 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Entity Disambiguation and the Role of Popularity in Retrieval-Based NLP
Jun 12, 2021
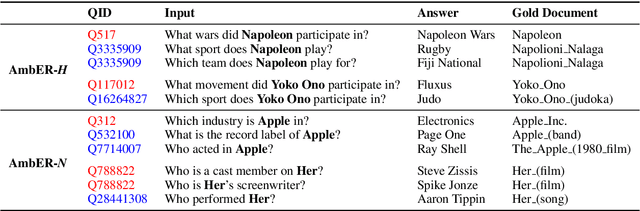
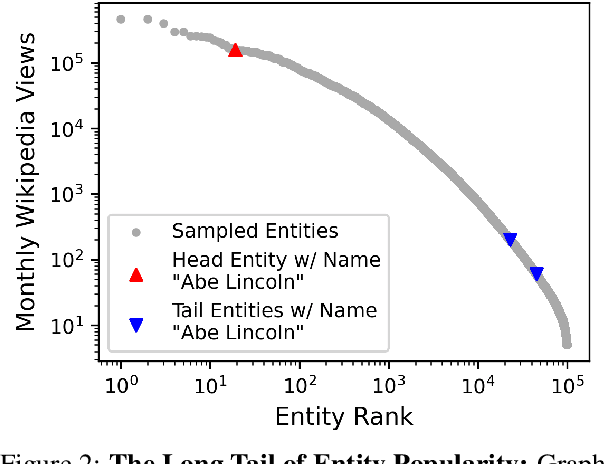

Retrieval is a core component for open-domain NLP tasks. In open-domain tasks, multiple entities can share a name, making disambiguation an inherent yet under-explored problem. We propose an evaluation benchmark for assessing the entity disambiguation capabilities of these retrievers, which we call Ambiguous Entity Retrieval (AmbER) sets. We define an AmbER set as a collection of entities that share a name along with queries about those entities. By covering the set of entities for polysemous names, AmbER sets act as a challenging test of entity disambiguation. We create AmbER sets for three popular open-domain tasks: fact checking, slot filling, and question answering, and evaluate a diverse set of retrievers. We find that the retrievers exhibit popularity bias, significantly under-performing on rarer entities that share a name, e.g., they are twice as likely to retrieve erroneous documents on queries for the less popular entity under the same name. These experiments on AmbER sets show their utility as an evaluation tool and highlight the weaknesses of popular retrieval systems.
Bootleg: Chasing the Tail with Self-Supervised Named Entity Disambiguation
Oct 23, 2020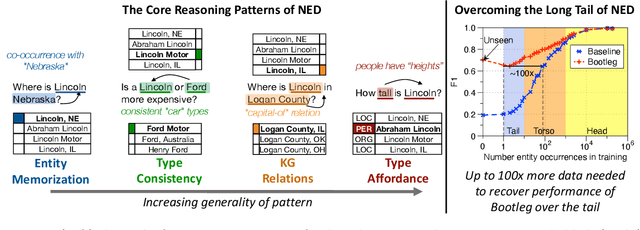
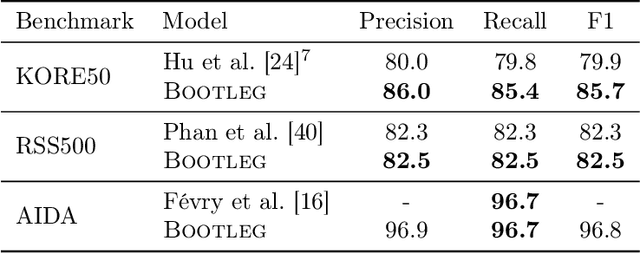
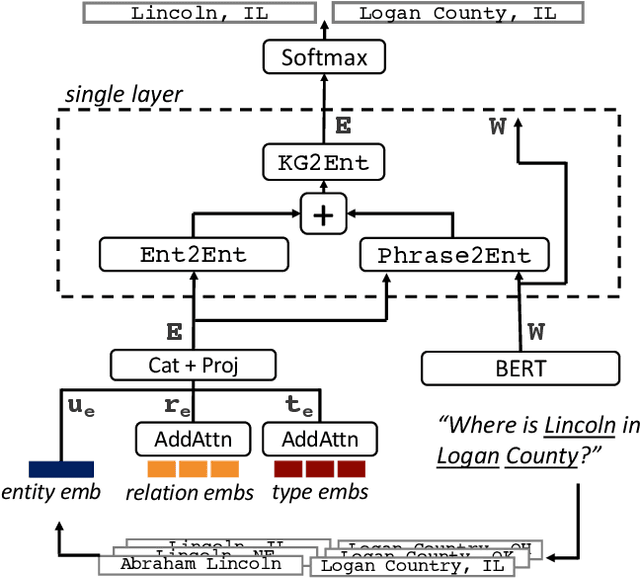
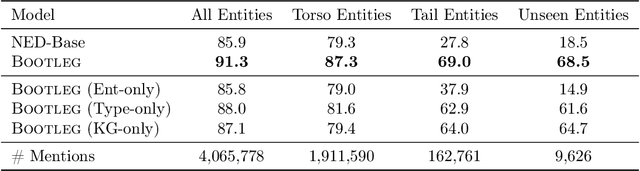
A challenge for named entity disambiguation (NED), the task of mapping textual mentions to entities in a knowledge base, is how to disambiguate entities that appear rarely in the training data, termed tail entities. Humans use subtle reasoning patterns based on knowledge of entity facts, relations, and types to disambiguate unfamiliar entities. Inspired by these patterns, we introduce Bootleg, a self-supervised NED system that is explicitly grounded in reasoning patterns for disambiguation. We define core reasoning patterns for disambiguation, create