 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoReL: Multi-omics Relational Learning
Mar 15, 2022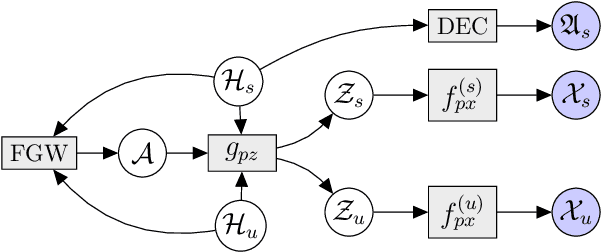

Multi-omics data analysis has the potential to discover hidden molecular interactions, revealing potential regulatory and/or signal transduction pathways for cellular processes of interest when studying life and disease systems. One of critical challenges when dealing with real-world multi-omics data is that they may manifest heterogeneous structures and data quality as often existing data may be collected from different subjects under different conditions for each type of omics data. We propose a novel deep Bayesian generative model to efficiently infer a multi-partite graph encoding molecular interactions across such heterogeneous views, using a fused Gromov-Wasserstein (FGW) regularization between latent representations of corresponding views for integrative analysis. With such an optimal transport regularization in the deep Bayesian generative model, it not only allows incorporating view-specific side information, either with graph-structured or unstructured data in different views, but also increases the model flexibility with the distribution-based regularization. This allows efficient alignment of heterogeneous latent variable distributions to derive reliable interaction predictions compared to the existing point-based graph embedding methods. Our experiments on several real-world datasets demonstrate enhanced performance of MoReL in inferring meaningful interactions compared to existing baselines.
COVID-Datathon: Biomarker identification for COVID-19 severity based on BALF scRNA-seq data
Oct 11, 2021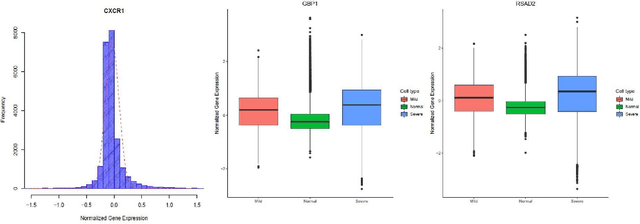
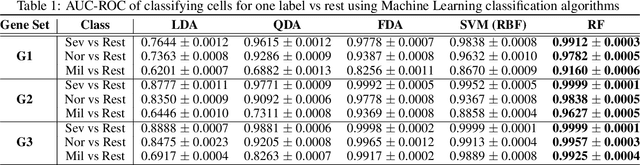
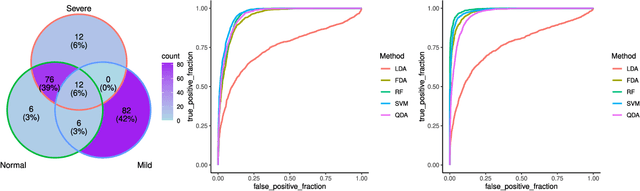
The severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) emergence began in late 2019 and has since spread rapidly worldwide. The characteristics of respiratory immune response to this emerging virus is not clear. Recently, Single-cell RNA sequencing (scRNA-seq) transcriptome profiling of Bronchoalveolar lavage fluid (BALF) cells has been done to elucidate the potential mechanisms underlying in COVID-19. With the aim of better utilizing this atlas of BALF cells in response to the virus, here we propose a bioinformatics pipeline to identify candidate biomarkers of COVID-19 severity, which may help characterize BALF cells to have better mechanistic understanding of SARS-CoV-2 infection. The proposed pipeline is implemented in R and is available at https://github.com/namini94/scBALF_Hackathon.
