 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocused Discriminative Training For Streaming CTC-Trained Automatic Speech Recognition Models
Aug 23, 2024This paper introduces a novel training framework called Focused Discriminative Training (FDT) to further improve streaming word-piece end-to-end (E2E) automatic speech recognition (ASR) models trained using either CTC or an interpolation of CTC and attention-based encoder-decoder (AED) loss. The proposed approach presents a novel framework to identify and improve a model's recognition on challenging segments of an audio. Notably, this training framework is independent of hidden Markov models (HMMs) and lattices, eliminating the need for substantial decision-making regarding HMM topology, lexicon, and graph generation, as typically required in standard discriminative training approaches. Compared to additional fine-tuning with MMI or MWER loss on the encoder, FDT is shown to be more effective in achieving greater reductions in Word Error Rate (WER) on streaming models trained on LibriSpeech. Additionally, this method is shown to be effective in further improving a converged word-piece streaming E2E model trained on 600k hours of assistant and dictation dataset.
Enhancing CTC-based speech recognition with diverse modeling units
Jun 05, 2024



In recent years, the evolution of end-to-end (E2E) automatic speech recognition (ASR) models has been remarkable, largely due to advances in deep learning architectures like transformer. On top of E2E systems, researchers have achieved substantial accuracy improvement by rescoring E2E model's N-best hypotheses with a phoneme-based model. This raises an interesting question about where the improvements come from other than the system combination effect. We examine the underlying mechanisms driving these gains and propose an efficient joint training approach, where E2E models are trained jointly with diverse modeling units. This methodology does not only align the strengths of both phoneme and grapheme-based models but also reveals that using these diverse modeling units in a synergistic way can significantly enhance model accuracy. Our findings offer new insights into the optimal integration of heterogeneous modeling units in the development of more robust and accurate ASR systems.
A Treatise On FST Lattice Based MMI Training
Oct 17, 2022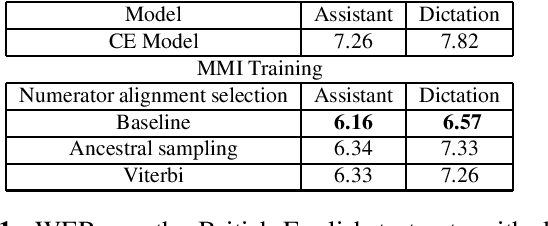
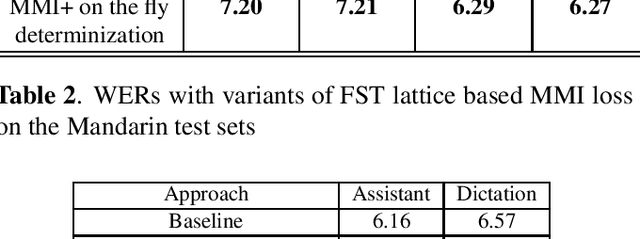
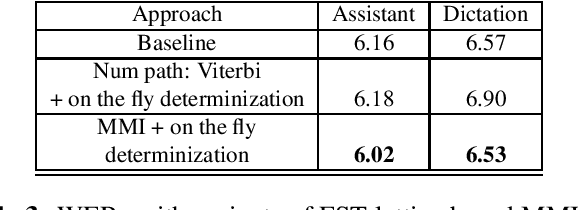
Maximum mutual information (MMI) has become one of the two de facto methods for sequence-level training of speech recognition acoustic models. This paper aims to isolate, identify and bring forward the implicit modelling decisions induced by the design implementation of standard finite state transducer (FST) lattice based MMI training framework. The paper particularly investigates the necessity to maintain a preselected numerator alignment and raises the importance of determinizing FST denominator lattices on the fly. The efficacy of employing on the fly FST lattice determinization is mathematically shown to guarantee discrimination at the hypothesis level and is empirically shown through training deep CNN models on a 18K hours Mandarin dataset and on a 2.8K hours English dataset. On assistant and dictation tasks, the approach achieves between 2.3-4.6% relative WER reduction (WERR) over the standard FST lattice based approach.
AISHELL-2: Transforming Mandarin ASR Research Into Industrial Scale
Sep 13, 2018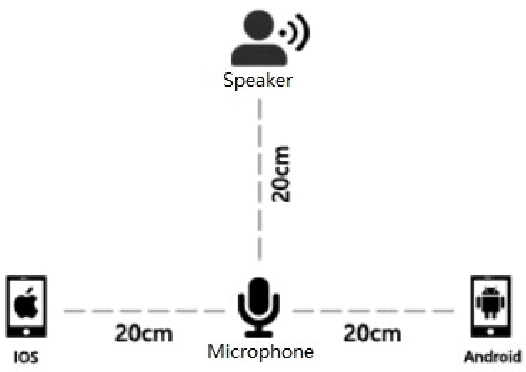


