 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort Text Topic Modeling Techniques, Applications, and Performance: A Survey
Apr 13, 2019
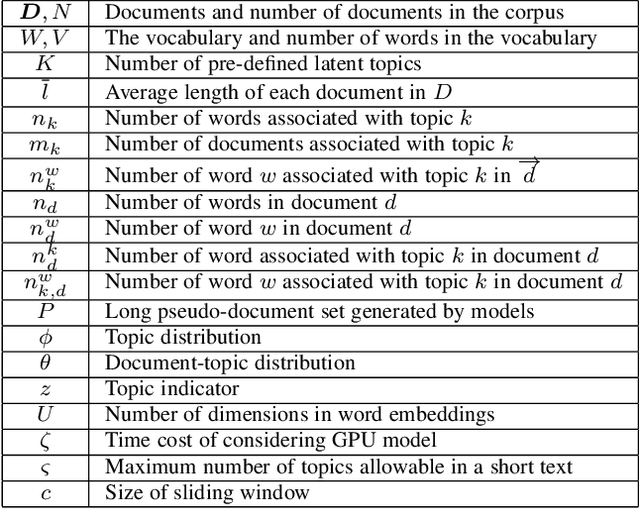
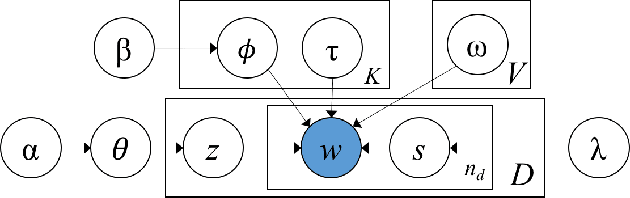
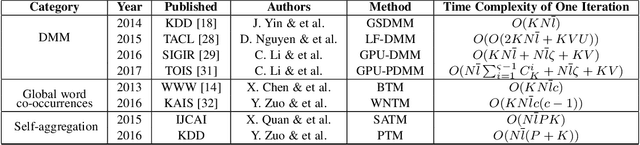
Analyzing short texts infers discriminative and coherent latent topics that is a critical and fundamental task since many real-world applications require semantic understanding of short texts. Traditional long text topic modeling algorithms (e.g., PLSA and LDA) based on word co-occurrences cannot solve this problem very well since only very limited word co-occurrence information is available in short texts. Therefore, short text topic modeling has already attracted much attention from the machine learning research community in recent years, which aims at overcoming the problem of sparseness in short texts. In this survey, we conduct a comprehensive review of various short text topic modeling techniques proposed in the literature. We present three categories of methods based on Dirichlet multinomial mixture, global word co-occurrences, and self-aggregation, with example of representative approaches in each category and analysis of their performance on various tasks. We develop the first comprehensive open-source library, called STTM, for use in Java that integrates all surveyed algorithms within a unified interface, benchmark datasets, to facilitate the expansion of new methods in this research field. Finally, we evaluate these state-of-the-art methods on many real-world datasets and compare their performance against one another and versus long text topic modeling algorithm.
Online Group Feature Selection
Oct 23, 2014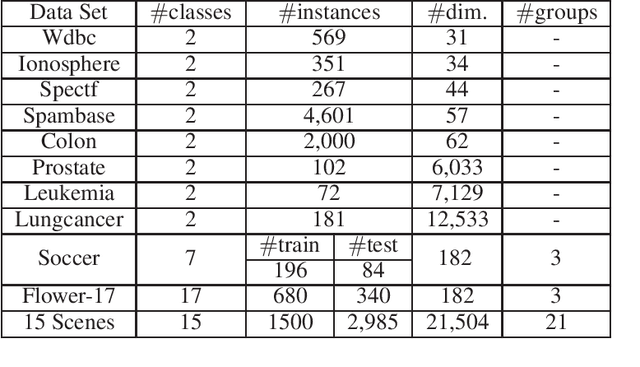
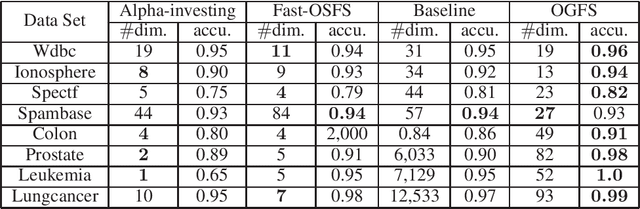
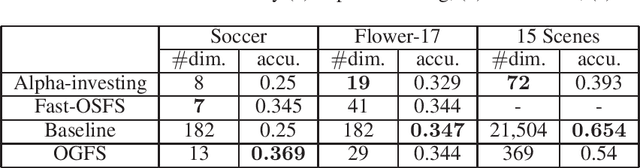
Online feature selection with dynamic features has become an active research area in recent years. However, in some real-world applications such as image analysis and email spam filtering, features may arrive by groups. Existing online feature selection methods evaluate features individually, while existing group feature selection methods cannot handle online processing. Motivated by this, we formulate the online group feature selection problem, and propose a novel selection approach for this problem. Our proposed approach consists of two stages: online intra-group selection and online inter-group selection. In the intra-group selection, we use spectral analysis to select discriminative features in each group when it arrives. In the inter-group selection, we use Lasso to select a globally optimal subset of features. This 2-stage procedure continues until there are no more features to come or some predefined stopping conditions are met. Extensive experiments conducted on benchmark and real-world data sets demonstrate that our proposed approach outperforms other state-of-the-art online feature selection methods.