 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Optimal Path Tracking for Industrial Robots: A Dynamic Model-Free Reinforcement Learning Approach
Aug 03, 2019


In pursuit of the time-optimal path tracking (TOPT) trajectory of a robot manipulator along a preset path, a beforehand identified robot dynamic model is usually used to obtain the required optimal trajectory for perfect tracking. However, due to the inevitable model-plant mismatch, there may be a big error between the actually measured torques and the calculated torques by the dynamic model, which causes the obtained trajectory to be suboptimal or even be infeasible by exceeding given limits. This paper presents a TOPT-oriented SARSA algorithm (TOPTO-SARSA) and a two-step method for finding the time-optimal motion and ensuring the feasibility : Firstly, using TOPTO-SARSA to find a safe trajectory that satisfies the kinematic constraints through the interaction between reinforcement learning agent and kinematic model. Secondly, using TOPTO-SARSA to find the optimal trajectory through the interaction between the agent and the real world, and assure the actually measured torques satisfy the given limits at the last interaction. The effectiveness of the proposed algorithm has been verified through experiments on a 6-DOF robot manipulator.
Reinforcement Learning for Robotic Time-optimal Path Tracking Using Prior Knowledge
Jun 30, 2019

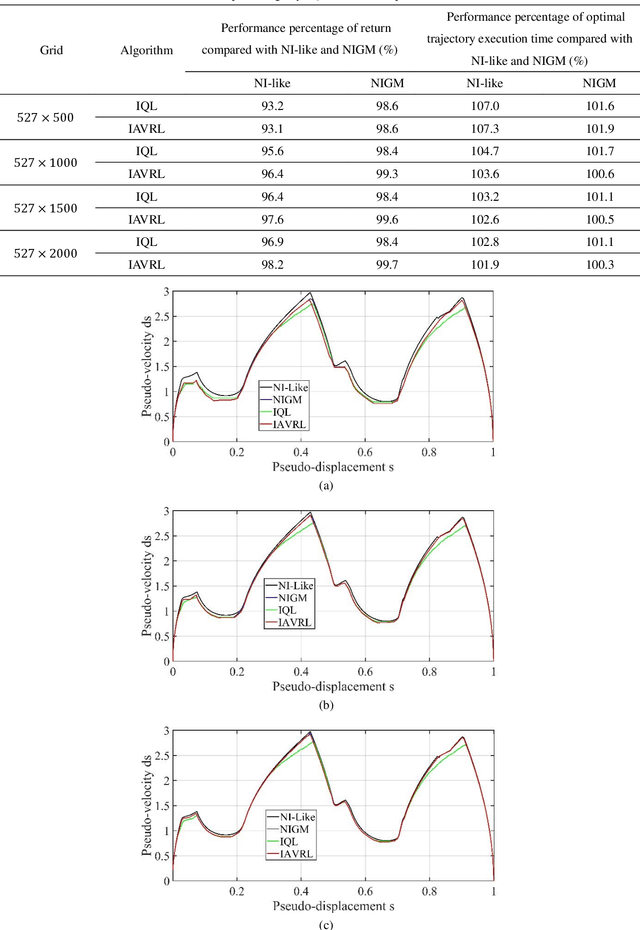
Time-optimal path tracking, as a significant tool for industrial robots, has attracted the attention of numerous researchers. In most time-optimal path tracking problems, the actuator torque constraints are assumed to be conservative, which ignores the motor characteristic; i.e., the actuator torque constraints are velocity-dependent, and the relationship between torque and velocity is piecewise linear. However, considering that the motor characteristics increase the solving difficulty, in this study, an improved Q-learning algorithm for robotic time-optimal path tracking using prior knowledge is proposed. After considering the limitations of the Q-learning algorithm, an improved action-value function is proposed to improve the convergence rate. The proposed algorithms use the idea of reward and penalty, rewarding the actions that satisfy constraint conditions and penalizing the actions that break constraint conditions, to finally obtain a time-optimal trajectory that satisfies the constraint conditions. The effectiveness of the algorithms is verified by experiments.