 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKNPTC: Knowledge and Neural Machine Translation Powered Chinese Pinyin Typo Correction
May 02, 2018
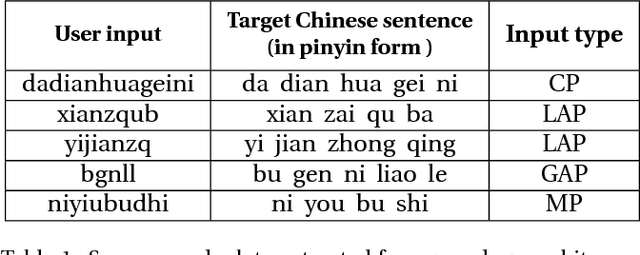
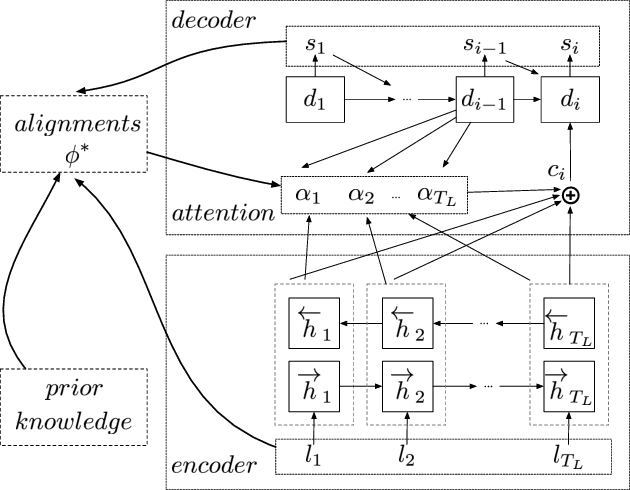
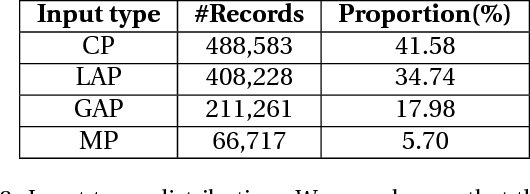
Chinese pinyin input methods are very important for Chinese language processing. Actually, users may make typos inevitably when they input pinyin. Moreover, pinyin typo correction has become an increasingly important task with the popularity of smartphones and the mobile Internet. How to exploit the knowledge of users typing behaviors and support the typo correction for acronym pinyin remains a challenging problem. To tackle these challenges, we propose KNPTC, a novel approach based on neural machine translation (NMT). In contrast to previous work, KNPTC is able to integrate explicit knowledge into NMT for pinyin typo correction, and is able to learn to correct a variety of typos without the guidance of manually selected constraints or languagespecific features. In this approach, we first obtain the transition probabilities between adjacent letters based on large-scale real-life datasets. Then, we construct the "ground-truth" alignments of training sentence pairs by utilizing these probabilities. Furthermore, these alignments are integrated into NMT to capture sensible pinyin typo correction patterns. KNPTC is applied to correct typos in real-life datasets, which achieves 32.77% increment on average in accuracy rate of typo correction compared against the state-of-the-art system.