Adaptive Group Testing with Mismatched Models
Oct 05, 2021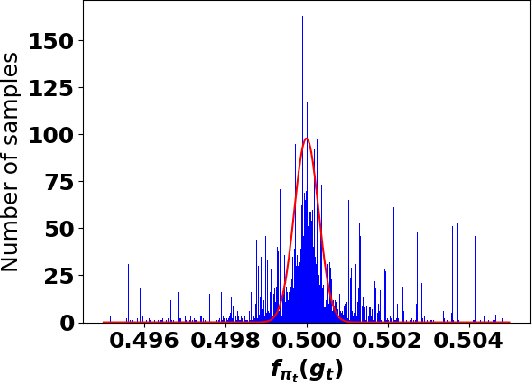
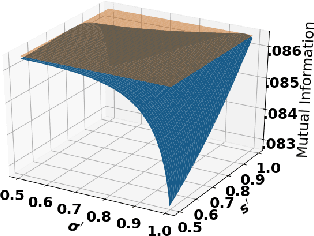
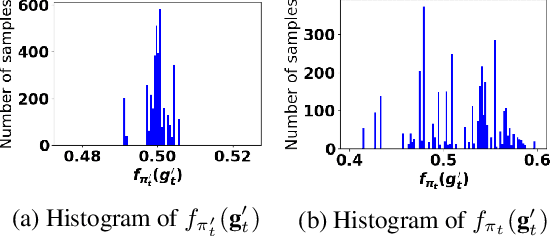
Accurate detection of infected individuals is one of the critical steps in stopping any pandemic. When the underlying infection rate of the disease is low, testing people in groups, instead of testing each individual in the population, can be more efficient. In this work, we consider noisy adaptive group testing design with specific test sensitivity and specificity that select the optimal group given previous test results based on pre-selected utility function. As in prior studies on group testing, we model this problem as a sequential Bayesian Optimal Experimental Design (BOED) to adaptively design the groups for each test. We analyze the required number of group tests when using the updated posterior on the infection status and the corresponding Mutual Information (MI) as our utility function for selecting new groups. More importantly, we study how the potential bias on the ground-truth noise of group tests may affect the group testing sample complexity.
Optimal Decision Making in High-Throughput Virtual Screening Pipelines
Sep 23, 2021
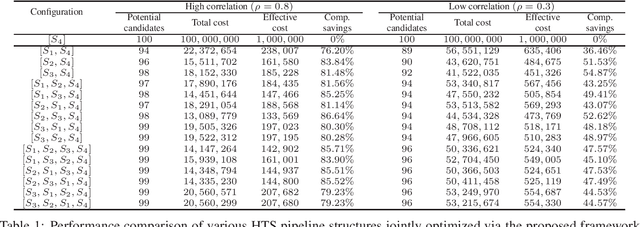
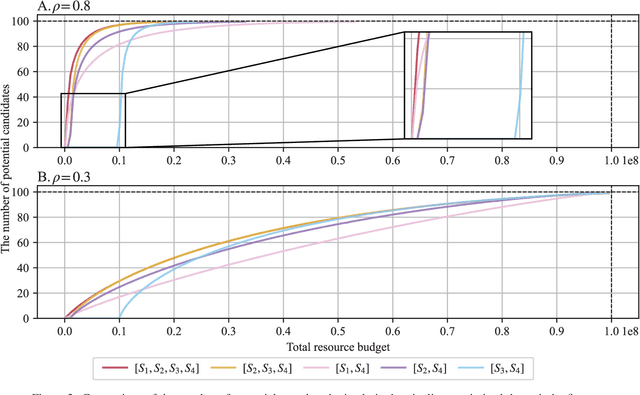

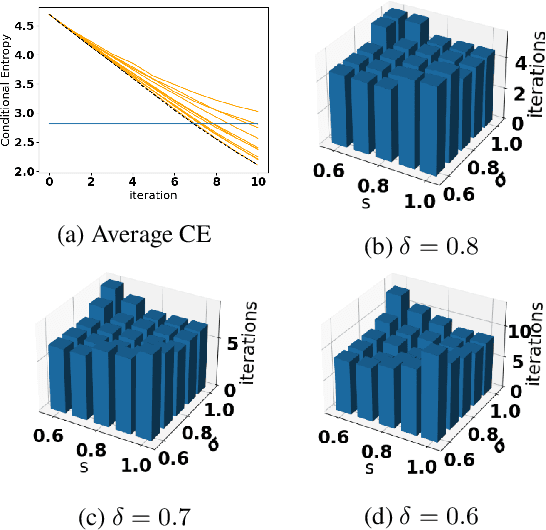
Effective selection of the potential candidates that meet certain conditions in a tremendously large search space has been one of the major concerns in many real-world applications. In addition to the nearly infinitely large search space, rigorous evaluation of a sample based on the reliable experimental or computational platform is often prohibitively expensive, making the screening problem more challenging. In such a case, constructing a high-throughput screening (HTS) pipeline that pre-sifts the samples expected to be potential candidates through the efficient earlier stages, results in a significant amount of savings in resources. However, to the best of our knowledge, despite many successful applications, no one has studied optimal pipeline design or optimal pipeline operations. In this study, we propose two optimization frameworks, applying to most (if not all) screening campaigns involving experimental or/and computational evaluations, for optimally determining the screening thresholds of an HTS pipeline. We validate the proposed frameworks on both analytic and practical scenarios. In particular, we consider the optimal computational campaign for the long non-coding RNA (lncRNA) classification as a practical example. To accomplish this, we built the high-throughput virtual screening (HTVS) pipeline for classifying the lncRNA. The simulation results demonstrate that the proposed frameworks significantly reduce the effective selection cost per potential candidate and make the HTS pipelines less sensitive to their structural variations. In addition to the validation, we provide insights on constructing a better HTS pipeline based on the simulation results.
