 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegGuard: AI-Powered Retrieval-Enhanced Assistant for Pharmaceutical Regulatory Compliance
Jan 25, 2026The increasing frequency and complexity of regulatory updates present a significant burden for multinational pharmaceutical companies. Compliance teams must interpret evolving rules across jurisdictions, formats, and agencies, often manually, at high cost and risk of error. We introduce RegGuard, an industrial-scale AI assistant designed to automate the interpretation of heterogeneous regulatory texts and align them with internal corporate policies. The system ingests heterogeneous document sources through a secure pipeline and enhances retrieval and generation quality with two novel components: HiSACC (Hierarchical Semantic Aggregation for Contextual Chunking) semantically segments long documents into coherent units while maintaining consistency across non-contiguous sections. ReLACE (Regulatory Listwise Adaptive Cross-Encoder for Reranking), a domain-adapted cross-encoder built on an open-source model, jointly models user queries and retrieved candidates to improve ranking relevance. Evaluations in enterprise settings demonstrate that RegGuard improves answer quality specifically in terms of relevance, groundedness, and contextual focus, while significantly mitigating hallucination risk. The system architecture is built for auditability and traceability, featuring provenance tracking, access control, and incremental indexing, making it highly responsive to evolving document sources and relevant for any domain with stringent compliance demands.
Real-Time Synchronized Interaction Framework for Emotion-Aware Humanoid Robots
Jan 24, 2026As humanoid robots increasingly introduced into social scene, achieving emotionally synchronized multimodal interaction remains a significant challenges. To facilitate the further adoption and integration of humanoid robots into service roles, we present a real-time framework for NAO robots that synchronizes speech prosody with full-body gestures through three key innovations: (1) A dual-channel emotion engine where large language model (LLM) simultaneously generates context-aware text responses and biomechanically feasible motion descriptors, constrained by a structured joint movement library; (2) Duration-aware dynamic time warping for precise temporal alignment of speech output and kinematic motion keyframes; (3) Closed-loop feasibility verification ensuring gestures adhere to NAO's physical joint limits through real-time adaptation. Evaluations show 21% higher emotional alignment compared to rule-based systems, achieved by coordinating vocal pitch (arousal-driven) with upper-limb kinematics while maintaining lower-body stability. By enabling seamless sensorimotor coordination, this framework advances the deployment of context-aware social robots in dynamic applications such as personalized healthcare, interactive education, and responsive customer service platforms.
Generalizing to New Tasks via One-Shot Compositional Subgoals
May 16, 2022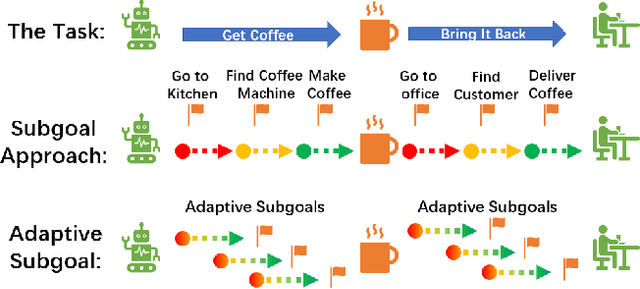

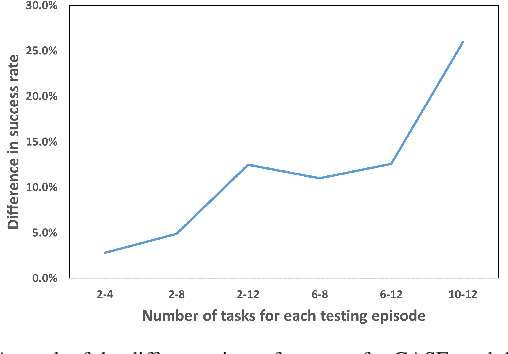
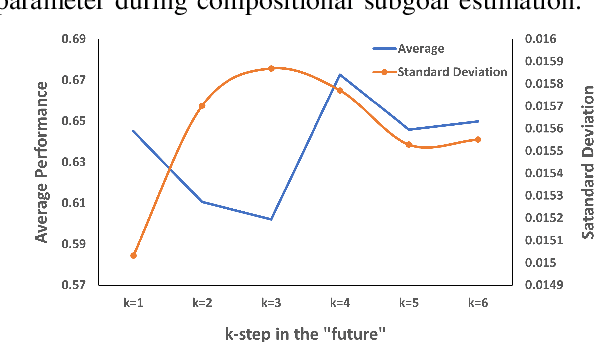
The ability to generalize to previously unseen tasks with little to no supervision is a key challenge in modern machine learning research. It is also a cornerstone of a future "General AI". Any artificially intelligent agent deployed in a real world application, must adapt on the fly to unknown environments. Researchers often rely on reinforcement and imitation learning to provide online adaptation to new tasks, through trial and error learning. However, this can be challenging for complex tasks which require many timesteps or large numbers of subtasks to complete. These "long horizon" tasks suffer from sample inefficiency and can require extremely long training times before the agent can learn to perform the necessary longterm planning. In this work, we introduce CASE which attempts to address these issues by training an Imitation Learning agent using adaptive "near future" subgoals. These subgoals are recalculated at each step using compositional arithmetic in a learned latent representation space. In addition to improving learning efficiency for standard long-term tasks, this approach also makes it possible to perform one-shot generalization to previously unseen tasks, given only a single reference trajectory for the task in a different environment. Our experiments show that the proposed approach consistently outperforms the previous state-of-the-art compositional Imitation Learning approach by 30%.
