 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
Jun 18, 2026Agent benchmarks are growing fast, but no single benchmark touches more than four or five of the dimensions that deployment exposes. This paper aggregates the largest coordinated deep-dive of one MCP-based industrial-agent benchmark to date: fourteen parallel implementation studies covering new asset classes (including a multi-modal visual extension), alternative orchestrations, retrieval strategies, reasoning modes, infrastructure optimizations, and evaluation-methodology probes. Consolidating those studies with seven prior agent benchmarks, we argue that aggregate-score leaderboards systematically underspecify deployed-agent evaluation. Rankings derived from aggregate scores do not transfer to out-of-distribution settings; recent public-to-hidden competition retrospectives provide direct empirical evidence of this rank instability. We propose ranking configurations by predictive validity, the correlation between in-sample and out-of-sample rank, rather than in-sample mean, and report a twelve-tier measurement apparatus that exposes the deployment-relevant dimensions HELM and its agent-era successors collapse. The position is operationalized through three falsifiable out-of-distribution criteria with explicit thresholds; existing evidence partly supports it but is too thin to confirm. We close with a pre-registered pilot design and a field-level vision for what the next generation of agentic benchmarks should report.
Goal-Directed Story Generation: Augmenting Generative Language Models with Reinforcement Learning
Dec 16, 2021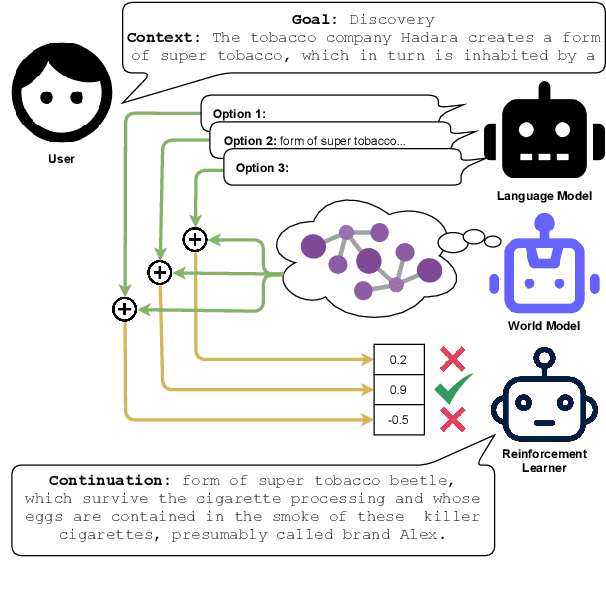
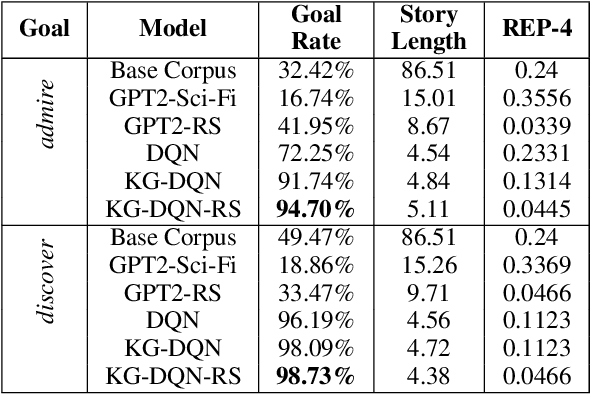

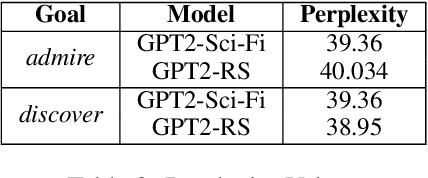
The advent of large pre-trained generative language models has provided a common framework for AI story generation via sampling the model to create sequences that continue the story. However, sampling alone is insufficient for story generation. In particular, it is hard to direct a language model to create stories to reach a specific goal event. We present two automated techniques grounded in deep reinforcement learning and reward shaping to control the plot of computer-generated stories. The first utilizes proximal policy optimization to fine-tune an existing transformer-based language model to generate text continuations but also be goal-seeking. The second extracts a knowledge graph from the unfolding story, which is used by a policy network with graph attention to select a candidate continuation generated by a language model. We report on automated metrics pertaining to how often stories achieve a given goal event as well as human participant rankings of coherence and overall story quality compared to baselines and ablations.