Robust Importance Sampling for Error Estimation in the Context of Optimal Bayesian Transfer Learning
Sep 05, 2021
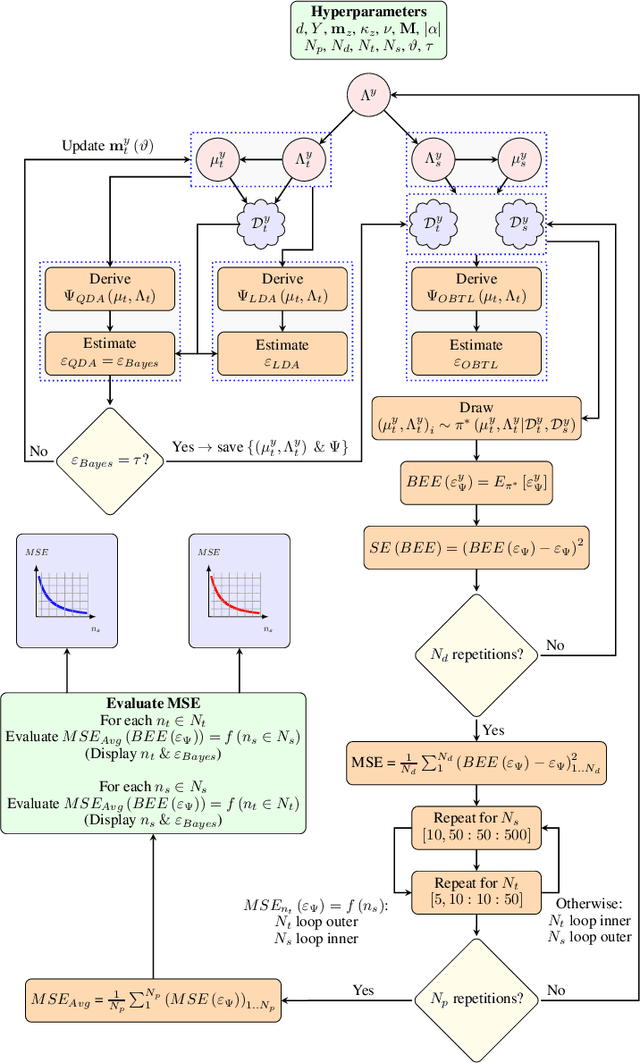
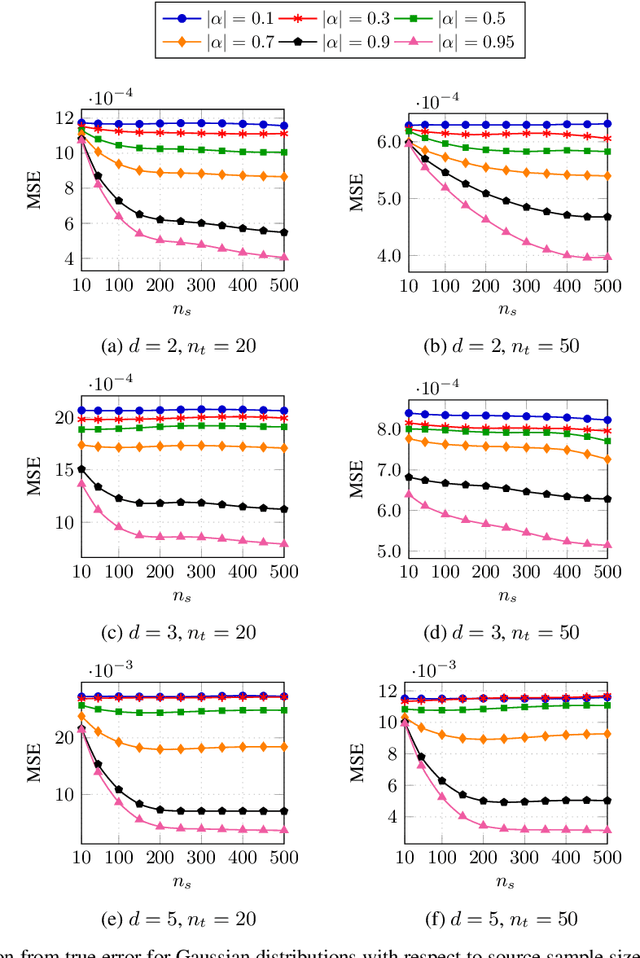
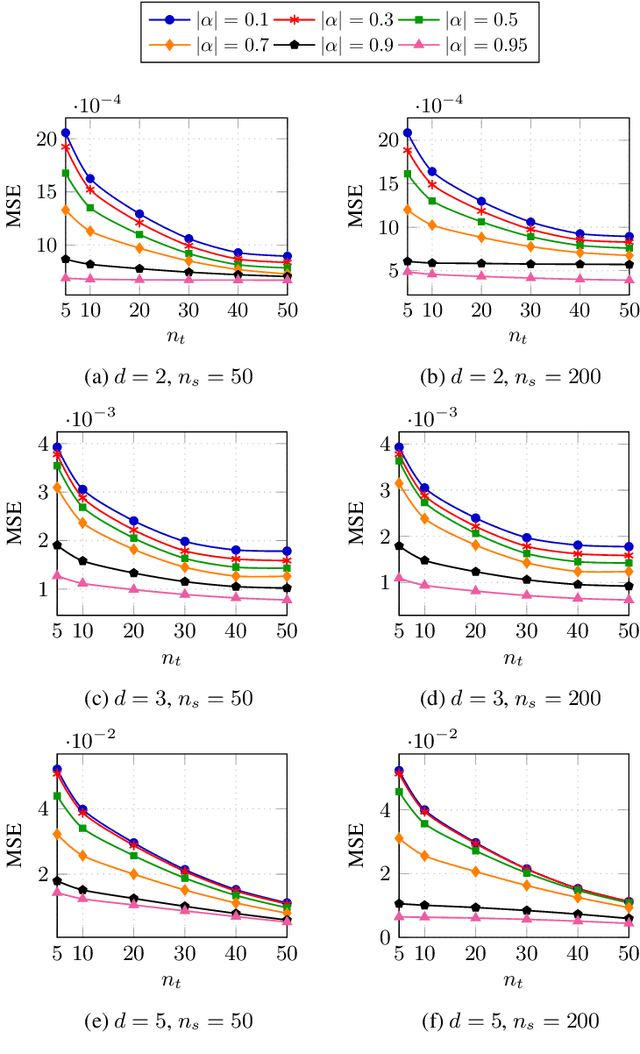
Classification has been a major task for building intelligent systems as it enables decision-making under uncertainty. Classifier design aims at building models from training data for representing feature-label distributions--either explicitly or implicitly. In many scientific or clinical settings, training data are typically limited, which makes designing accurate classifiers and evaluating their classification error extremely challenging. While transfer learning (TL) can alleviate this issue by incorporating data from relevant source domains to improve learning in a different target domain, it has received little attention for performance assessment, notably in error estimation. In this paper, we fill this gap by investigating knowledge transferability in the context of classification error estimation within a Bayesian paradigm. We introduce a novel class of Bayesian minimum mean-square error (MMSE) estimators for optimal Bayesian transfer learning (OBTL), which enables rigorous evaluation of classification error under uncertainty in a small-sample setting. Using Monte Carlo importance sampling, we employ the proposed estimator to evaluate the classification accuracy of a broad family of classifiers that span diverse learning capabilities. Experimental results based on both synthetic data as well as real-world RNA sequencing (RNA-seq) data show that our proposed OBTL error estimation scheme clearly outperforms standard error estimators, especially in a small-sample setting, by tapping into the data from other relevant domains.
