 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need Neural Models to Explain Human Judgments of Acceptability?
Oct 09, 2019


Native speakers can judge whether a sentence is an acceptable instance of their language. Acceptability provides a means of evaluating whether computational language models are processing language in a human-like manner. We test the ability of computational language models, simple language features, and word embeddings to predict native English speakers judgments of acceptability on English-language essays written by non-native speakers. We find that much of the sentence acceptability variance can be captured by a combination of features including misspellings, word order, and word similarity (Pearson's r = 0.494). While predictive neural models fit acceptability judgments well (r = 0.527), we find that a 4-gram model with statistical smoothing is just as good (r = 0.528). Thanks to incorporating a count of misspellings, our 4-gram model surpasses both the previous unsupervised state-of-the art (Lau et al., 2015; r = 0.472), and the average non-expert native speaker (r = 0.46). Our results demonstrate that acceptability is well captured by n-gram statistics and simple language features.
Online Group Feature Selection
Oct 23, 2014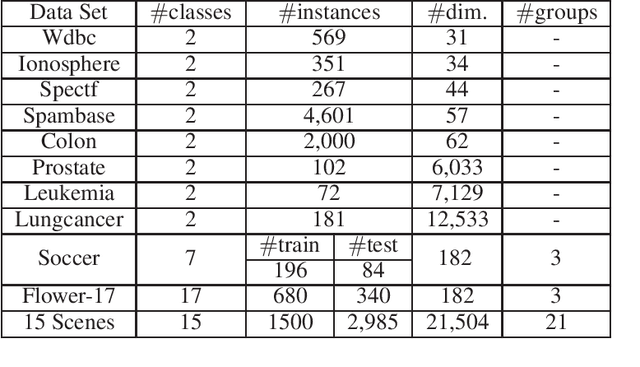
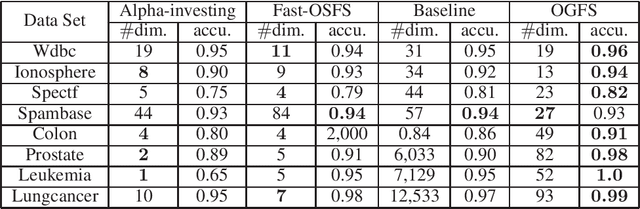
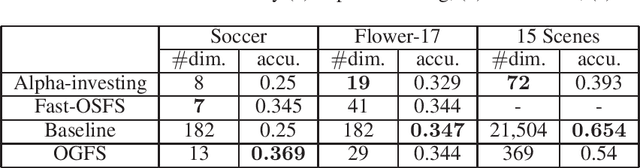
Online feature selection with dynamic features has become an active research area in recent years. However, in some real-world applications such as image analysis and email spam filtering, features may arrive by groups. Existing online feature selection methods evaluate features individually, while existing group feature selection methods cannot handle online processing. Motivated by this, we formulate the online group feature selection problem, and propose a novel selection approach for this problem. Our proposed approach consists of two stages: online intra-group selection and online inter-group selection. In the intra-group selection, we use spectral analysis to select discriminative features in each group when it arrives. In the inter-group selection, we use Lasso to select a globally optimal subset of features. This 2-stage procedure continues until there are no more features to come or some predefined stopping conditions are met. Extensive experiments conducted on benchmark and real-world data sets demonstrate that our proposed approach outperforms other state-of-the-art online feature selection methods.