 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRET: Feature Redundancy Elimination for Test Time Adaptation
May 15, 2025Test-Time Adaptation (TTA) aims to enhance the generalization of deep learning models when faced with test data that exhibits distribution shifts from the training data. In this context, only a pre-trained model and unlabeled test data are available, making it particularly relevant for privacy-sensitive applications. In practice, we observe that feature redundancy in embeddings tends to increase as domain shifts intensify in TTA. However, existing TTA methods often overlook this redundancy, which can hinder the model's adaptability to new data. To address this issue, we introduce Feature Redundancy Elimination for Test-time Adaptation (FRET), a novel perspective for TTA. A straightforward approach (S-FRET) is to directly minimize the feature redundancy score as an optimization objective to improve adaptation. Despite its simplicity and effectiveness, S-FRET struggles with label shifts, limiting its robustness in real-world scenarios. To mitigate this limitation, we further propose Graph-based FRET (G-FRET), which integrates a Graph Convolutional Network (GCN) with contrastive learning. This design not only reduces feature redundancy but also enhances feature discriminability in both the representation and prediction layers. Extensive experiments across multiple model architectures, tasks, and datasets demonstrate the effectiveness of S-FRET and show that G-FRET achieves state-of-the-art performance. Further analysis reveals that G-FRET enables the model to extract non-redundant and highly discriminative features during inference, thereby facilitating more robust test-time adaptation.
Test-time Correlation Alignment
May 01, 2025Deep neural networks often experience performance drops due to distribution shifts between training and test data. Although domain adaptation offers a solution, privacy concerns restrict access to training data in many real-world scenarios. This restriction has spurred interest in Test-Time Adaptation (TTA), which adapts models using only unlabeled test data. However, current TTA methods still face practical challenges: (1) a primary focus on instance-wise alignment, overlooking CORrelation ALignment (CORAL) due to missing source correlations; (2) complex backpropagation operations for model updating, resulting in overhead computation and (3) domain forgetting. To address these challenges, we provide a theoretical analysis to investigate the feasibility of Test-time Correlation Alignment (TCA), demonstrating that correlation alignment between high-certainty instances and test instances can enhance test performances with a theoretical guarantee. Based on this, we propose two simple yet effective algorithms: LinearTCA and LinearTCA+. LinearTCA applies a simple linear transformation to achieve both instance and correlation alignment without additional model updates, while LinearTCA+ serves as a plug-and-play module that can easily boost existing TTA methods. Extensive experiments validate our theoretical insights and show that TCA methods significantly outperforms baselines across various tasks, benchmarks and backbones. Notably, LinearTCA improves adaptation accuracy by 5.88% on OfficeHome dataset, while using only 4% maximum GPU memory usage and 0.6% computation time compared to the best baseline TTA method.
A New Manifold Distance Measure for Visual Object Categorization
May 12, 2016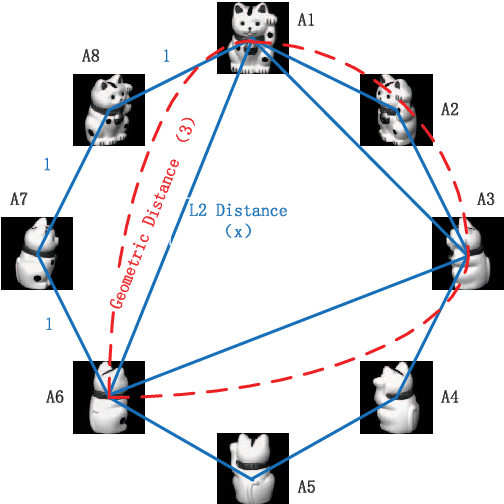
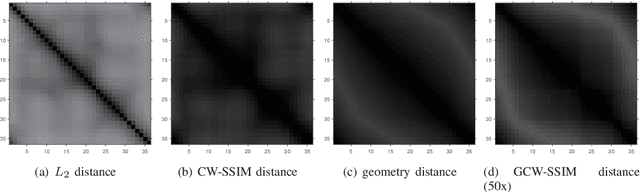
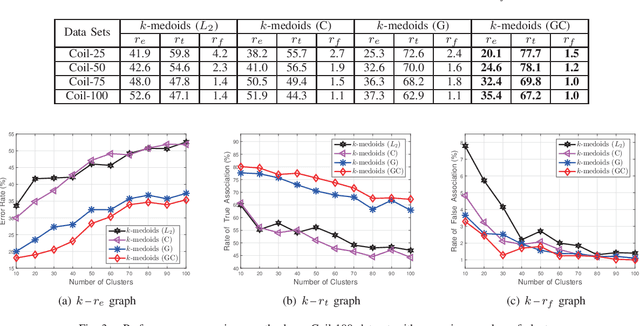
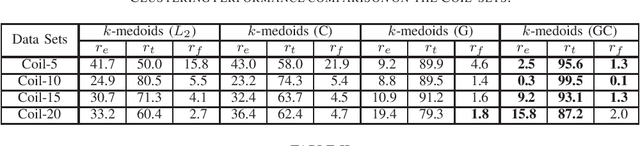
Manifold distances are very effective tools for visual object recognition. However, most of the traditional manifold distances between images are based on the pixel-level comparison and thus easily affected by image rotations and translations. In this paper, we propose a new manifold distance to model the dissimilarities between visual objects based on the Complex Wavelet Structural Similarity (CW-SSIM) index. The proposed distance is more robust to rotations and translations of images than the traditional manifold distance and the CW-SSIM index based distance. In addition, the proposed distance is combined with the $k$-medoids clustering method to derive a new clustering method for visual object categorization. Experiments on Coil-20, Coil-100 and Olivetti Face Databases show that the proposed distance measure is better for visual object categorization than both the traditional manifold distances and the CW-SSIM index based distances.