SimCD: Simultaneous Clustering and Differential expression analysis for single-cell transcriptomic data
Apr 04, 2021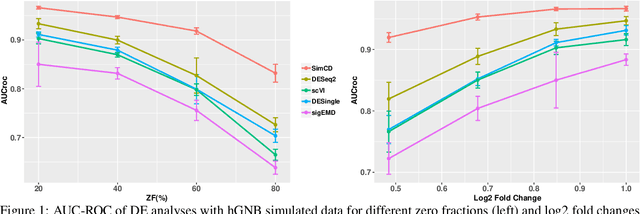
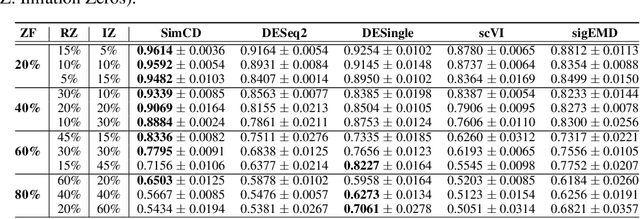
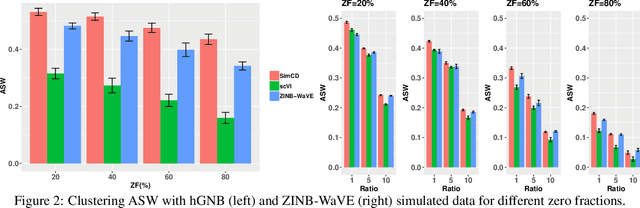

Single-Cell RNA sequencing (scRNA-seq) measurements have facilitated genome-scale transcriptomic profiling of individual cells, with the hope of deconvolving cellular dynamic changes in corresponding cell sub-populations to better understand molecular mechanisms of different development processes. Several scRNA-seq analysis methods have been proposed to first identify cell sub-populations by clustering and then separately perform differential expression analysis to understand gene expression changes. Their corresponding statistical models and inference algorithms are often designed disjointly. We develop a new method -- SimCD -- that explicitly models cell heterogeneity and dynamic differential changes in one unified hierarchical gamma-negative binomial (hGNB) model, allowing simultaneous cell clustering and differential expression analysis for scRNA-seq data. Our method naturally defines cell heterogeneity by dynamic expression changes, which is expected to help achieve better performances on the two tasks compared to the existing methods that perform them separately. In addition, SimCD better models dropout (zero inflation) in scRNA-seq data by both cell- and gene-level factors and obviates the need for sophisticated pre-processing steps such as normalization, thanks to the direct modeling of scRNA-seq count data by the rigorous hGNB model with an efficient Gibbs sampling inference algorithm. Extensive comparisons with the state-of-the-art methods on both simulated and real-world scRNA-seq count data demonstrate the capability of