 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-guided Machine Translation with Global Video Context
Apr 08, 2026Video-guided Multimodal Translation (VMT) has advanced significantly in recent years. However, most existing methods rely on locally aligned video segments paired one-to-one with subtitles, limiting their ability to capture global narrative context across multiple segments in long videos. To overcome this limitation, we propose a globally video-guided multimodal translation framework that leverages a pretrained semantic encoder and vector database-based subtitle retrieval to construct a context set of video segments closely related to the target subtitle semantics. An attention mechanism is employed to focus on highly relevant visual content, while preserving the remaining video features to retain broader contextual information. Furthermore, we design a region-aware cross-modal attention mechanism to enhance semantic alignment during translation. Experiments on a large-scale documentary translation dataset demonstrate that our method significantly outperforms baseline models, highlighting its effectiveness in long-video scenarios.
Multimodal Neural Machine Translation with Search Engine Based Image Retrieval
Jul 26, 2022
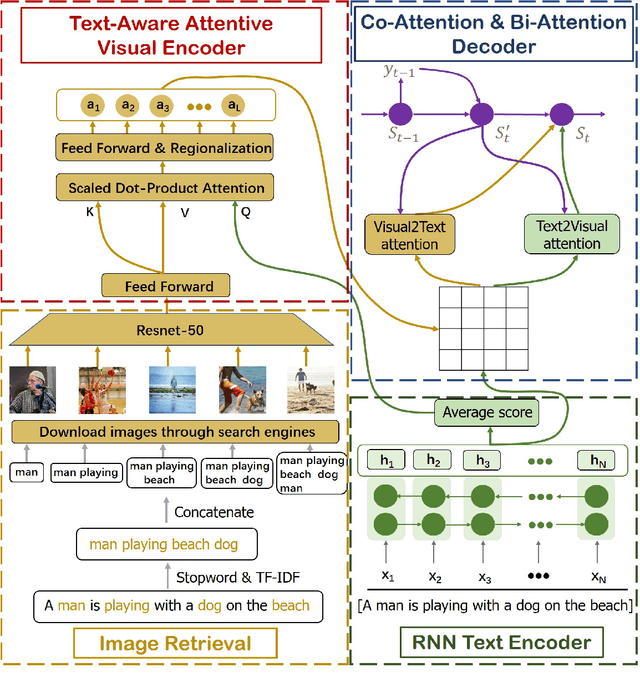
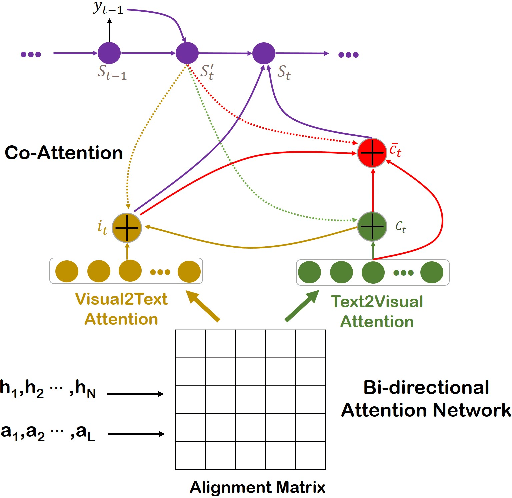
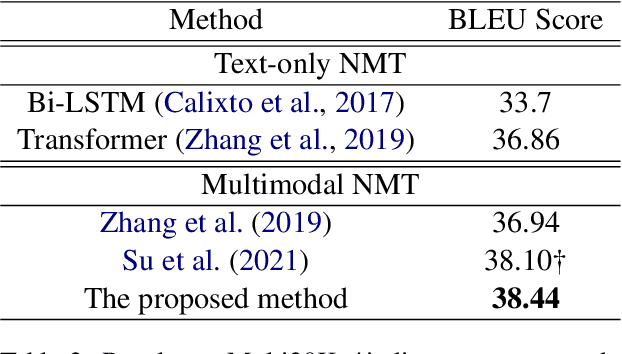
Recently, numbers of works shows that the performance of neural machine translation (NMT) can be improved to a certain extent with using visual information. However, most of these conclusions are drawn from the analysis of experimental results based on a limited set of bilingual sentence-image pairs, such as Multi30K. In these kinds of datasets, the content of one bilingual parallel sentence pair must be well represented by a manually annotated image, which is different with the actual translation situation. Some previous works are proposed to addressed the problem by retrieving images from exiting sentence-image pairs with topic model. However, because of the limited collection of sentence-image pairs they used, their image retrieval method is difficult to deal with the out-of-vocabulary words, and can hardly prove that visual information enhance NMT rather than the co-occurrence of images and sentences. In this paper, we propose an open-vocabulary image retrieval methods to collect descriptive images for bilingual parallel corpus using image search engine. Next, we propose text-aware attentive visual encoder to filter incorrectly collected noise images. Experiment results on Multi30K and other two translation datasets show that our proposed method achieves significant improvements over strong baselines.