 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-Fast, Low-Storage, Highly Effective Coarse-grained Selection in Retrieval-based Chatbot by Using Deep Semantic Hashing
Dec 18, 2020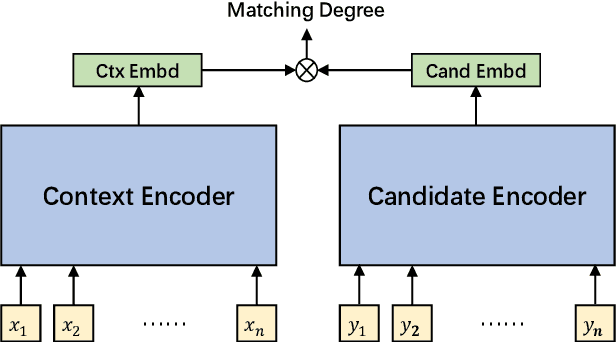
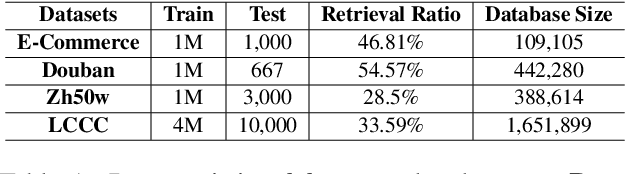
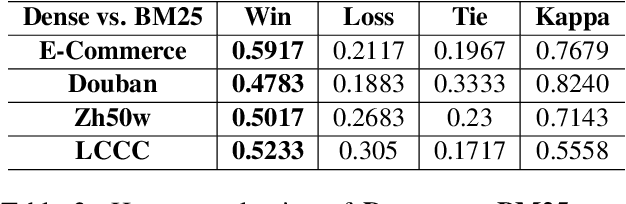
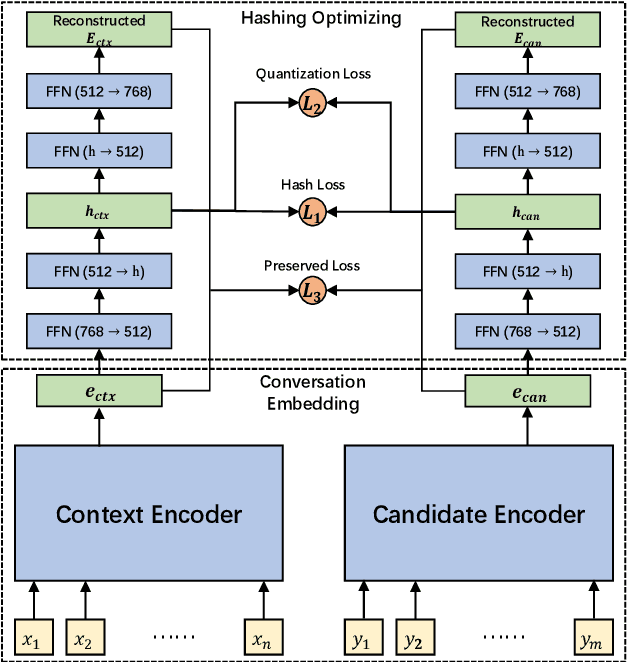
We study the coarse-grained selection module in retrieval-based chatbot. Coarse-grained selection is a basic module in a retrieval-based chatbot, which constructs a rough candidate set from the whole database to speed up the interaction with customers. So far, there are two kinds of approaches for coarse-grained selection module: (1) sparse representation; (2) dense representation. To the best of our knowledge, there is no systematic comparison between these two approaches in retrieval-based chatbots, and which kind of method is better in real scenarios is still an open question. In this paper, we first systematically compare these two methods from four aspects: (1) effectiveness; (2) index stoarge; (3) search time cost; (4) human evaluation. Extensive experiment results demonstrate that dense representation method significantly outperforms the sparse representation, but costs more time and storage occupation. In order to overcome these fatal weaknesses of dense representation method, we propose an ultra-fast, low-storage, and highly effective Deep Semantic Hashing Coarse-grained selection method, called DSHC model. Specifically, in our proposed DSHC model, a hashing optimizing module that consists of two autoencoder models is stacked on a trained dense representation model, and three loss functions are designed to optimize it. The hash codes provided by hashing optimizing module effectively preserve the rich semantic and similarity information in dense vectors. Extensive experiment results prove that, our proposed DSHC model can achieve much faster speed and lower storage than sparse representation, with limited performance loss compared with dense representation. Besides, our source codes have been publicly released for future research.