SimCD to discover cell clusters and capture dynamic expression changes. Furthermore, SimCD helps identify several known genes affected by food deprivation in hypothalamic neuron cell subtypes as well as some new potential markers, suggesting the capability of SimCD for bio-marker discovery.
Geometric Affinity Propagation for Clustering with Network Knowledge
Mar 26, 2021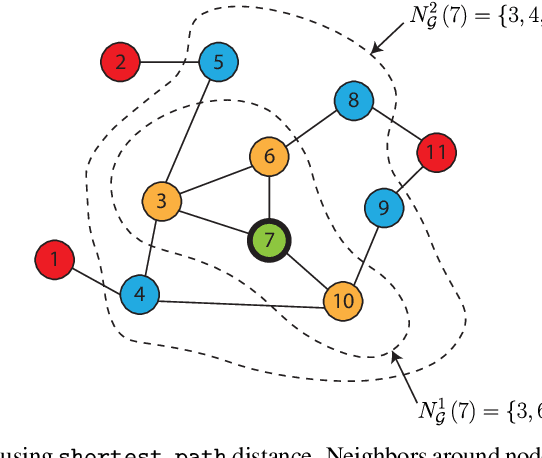
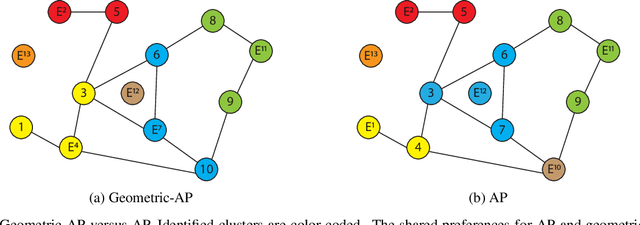
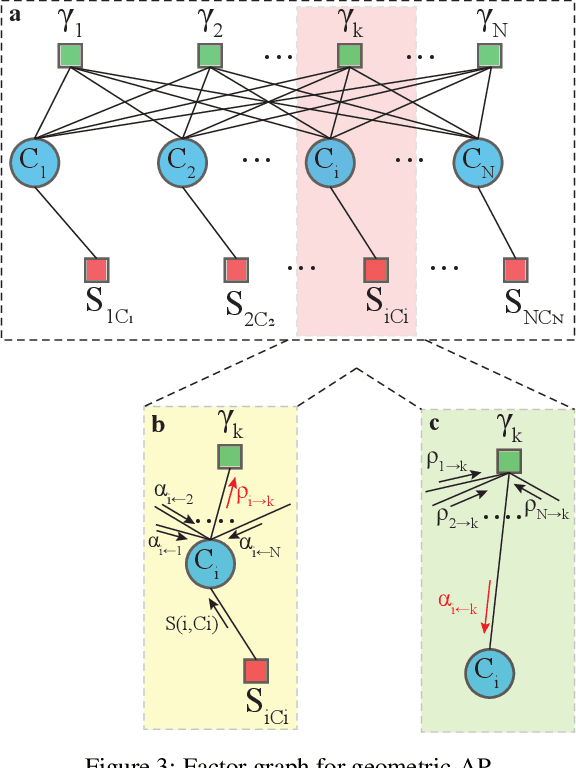
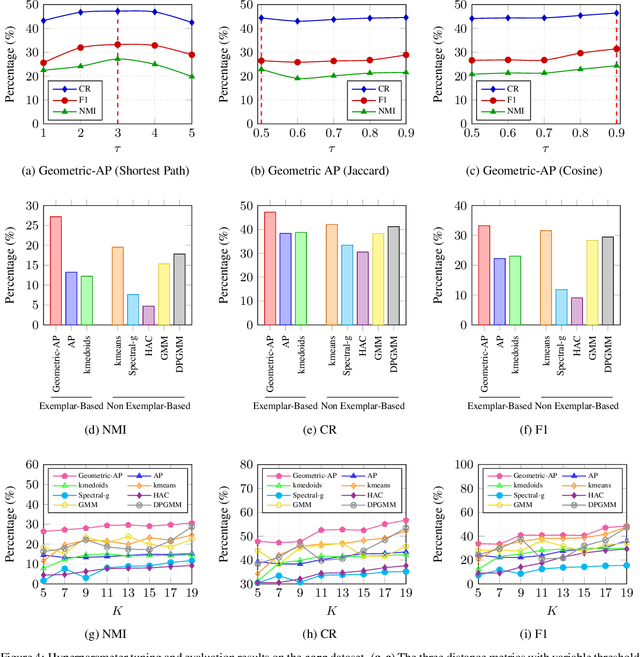
Clustering data into meaningful subsets is a major task in scientific data analysis. To date, various strategies ranging from model-based approaches to data-driven schemes, have been devised for efficient and accurate clustering. One important class of clustering methods that is of a particular interest is the class of exemplar-based approaches. This interest primarily stems from the amount of compressed information encoded in these exemplars that effectively reflect the major characteristics of the respective clusters. Affinity propagation (AP) has proven to be a powerful exemplar-based approach that refines the set of optimal exemplars by iterative pairwise message updates. However, a critical limitation is its inability to capitalize on known networked relations between data points often available for various scientific datasets. To mitigate this shortcoming, we propose geometric-AP, a novel clustering algorithm that effectively extends AP to take advantage of the network topology. Geometric-AP obeys network constraints and uses max-sum belief propagation to leverage the available network topology for generating smooth clusters over the network. Extensive performance assessment reveals a significant enhancement in the quality of the clustering results when compared to benchmark clustering schemes. Especially, we demonstrate that geometric-AP performs extremely well even in cases where the original AP fails drastically.