AISHELL-1 is by far the largest open-source speech corpus available for Mandarin speech recognition research. It was released with a baseline system containing solid training and testing pipelines for Mandarin ASR. In AISHELL-2, 1000 hours of clean read-speech data from iOS is published, which is free for academic usage. On top of AISHELL-2 corpus, an improved recipe is developed and released, containing key components for industrial applications, such as Chinese word segmentation, flexible vocabulary expension and phone set transformation etc. Pipelines support various state-of-the-art techniques, such as time-delayed neural networks and Lattic-Free MMI objective funciton. In addition, we also release dev and test data from other channels(Android and Mic). For research community, we hope that AISHELL-2 corpus can be a solid resource for topics like transfer learning and robust ASR. For industry, we hope AISHELL-2 recipe can be a helpful reference for building meaningful industrial systems and products.
AISHELL-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline
Sep 16, 2017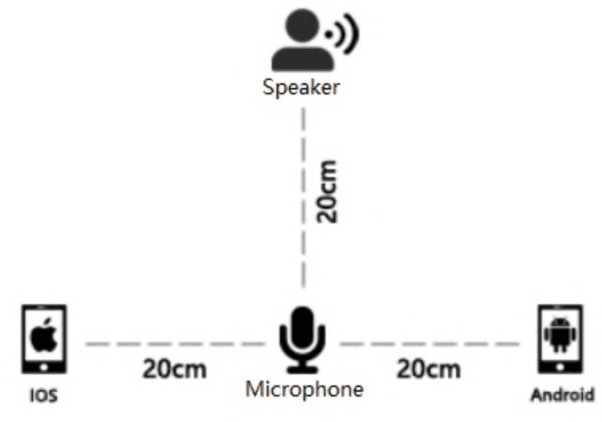
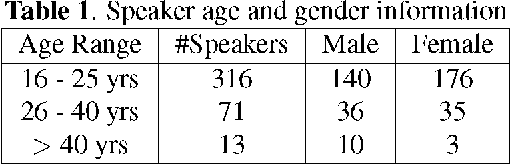

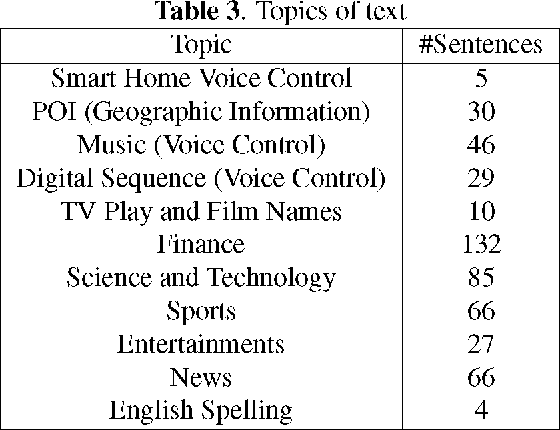
An open-source Mandarin speech corpus called AISHELL-1 is released. It is by far the largest corpus which is suitable for conducting the speech recognition research and building speech recognition systems for Mandarin. The recording procedure, including audio capturing devices and environments are presented in details. The preparation of the related resources, including transcriptions and lexicon are described. The corpus is released with a Kaldi recipe. Experimental results implies that the quality of audio recordings and transcriptions are promising.