 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEGOFALLS: A visual-audio dataset and benchmark for fall detection using egocentric cameras
Sep 08, 2023Falls are significant and often fatal for vulnerable populations such as the elderly. Previous works have addressed the detection of falls by relying on data capture by a single sensor, images or accelerometers. In this work, we rely on multimodal descriptors extracted from videos captured by egocentric cameras. Our proposed method includes a late decision fusion layer that builds on top of the extracted descriptors. Furthermore, we collect a new dataset on which we assess our proposed approach. We believe this is the first public dataset of its kind. The dataset comprises 10,948 video samples by 14 subjects. We conducted ablation experiments to assess the performance of individual feature extractors, fusion of visual information, and fusion of both visual and audio information. Moreover, we experimented with internal and external cross-validation. Our results demonstrate that the fusion of audio and visual information through late decision fusion improves detection performance, making it a promising tool for fall prevention and mitigation.
VAE-based Domain Adaptation for Speaker Verification
Aug 27, 2019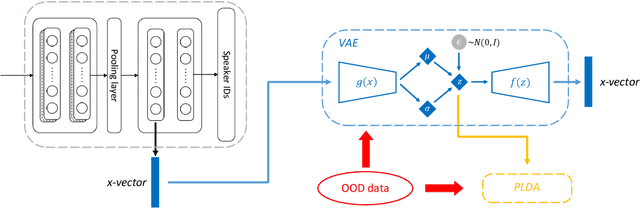



Deep speaker embedding has achieved satisfactory performance in speaker verification. By enforcing the neural model to discriminate the speakers in the training set, deep speaker embedding (called `x-vectors`) can be derived from the hidden layers. Despite its good performance, the present embedding model is highly domain sensitive, which means that it often works well in domains whose acoustic condition matches that of the training data (in-domain), but degrades in mismatched domains (out-of-domain). In this paper, we present a domain adaptation approach based on Variational Auto-Encoder (VAE). This model transforms x-vectors to a regularized latent space; within this latent space, a small amount of data from the target domain is sufficient to accomplish the adaptation. Our experiments demonstrated that by this VAE-adaptation approach, speaker embeddings can be easily transformed to the target domain, leading to noticeable performance improvement.