Contextual Dropout: An Efficient Sample-Dependent Dropout Module
Mar 06, 2021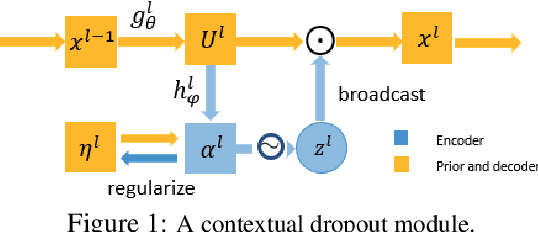
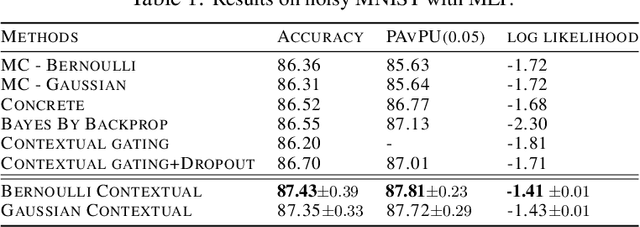
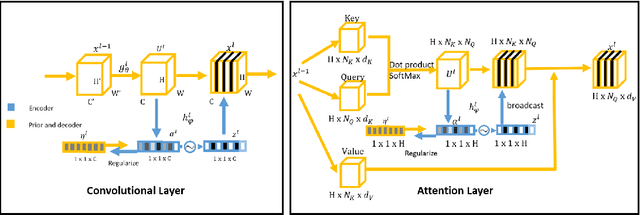
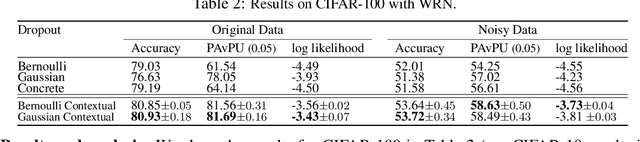
Dropout has been demonstrated as a simple and effective module to not only regularize the training process of deep neural networks, but also provide the uncertainty estimation for prediction. However, the quality of uncertainty estimation is highly dependent on the dropout probabilities. Most current models use the same dropout distributions across all data samples due to its simplicity. Despite the potential gains in the flexibility of modeling uncertainty, sample-dependent dropout, on the other hand, is less explored as it often encounters scalability issues or involves non-trivial model changes. In this paper, we propose contextual dropout with an efficient structural design as a simple and scalable sample-dependent dropout module, which can be applied to a wide range of models at the expense of only slightly increased memory and computational cost. We learn the dropout probabilities with a variational objective, compatible with both Bernoulli dropout and Gaussian dropout. We apply the contextual dropout module to various models with applications to image classification and visual question answering and demonstrate the scalability of the method with large-scale datasets, such as ImageNet and VQA 2.0. Our experimental results show that the proposed method outperforms baseline methods in terms of both accuracy and quality of uncertainty estimation.
