 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Context Compression: Mean-Pooling and Multi-Ratio Training
Oct 23, 2025



A common strategy to reduce the computational costs of using long contexts in retrieval-augmented generation (RAG) with large language models (LLMs) is soft context compression, where the input sequence is transformed into a shorter continuous representation. We develop a lightweight and simple mean-pooling approach that consistently outperforms the widely used compression-tokens architecture, and study training the same compressor to output multiple compression ratios. We conduct extensive experiments across in-domain and out-of-domain QA datasets, as well as across model families, scales, and compression ratios. Overall, our simple mean-pooling approach achieves the strongest performance, with a relatively small drop when training for multiple compression ratios. More broadly though, across architectures and training regimes the trade-offs are more nuanced, illustrating the complex landscape of compression methods.
Multi-Hop Paragraph Retrieval for Open-Domain Question Answering
Jun 15, 2019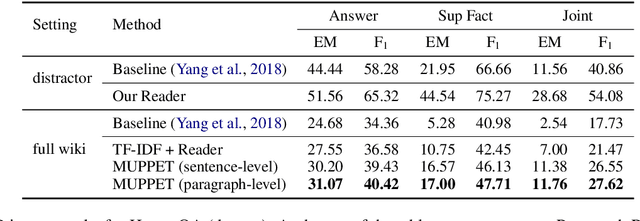
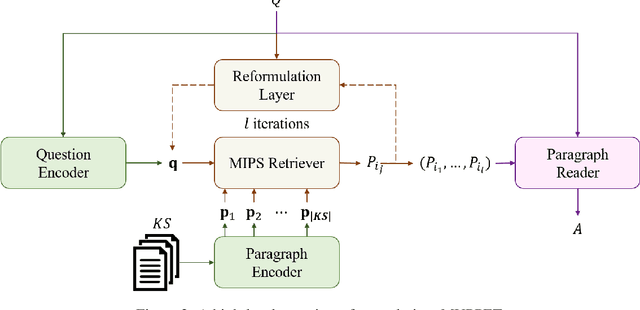
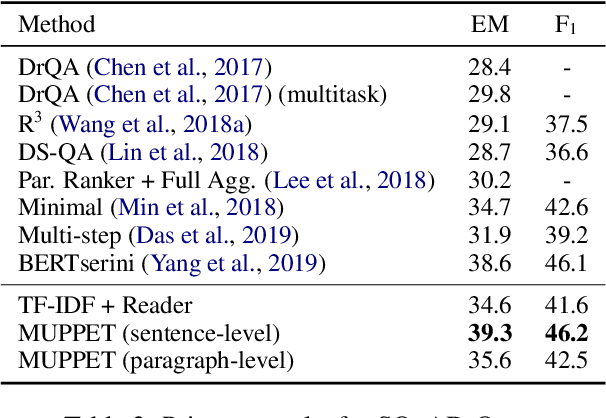
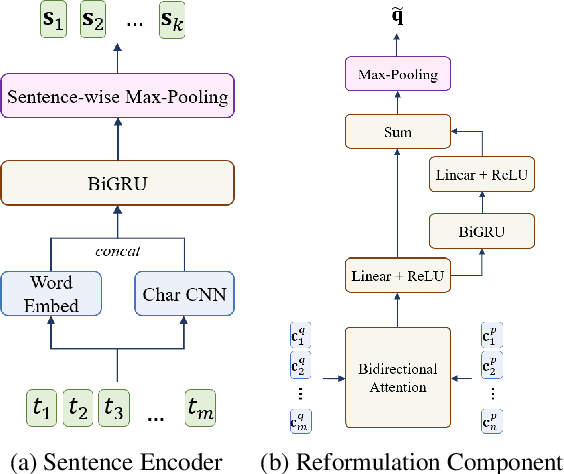
This paper is concerned with the task of multi-hop open-domain Question Answering (QA). This task is particularly challenging since it requires the simultaneous performance of textual reasoning and efficient searching. We present a method for retrieving multiple supporting paragraphs, nested amidst a large knowledge base, which contain the necessary evidence to answer a given question. Our method iteratively retrieves supporting paragraphs by forming a joint vector representation of both a question and a paragraph. The retrieval is performed by considering contextualized sentence-level representations of the paragraphs in the knowledge source. Our method achieves state-of-the-art performance over two well-known datasets, SQuAD-Open and HotpotQA, which serve as our single- and multi-hop open-domain QA benchmarks, respectively.