 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Fully Formatted End-to-End Speech Recognition with Knowledge Distillation via Multi-Codebook Vector Quantization
Dec 22, 2025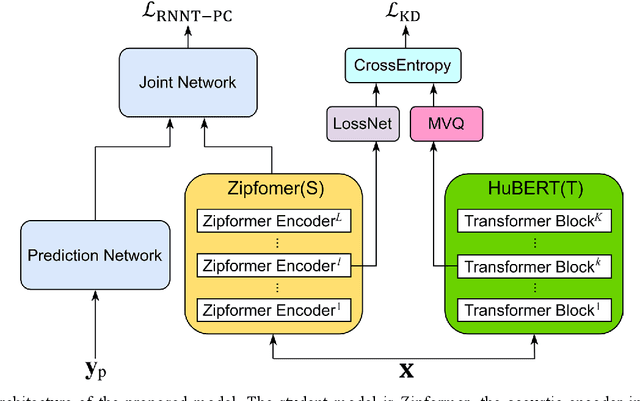
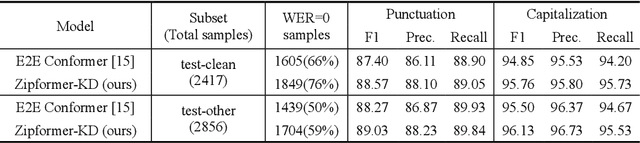
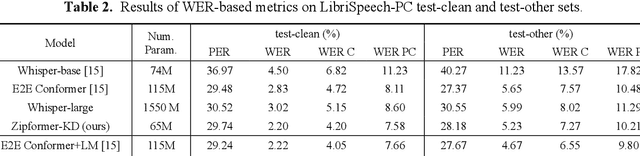
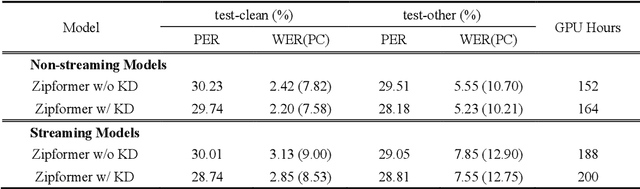
Conventional automatic speech recognition (ASR) models typically produce outputs as normalized texts lacking punctuation and capitalization, necessitating post-processing models to enhance readability. This approach, however, introduces additional complexity and latency due to the cascaded system design. In response to this challenge, there is a growing trend to develop end-to-end (E2E) ASR models capable of directly predicting punctuation and capitalization, though this area remains underexplored. In this paper, we propose an enhanced fully formatted E2E ASR model that leverages knowledge distillation (KD) through multi-codebook vector quantization (MVQ). Experimental results demonstrate that our model significantly outperforms previous works in word error rate (WER) both with and without punctuation and capitalization, and in punctuation error rate (PER). Evaluations on the LibriSpeech-PC test-clean and test-other subsets show that our model achieves state-of-the-art results.
A light-weight and efficient punctuation and word casing prediction model for on-device streaming ASR
Jul 18, 2024Punctuation and word casing prediction are necessary for automatic speech recognition (ASR). With the popularity of on-device end-to-end streaming ASR systems, the on-device punctuation and word casing prediction become a necessity while we found little discussion on this. With the emergence of Transformer, Transformer based models have been explored for this scenario. However, Transformer based models are too large for on-device ASR systems. In this paper, we propose a light-weight and efficient model that jointly predicts punctuation and word casing in real time. The model is based on Convolutional Neural Network (CNN) and Bidirectional Long Short-Term Memory (BiLSTM). Experimental results on the IWSLT2011 test set show that the proposed model obtains 9% relative improvement compared to the best of non-Transformer models on overall F1-score. Compared to the representative of Transformer based models, the proposed model achieves comparable results to the representative model while being only one-fortieth its size and 2.5 times faster in terms of inference time. It is suitable for on-device streaming ASR systems. Our code is publicly available.