BayReL: Bayesian Relational Learning for Multi-omics Data Integration
Oct 22, 2020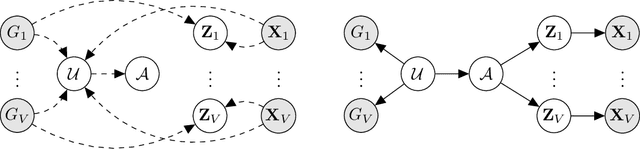
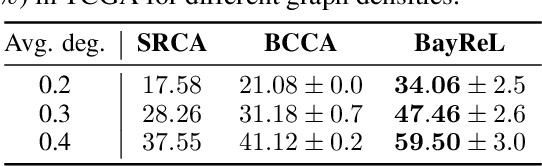
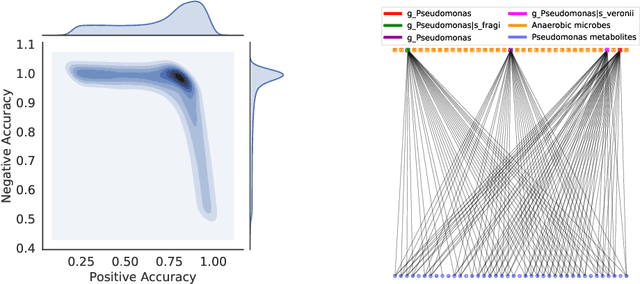

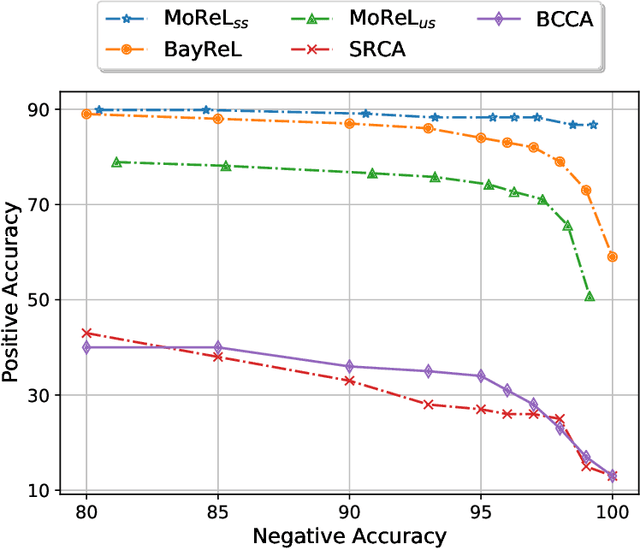
High-throughput molecular profiling technologies have produced high-dimensional multi-omics data, enabling systematic understanding of living systems at the genome scale. Studying molecular interactions across different data types helps reveal signal transduction mechanisms across different classes of molecules. In this paper, we develop a novel Bayesian representation learning method that infers the relational interactions across multi-omics data types. Our method, Bayesian Relational Learning (BayReL) for multi-omics data integration, takes advantage of a priori known relationships among the same class of molecules, modeled as a graph at each corresponding view, to learn view-specific latent variables as well as a multi-partite graph that encodes the interactions across views. Our experiments on several real-world datasets demonstrate enhanced performance of BayReL in inferring meaningful interactions compared to existing baselines.