Robot in a China Shop: Using Reinforcement Learning for Location-Specific Navigation Behaviour
Jun 02, 2021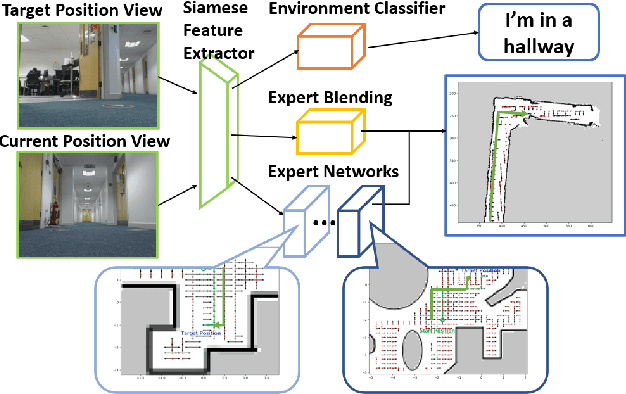
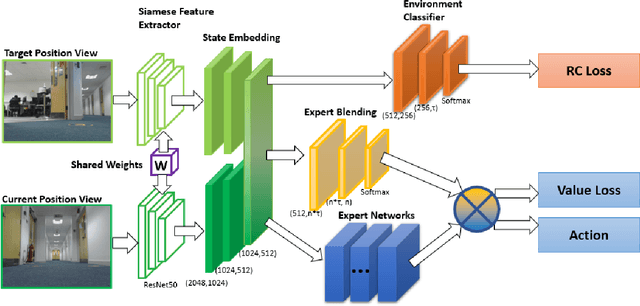
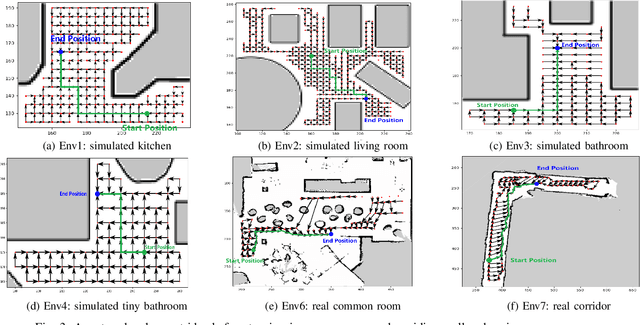
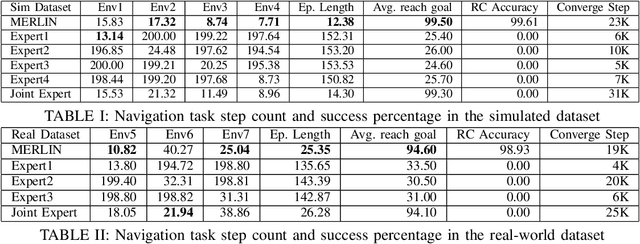
Robots need to be able to work in multiple different environments. Even when performing similar tasks, different behaviour should be deployed to best fit the current environment. In this paper, We propose a new approach to navigation, where it is treated as a multi-task learning problem. This enables the robot to learn to behave differently in visual navigation tasks for different environments while also learning shared expertise across environments. We evaluated our approach in both simulated environments as well as real-world data. Our method allows our system to converge with a 26% reduction in training time, while also increasing accuracy.