a learning procedure to encourage the self-supervised model to learn the patterns, and show how to use weak supervision to enhance the signals in the training data. Encoding the reasoning patterns in a simple Transformer architecture, Bootleg meets or exceeds state-of-the-art on three NED benchmarks. We further show that the learned representations from Bootleg successfully transfer to other non-disambiguation tasks that require entity-based knowledge: we set a new state-of-the-art in the popular TACRED relation extraction task by 1.0 F1 points and demonstrate up to 8% performance lift in highly optimized production search and assistant tasks at a major technology company
Recurrent Attention Unit
Oct 30, 2018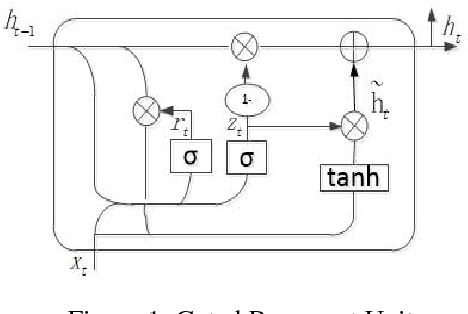
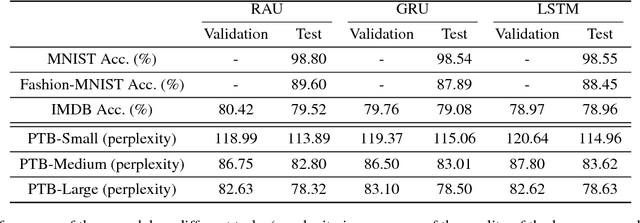
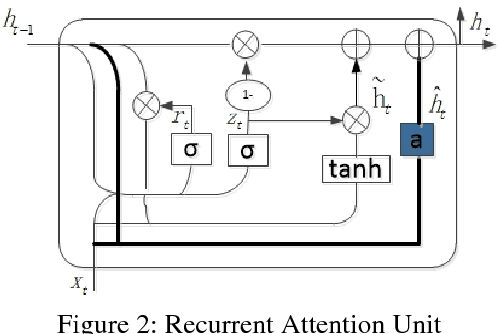
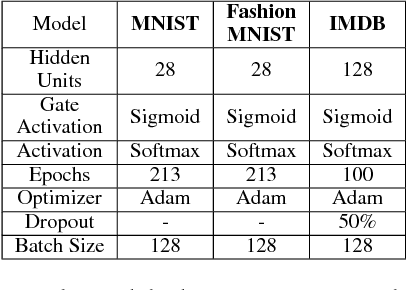
Recurrent Neural Network (RNN) has been successfully applied in many sequence learning problems. Such as handwriting recognition, image description, natural language processing and video motion analysis. After years of development, researchers have improved the internal structure of the RNN and introduced many variants. Among others, Gated Recurrent Unit (GRU) is one of the most widely used RNN model. However, GRU lacks the capability of adaptively paying attention to certain regions or locations, so that it may cause information redundancy or loss during leaning. In this paper, we propose a RNN model, called Recurrent Attention Unit (RAU), which seamlessly integrates the attention mechanism into the interior of GRU by adding an attention gate. The attention gate can enhance GRU's ability to remember long-term memory and help memory cells quickly discard unimportant content. RAU is capable of extracting information from the sequential data by adaptively selecting a sequence of regions or locations and pay more attention to the selected regions during learning. Extensive experiments on image classification, sentiment classification and language modeling show that RAU consistently outperforms GRU and other baseline methods.