with minimal compute and research effort.
Relate and Predict: Structure-Aware Prediction with Jointly Optimized Neural DAG
Mar 03, 2021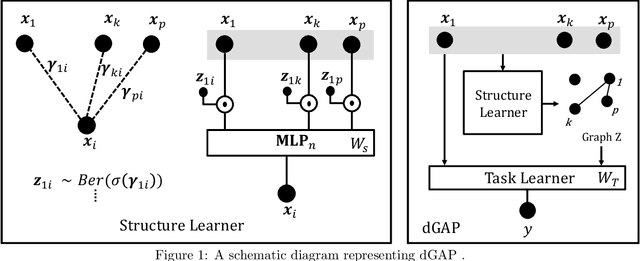
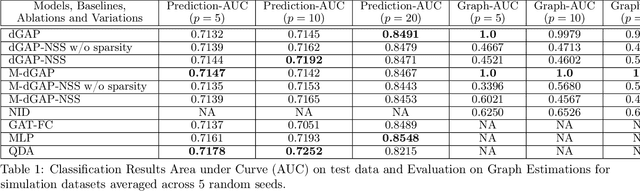
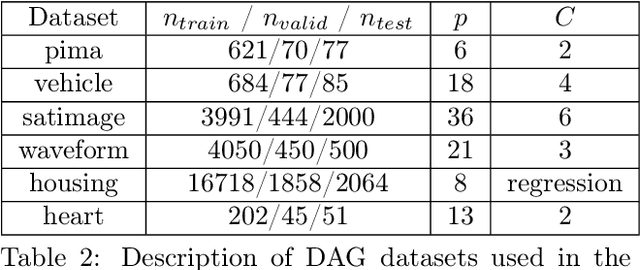
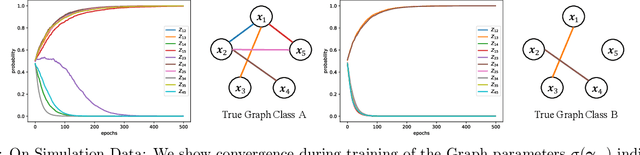
Understanding relationships between feature variables is one important way humans use to make decisions. However, state-of-the-art deep learning studies either focus on task-agnostic statistical dependency learning or do not model explicit feature dependencies during prediction. We propose a deep neural network framework, dGAP, to learn neural dependency Graph and optimize structure-Aware target Prediction simultaneously. dGAP trains towards a structure self-supervision loss and a target prediction loss jointly. Our method leads to an interpretable model that can disentangle sparse feature relationships, informing the user how relevant dependencies impact the target task. We empirically evaluate dGAP on multiple simulated and real datasets. dGAP is not only more accurate, but can also recover correct dependency structure.