PONE: A Novel Automatic Evaluation Metric for Open-Domain Generative Dialogue Systems
Apr 06, 2020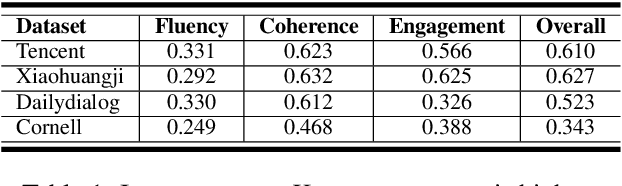
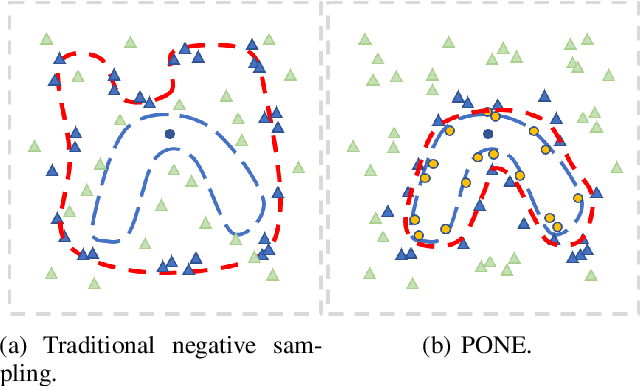
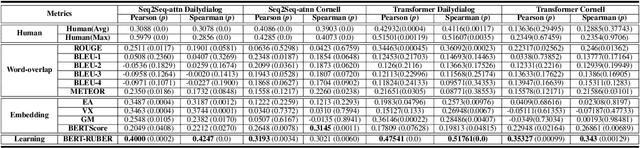
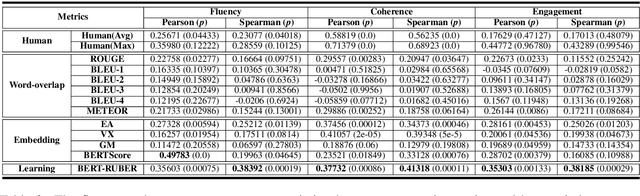
Open-domain generative dialogue systems have attracted considerable attention over the past few years. Currently, how to automatically evaluate them, is still a big challenge problem. As far as we know, there are three kinds of automatic methods to evaluate the open-domain generative dialogue systems: (1) Word-overlap-based metrics; (2) Embedding-based metrics; (3) Learning-based metrics. Due to the lack of systematic comparison, it is not clear which kind of metrics are more effective. In this paper, we will first measure systematically all kinds of automatic evaluation metrics over the same experimental setting to check which kind is best. Through extensive experiments, the learning-based metrics are demonstrated that they are the most effective evaluation metrics for open-domain generative dialogue systems. Moreover, we observe that nearly all learning-based metrics depend on the negative sampling mechanism, which obtains an extremely imbalanced and low-quality dataset to train a score model. In order to address this issue, we propose a novel and feasible learning-based metric that can significantly improve the correlation with human judgments by using augmented POsitive samples and valuable NEgative samples, called PONE. Extensive experiments demonstrate that our proposed evaluation method significantly outperforms the state-of-the-art learning-based evaluation methods, with an average correlation improvement of 13.18%. In addition, we have publicly released the codes of our proposed method and state-of-the-art baselines.