 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Recovery with Implicitly Low-Rank Data
Nov 09, 2018
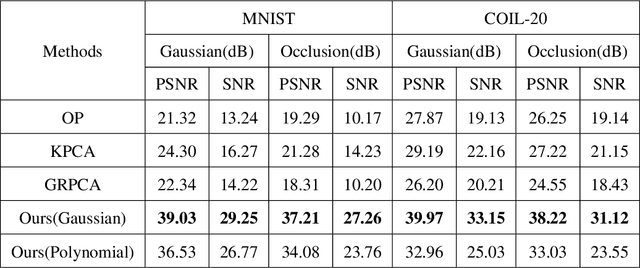
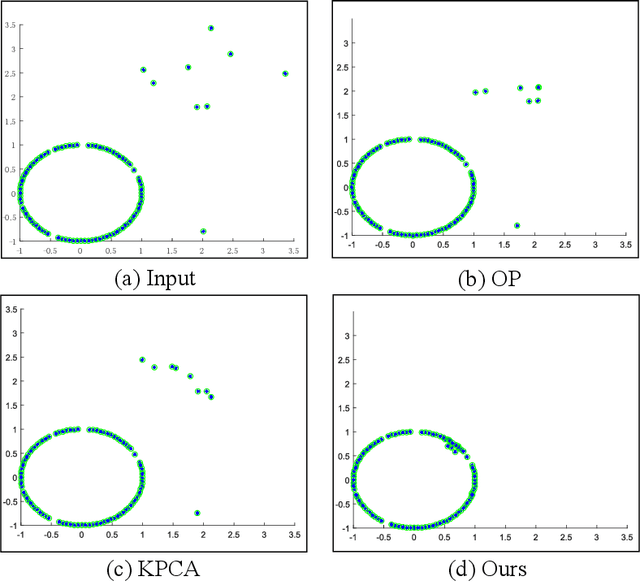

In this paper, we study the problem of matrix recovery, which aims to restore a target matrix of authentic samples from grossly corrupted observations. Most of the existing methods, such as the well-known Robust Principal Component Analysis (RPCA), assume that the target matrix we wish to recover is low-rank. However, the underlying data structure is often non-linear in practice, therefore the low-rankness assumption could be violated. To tackle this issue, we propose a novel method for matrix recovery in this paper, which could well handle the case where the target matrix is low-rank in an implicit feature space but high-rank or even full-rank in its original form. Namely, our method pursues the low-rank structure of the target matrix in an implicit feature space. By making use of the specifics of an accelerated proximal gradient based optimization algorithm, the proposed method could recover the target matrix with non-linear structures from its corrupted version. Comprehensive experiments on both synthetic and real datasets demonstrate the superiority of our method.