 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Prompts Interact: Assessing Prompt Arithmetic for Deconfounding under Distribution Shift
May 04, 2026In classification tasks, models may rely on confounding variables to achieve strong in-distribution performance, capturing spurious features that fail under distribution shift. This shortcut behavior leads to substantial degradation in out-of-distribution settings. Task arithmetic offers a potential solution by removing unwanted signals via subtraction of secondary model updates, but it typically requires full fine-tuning, which is computationally expensive. Prompt tuning provides a parameter-efficient alternative by adapting models through a small set of trainable virtual tokens. Task arithmetic on the resulting prompts presents an appealing alternative to operations on entire models, but the extent to which this approach can limit reliance on spurious features remains to be established. In this work, we study whether composing soft prompts through task arithmetic improves robustness to confounding shifts. We propose Hybrid Prompt Arithmetic (HyPA), which combines task prompts with linearized confounder prompts to counteract spurious correlations. Across multiple benchmarks, HyPA consistently improves the robustness-performance trade-off relative to prompt-arithmetic baselines under distribution shift. We further analyze how HyPA affects hidden representations and find evidence consistent with it mitigating confounding either by reducing the influence of confounder signals on predictions or by suppressing them in the representation. These results establish HyPA as a parameter-efficient and promising approach for improving robustness under confounding shifts in the evaluated setting.
Mitigating Confounding in Speech-Based Dementia Detection through Weight Masking
Jun 05, 2025Deep transformer models have been used to detect linguistic anomalies in patient transcripts for early Alzheimer's disease (AD) screening. While pre-trained neural language models (LMs) fine-tuned on AD transcripts perform well, little research has explored the effects of the gender of the speakers represented by these transcripts. This work addresses gender confounding in dementia detection and proposes two methods: the $\textit{Extended Confounding Filter}$ and the $\textit{Dual Filter}$, which isolate and ablate weights associated with gender. We evaluate these methods on dementia datasets with first-person narratives from patients with cognitive impairment and healthy controls. Our results show transformer models tend to overfit to training data distributions. Disrupting gender-related weights results in a deconfounded dementia classifier, with the trade-off of slightly reduced dementia detection performance.
Enhancing Robustness of Foundation Model Representations under Provenance-related Distribution Shifts
Dec 09, 2023
Foundation models are a current focus of attention in both industry and academia. While they have shown their capabilities in a variety of tasks, in-depth research is required to determine their robustness to distribution shift when used as a basis for supervised machine learning. This is especially important in the context of clinical data, with particular limitations related to data accessibility, lack of pretraining materials, and limited availability of high-quality annotations. In this work, we examine the stability of models based on representations from foundation models under distribution shift. We focus on confounding by provenance, a form of distribution shift that emerges in the context of multi-institutional datasets when there are differences in source-specific language use and class distributions. Using a sampling strategy that synthetically induces varying degrees of distribution shift, we evaluate the extent to which representations from foundation models result in predictions that are inherently robust to confounding by provenance. Additionally, we examine the effectiveness of a straightforward confounding adjustment method inspired by Pearl's conception of backdoor adjustment. Results indicate that while foundation models do show some out-of-the-box robustness to confounding-by-provenance related distribution shifts, this can be considerably improved through adjustment. These findings suggest a need for deliberate adjustment of predictive models using representations from foundation models in the context of source-specific distributional differences.
Backdoor Adjustment of Confounding by Provenance for Robust Text Classification of Multi-institutional Clinical Notes
Oct 03, 2023



Natural Language Processing (NLP) methods have been broadly applied to clinical tasks. Machine learning and deep learning approaches have been used to improve the performance of clinical NLP. However, these approaches require sufficiently large datasets for training, and trained models have been shown to transfer poorly across sites. These issues have led to the promotion of data collection and integration across different institutions for accurate and portable models. However, this can introduce a form of bias called confounding by provenance. When source-specific data distributions differ at deployment, this may harm model performance. To address this issue, we evaluate the utility of backdoor adjustment for text classification in a multi-site dataset of clinical notes annotated for mentions of substance abuse. Using an evaluation framework devised to measure robustness to distributional shifts, we assess the utility of backdoor adjustment. Our results indicate that backdoor adjustment can effectively mitigate for confounding shift.
Retrofitting Vector Representations of Adverse Event Reporting Data to Structured Knowledge to Improve Pharmacovigilance Signal Detection
Aug 07, 2020
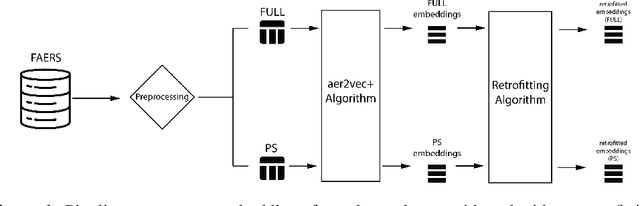
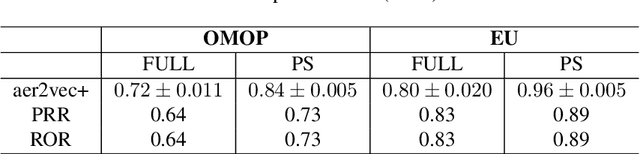
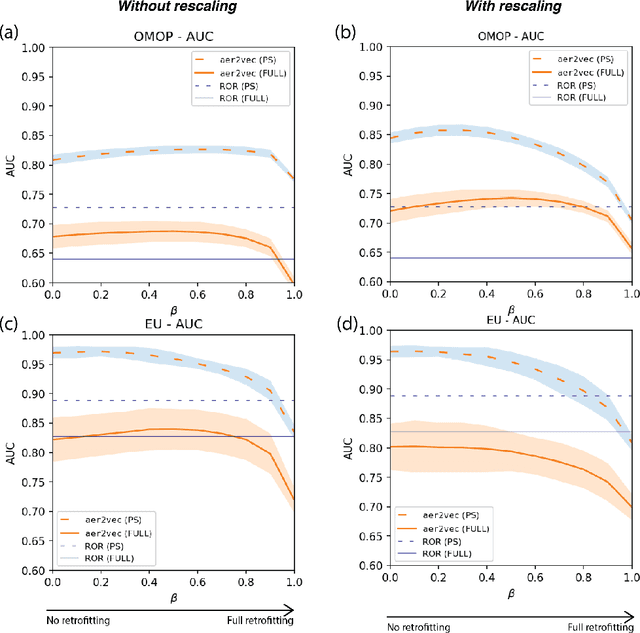
Adverse drug events (ADE) are prevalent and costly. Clinical trials are constrained in their ability to identify potential ADEs, motivating the development of spontaneous reporting systems for post-market surveillance. Statistical methods provide a convenient way to detect signals from these reports but have limitations in leveraging relationships between drugs and ADEs given their discrete count-based nature. A previously proposed method, aer2vec, generates distributed vector representations of ADE report entities that capture patterns of similarity but cannot utilize lexical knowledge. We address this limitation by retrofitting aer2vec drug embeddings to knowledge from RxNorm and developing a novel retrofitting variant using vector rescaling to preserve magnitude. When evaluated in the context of a pharmacovigilance signal detection task, aer2vec with retrofitting consistently outperforms disproportionality metrics when trained on minimally preprocessed data. Retrofitting with rescaling results in further improvements in the larger and more challenging of two pharmacovigilance reference sets used for evaluation.