 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXavier Bost
Systèmes du LIA à DEFT'13
Feb 21, 2017
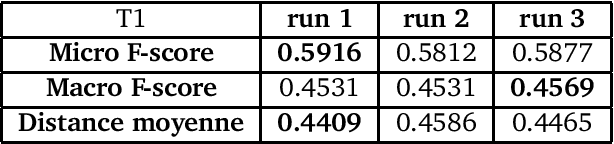


The 2013 D\'efi de Fouille de Textes (DEFT) campaign is interested in two types of language analysis tasks, the document classification and the information extraction in the specialized domain of cuisine recipes. We present the systems that the LIA has used in DEFT 2013. Our systems show interesting results, even though the complexity of the proposed tasks.
* 12 pages, 3 tables, (Paper in French)
How to merge three different methods for information filtering ?
Oct 26, 2015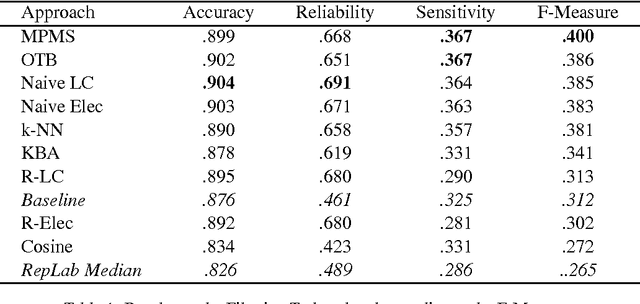
Twitter is now a gold marketing tool for entities concerned with online reputation. To automatically monitor online reputation of entities , systems have to deal with ambiguous entity names, polarity detection and topic detection. We propose three approaches to tackle the first issue: monitoring Twitter in order to find relevant tweets about a given entity. Evaluated within the framework of the RepLab-2013 Filtering task, each of them has been shown competitive with state-of-the-art approaches. Mainly we investigate on how much merging strategies may impact performances on a filtering task according to the evaluation measure.