Quantifying the multi-objective cost of uncertainty
Oct 07, 2020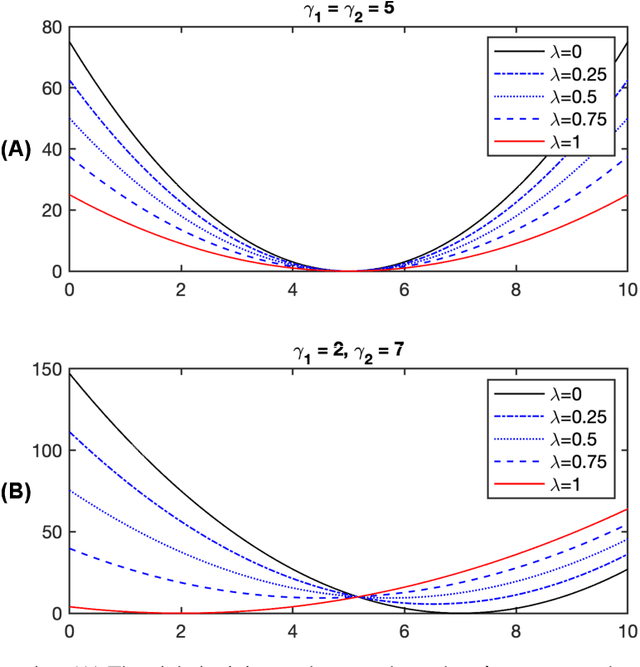
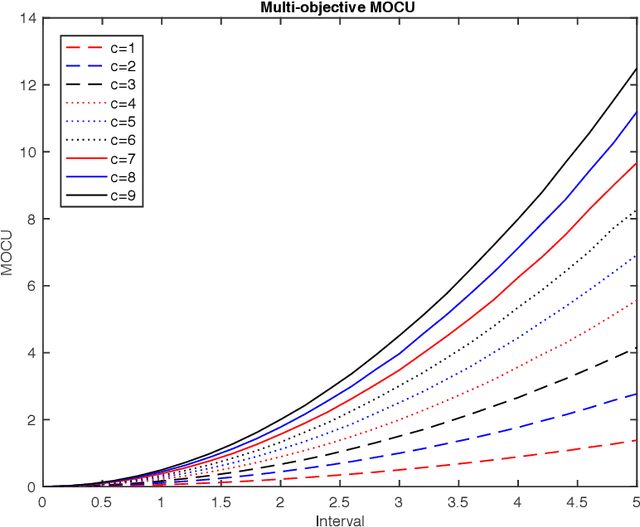
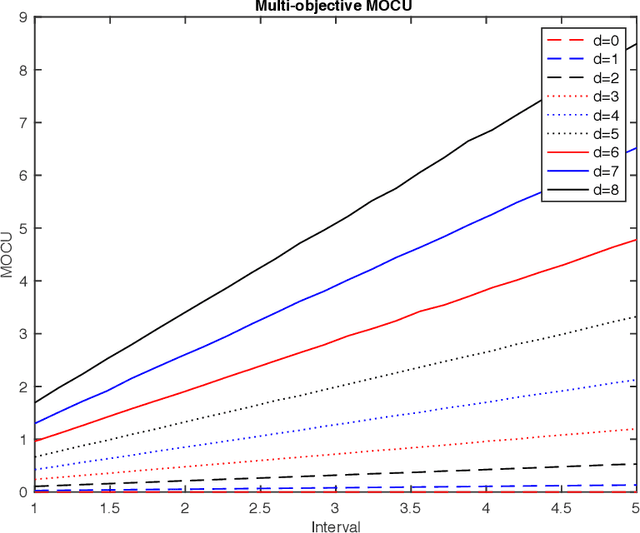
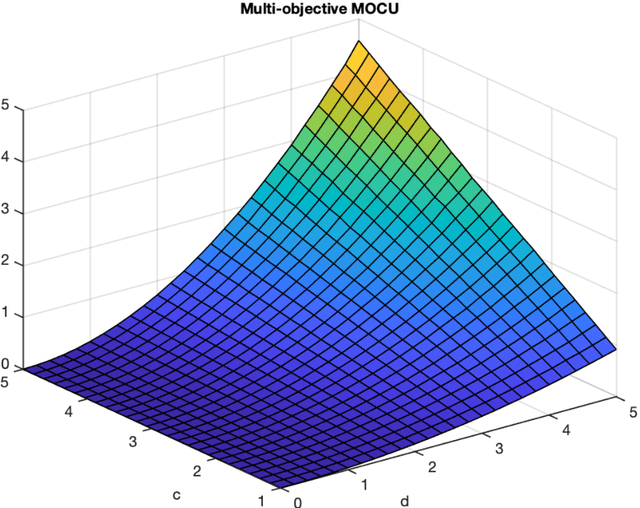
Various real-world applications involve modeling complex systems with immense uncertainty and optimizing multiple objectives based on the uncertain model. Quantifying the impact of the model uncertainty on the given operational objectives is critical for designing optimal experiments that can most effectively reduce the uncertainty that affect the objectives pertinent to the application at hand. In this paper, we propose the concept of mean multi-objective cost of uncertainty (multi-objective MOCU) that can be used for objective-based quantification of uncertainty for complex uncertain systems considering multiple operational objectives. We provide several illustrative examples that demonstrate the concept and strengths of the proposed multi-objective MOCU.