 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Hypothesis Testing by Betting on Predictions
May 27, 2026We introduce a testing-by-betting framework that leverages predictions on unlabeled data to enhance the power of sequential hypothesis testing. Given limited samples from the joint distribution of $(X,Y)$, and additional unlabeled samples from the marginal of $X$, we ask how unlabeled data can be used to hypothesize about the distribution of $Y$, and the conditional distribution of $Y\mid X$. We introduce an e-statistic and use it to construct a sequential test. Under standard distributional assumptions -- label shift or concept shift -- we establish that the test is anytime valid. Furthermore, we show that for binary data, the e-statistic has non-trivial power. Crucially, our approach retains these properties even when the underlying predictions are inaccurate. Through simulations and applications to large language models evaluation, we demonstrate power gains over baseline approaches, including prediction-powered inference. These gains persist even with relatively limited unlabeled data and when predictions have low accuracy due to weak correlation between $X$ and $Y$.
Valid Best-Model Identification for LLM Evaluation via Low-Rank Factorization
May 11, 2026Selecting the best large language model (LLM) for a fixed benchmark is often expensive, since exhaustive evaluation requires running every model on every example. Multi-armed bandit (MAB) algorithms can reduce the number of LLM calls by sequentially selecting the next model-example pair to evaluate, thereby avoiding wasted evaluations on clearly underperforming models. Further savings can be achieved by predicting model scores from the partially observed model-example score matrix using low-rank factorization. However, such predictions are not ground truth: they can be biased and may therefore lead to incorrect identification of the best model. In this work, we propose a principled framework that combines MAB with cheap predicted scores without compromising statistical validity. Specifically, we derive doubly robust estimators of each model's performance that use the low-rank predictions to reduce variance. This enables the construction of valid finite-sample confidence intervals in our setting, where models are selected adaptively and examples are sampled without replacement. Empirical results on real-world benchmarks show that our approach reduces the number of required evaluations, yielding meaningful savings in compute and cost while accurately identifying the best-performing model.
Speedy Model Selection (SMS) for Copula Models
Sep 26, 2013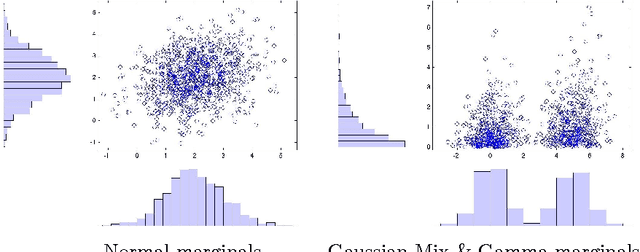
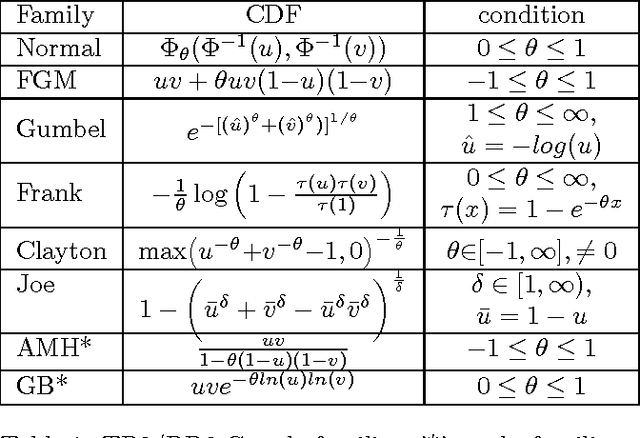
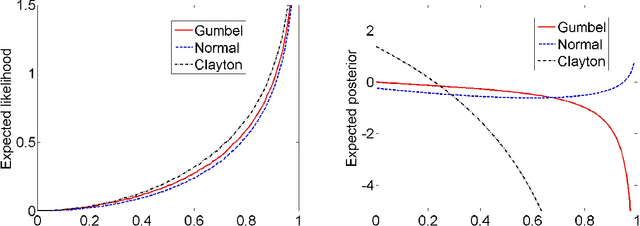
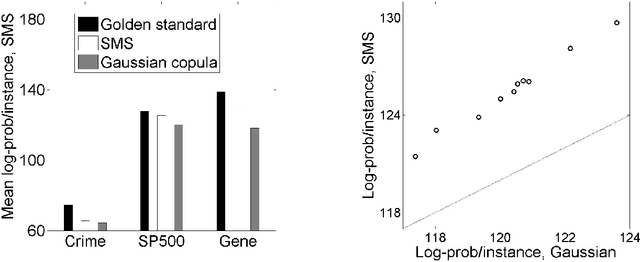
We tackle the challenge of efficiently learning the structure of expressive multivariate real-valued densities of copula graphical models. We start by theoretically substantiating the conjecture that for many copula families the magnitude of Spearman's rank correlation coefficient is monotone in the expected contribution of an edge in network, namely the negative copula entropy. We then build on this theory and suggest a novel Bayesian approach that makes use of a prior over values of Spearman's rho for learning copula-based models that involve a mix of copula families. We demonstrate the generalization effectiveness of our highly efficient approach on sizable and varied real-life datasets.